非线性多重约束的内部评级违约概率模型的 ...€¦ · 80...
TRANSCRIPT

78 非线性多重约束的内部评级违约概率模型的设计研究 总第 35 期
非线性多重约束的内部评级违约概率模型的设计研究
李海涛 1
摘要:2014 年 4 月,经银监会核准,国内 6 家银行实施资本计量高级方法,其显著特色
是过渡期后利用内部评级初级法下违约概率结果计量风险加权资产和监管资本。目前关于违约
概率估计的研究大都存在未能严格遵循监管要求建立识别违约样本的标准,未能建立包括校准
环节等在内的完整内部评级模型开发框架,以及未能将专家的业务经验纳入模型设计等方面的
不足。鉴此,本文建立了一个满足监管合规要求的模型开发框架,设计了一个非线性多重约束
的内部评级违约概率模型,并引入分类器原理评估模型的可靠性。基于某银行业务数据的实证
研究表明,该模型效果良好。
关键词:新资本协议;内部评级;违约概率模型;资本计量高级法
一、引言
2012 年 6 月,中国银监会正式发布了《商业银行资本管理办法(试行)》(以下简称《办
法》),要求商业银行建立内部资本计量、配置和经风险调整资本收益的评价管理体系,并将风险、
收益和资本统一协调的意识和理念融入经营管理中,实现商业银行资本集约化的转型。《办法》
明确了经银监会新资本协议合规评估通过的商业银行,可利用内部评级法计量信用风险加权资
产及资本充足率。信用风险内部评级法实施的价值在于:将内部评级法应用于授信审批、风险
偏好制定、风险限额、贷款定价、资产分类以及绩效考核等领域,能实现商业银行风险管理水
平的精细化提升;同时,相比较权重法“一刀切”的方式,基于内部评级法计量的风险加权资
产水平可反映商业银行的非预期风险损失特征信息,能促使银行建立风险和资本互相反馈的机
制,有利于实现内涵式持续增长。
为规范商业银行新资本协议的实施,中国银监会于 2012 年 9 月发布了《商业银行实施资
本管理高级方法监管暂行细则》,明确了申请成为新资本协议合规银行的条件、监管机构的评
1李海涛,经济学博士,恒丰银行总行风险计量中心,新资本协议项目实施办公室。作者感谢匿名审稿
人意见,文责自负。

792014 年第 11 期
审原则等内容。2013 年 8 月,银监会又发布了包括《关于商业银行实施内部评级法的补充监
管要求》等在内的 4 个资本监管配套政策文件,要求商业银行应审慎估计违约概率、违约损失率、
违约风险暴露和期限等风险参数。目前,中国工商银行、中国建设银行、中国农业银行、中国
银行、中国交通银行以及招商银行等 6 家银行在经历了多轮监管机构的评估检查后,于 2014
年 4 月被核准进入实施资本管理高级方法的过渡期。应该说,在监管当局的积极推动下,国内
银行机构已将建立内部评级违约概率模型以及实施新资本协议,作为积极应对利率市场化带来
的市场分化和释放新监管标准实施后造成的银行再融资压力的最佳选择路径。
梳理国内外关于商业银行信用风险评估的研究文献,发现相关研究在模型构建中存在以下
不足:未能严格遵循监管要求建立界定违约样本的标准,未能建立包括校准环节在内的、完整
的内部评级模型开发框架,以及未能将专家的经验纳入模型结构中。为此,笔者结合模型开发
和新资本协议合规经验,建立了一个能满足监管合规要求的模型开发框架,设计了可纳入业务
专家经验的非线性多重约束内部评级违约概率模型,并基于某银行的业务数据进行了实证研究。
二、研究现状和不足
国内外研究文献基本上运用多元判别分析(Multivariate Discriminant Analysis Model,
MDA)、Logit/Probit 回归、神经网络、支持向量机等模型,对公司样本的信用风险进行评估或预测。
Altman(1968) 首次运用多元判别分析方法,构建了 Z 值模型对经配对的财务困境公司样本
和正常公司样本进行了预测。随后 Altman,Haldeman 和 Narayanan(1977) 对 Z 值模型进行了
修正,建立了 ZETA 模型。鉴于 MDA 存在诸多苛刻假设,例如总体数据服从联合正态分布、
组内方差和协方差矩阵恒等, Ohlson(1980)将 Logit 模型运用到公司财务困境预测中,结果
表明,公司规模、财务结构、经营绩效和流动性等是导致公司陷入财务困境的显著影响因素;
Tirapat 和 Nittayagasetwat(1999) 以及 Jones 和 Hensher(2004) 相继运用 Logit 模型开展过类似的
研究;此外,Zmijewski(1984)、Theodossiou(1991) 则分别使用 Probit 模型对公司样本的财务
困境进行了预测。伴着人工神经网络技术的兴起,Odom 和 Sharda(1990)、Koh 和 Tan(1999)、
Atiