crowdsourcing big data_industry_jun-25-2015_for_slideshare
TRANSCRIPT

FCPCCS - Big Data and Crowdsourcing
Pattern-recognition and the crowd

FCPCCS - Big Data and Crowdsourcing
What would you do with unlimited human analysts?

FCPCCS - Big Data and Crowdsourcing

FCPCCS - Big Data and Crowdsourcing
People
DataCategories

FCPCCS - Big Data and Crowdsourcing
People
DataCategories
Models

FCPCCS - Big Data and Crowdsourcing

FCPCCS - Big Data and Crowdsourcing

FCPCCS - Big Data and Crowdsourcing
Unstructured data gets structured (bonus: a system that gets smarter over time)
Adaptive System
Machine Learning
Optimization
Human Annotation
Prediction Engine
Structured Data Reports
Action

FCPCCS - Big Data and Crowdsourcing
News Category 4
News Category 2
News Category 1
Manufacturing
Health Sciences
0% 20% 40% 60% 80% 100%
80%
85%
99%
83%
81%
88%
87%
90%
73%
91%
Finding Relevant News Articles
% analyst time saved% accuracy (compared to humans)
Efficiency of human time is a major benefit

FCPCCS - Big Data and Crowdsourcing

FCPCCS - Big Data and Crowdsourcing

FCPCCS - Big Data and Crowdsourcing
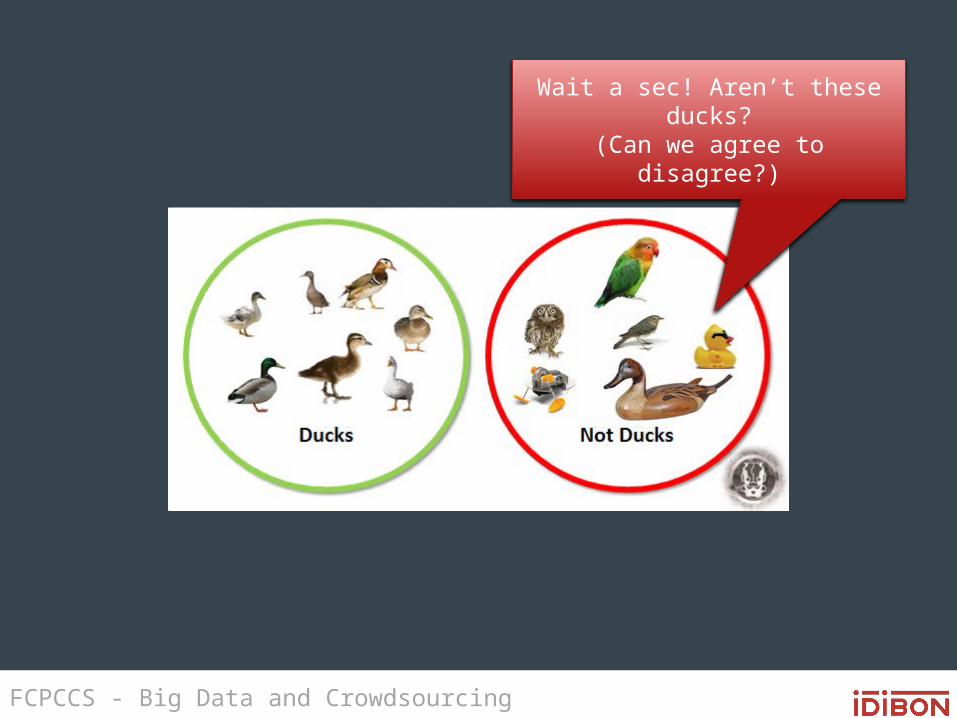
The importance of definition
• If people can’t agree on what’s-in and what’s-out, it’s hard to train a machine

FCPCCS - Big Data and Crowdsourcing
FCPCCS - Big Data and Crowdsourcing
Wait a sec! Aren’t these ducks?(Can we agree to disagree?)

FCPCCS - Big Data and Crowdsourcing
The importance of definition
• If people can’t agree on what’s-in and what’s-out, it’s hard to train a machine
• In our case toxicity was defined as:• ad hominem attacks (directed at specific people)• bigoted comments (e.g., sexist, racist, homophobic, etc)
• Set definitions• Then see if people are consistent • Run pilots• Do inter-annotator agreement• Iterate

FCPCCS - Big Data and Crowdsourcing
Inter-annotator agreement: is everyone measuring the same way?

FCPCCS - Big Data and Crowdsourcing
Quick recommendation for inter-annotator agreement• You can measure consistency, probably the best way is
Krippendorff’s alpha• Don’t use percentage agreement! Particularly when data are
skewed towards one category.• If 95% of the data fall under one category label, then random
coding would still have two people agree so much that % agreement would make you think you had a reliable study (even though you wouldn’t)
• And you can ALSO use models to check these things

FCPCCS - Big Data and Crowdsourcing
Finding healthy communities (supportive)

FCPCCS - Big Data and Crowdsourcing
And unhealthy ones (toxic)

FCPCCS - Big Data and Crowdsourcing
FCPCCS - Big Data and Crowdsourcing
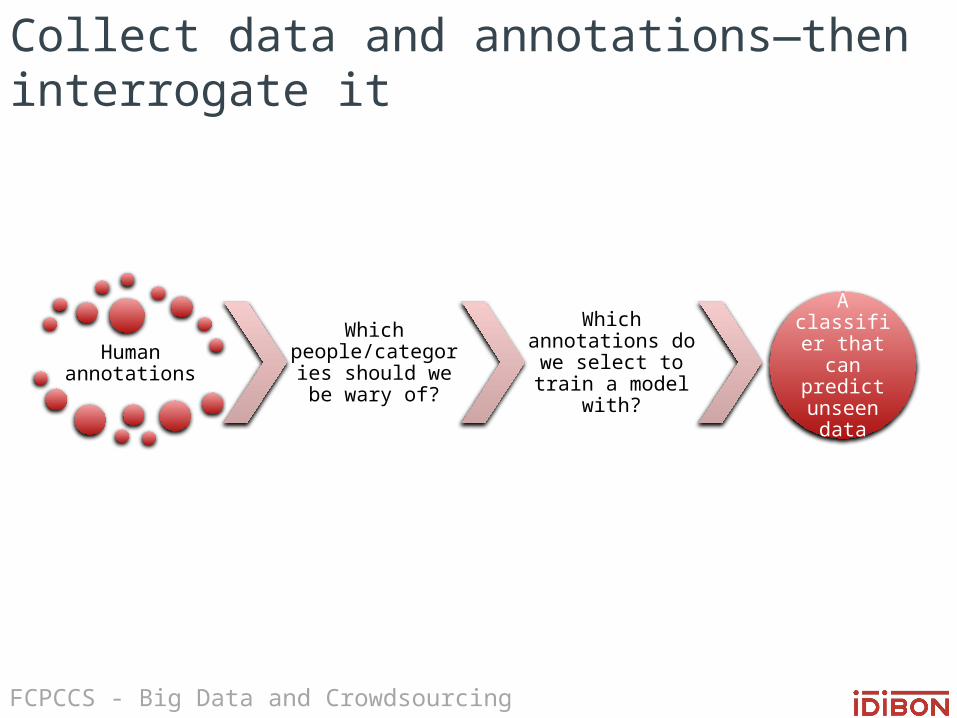
Collect data and annotations—then interrogate it
Human annotations
Which people/categories should we be wary
of?
Which annotations do we select to train
a model with?
A classifier that can predict
unseen data

FCPCCS - Big Data and Crowdsourcing
Routing messages that matter

FCPCCS - Big Data and Crowdsourcing
Processing millions of SMS in 12 African languages
Intent of sender(i.e. report a problem, ask
a question or make a suggestion)
Categorization(i.e. orphans and
vulnerable children, violence against children,
health, nutrition)
Language detection(i.e. English, Acholi,
Karamojong, Luganda, Nkole, Swahili, Lango)
Location(i.e. village names)

FCPCCS - Big Data and Crowdsourcing

FCPCCS - Big Data and Crowdsourcing
1.4%

FCPCCS - Big Data and Crowdsourcing

FCPCCS - Big Data and Crowdsourcing
Top 3 categories in Nigeria
Employment
U-report support
Health
9.69%
17.68%
39.44%

FCPCCS - Big Data and Crowdsourcing
The Donald Rumsfeld Question

FCPCCS - Big Data and Crowdsourcing
How do I find what I don’t know I don’t know?

FCPCCS - Big Data and Crowdsourcing
Negative topics in Walmart employee reviews
Hours/Benefits
968
518
Management
2,404Work/life balance
1,241
Company Values Dealing With Customers
658
Training & Expectation
968
Low Pay
1,446

FCPCCS - Big Data and Crowdsourcing
Common Pros among Employees
Common Cons among Employees
Good co-w
orkers
Fits m
y sch
edule
Pay/opportu
nities0%
10%
20%
30%
40%
50%
37%
25% 24%
41%
27%
17%
Current Former
Management
raining/E
xpecta
tions
Low Pay
Work/
Life Balance
0%
10%
20%
30%24%
16%13% 13%14%
16%
12%
CurrentFormer
Structuring unstructured data lets you combine it with other metadata

FCPCCS - Big Data and Crowdsourcing
Question: What improves models the most?

FCPCCS - Big Data and Crowdsourcing
Instead of worrying about the algorithms in the machine

FCPCCS - Big Data and Crowdsourcing
It’s almost always better to just get more pandas

FCPCCS - Big Data and Crowdsourcing
How else do you verify?
We assess model accuracy using cross-validation. Instead of using all annotated data to train a model, you hold out a
random 10% and build the model with the rest. Then you predict against that 10%. You do this 10 times and
average the accuracy. Precision measures “if we automatically label something as
X, how often are we right?” Recall measures “how much of stuff that SHOULD have label
X are actually given label X?”

FCPCCS - Big Data and Crowdsourcing
The system gets smarter
Here’s what happens going across the first 2,543 annotations on one REALLY low signal classification task
By 9,744 annotations, our accuracy is 97%

FCPCCS - Big Data and Crowdsourcing
Other tasks are more straight-forward
50 100 150 2000.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
F-scores go up with more annotations
Disease
Country
Reported_deaths
Reported_cases
Date
Number of paragraphs annotated
F-sc
ore
IssueLocationPeople affected# of deathsEvent date
FCPCCS - Big Data and Crowdsourcing
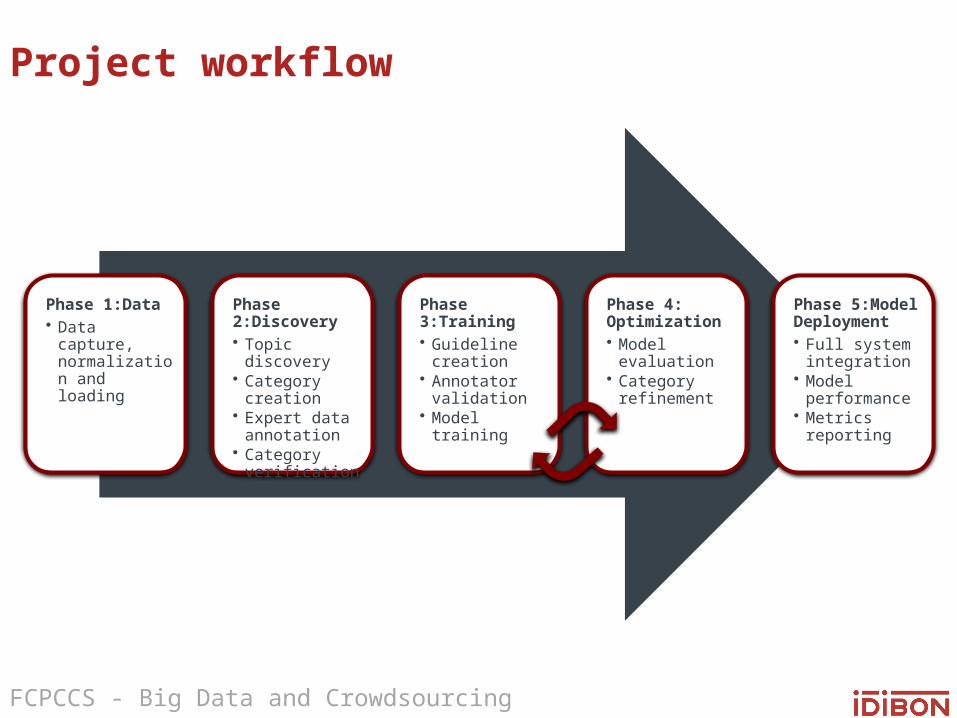
Project workflow
Phase 1:Data• Data capture,
normalization and loading
Phase 2:Discovery• Topic discovery• Category creation• Expert data
annotation• Category
verification
Phase 3:Training• Guideline creation• Annotator
validation• Model training
Phase 4: Optimization• Model evaluation• Category
refinement
Phase 5:Model Deployment• Full system
integration• Model
performance• Metrics reporting
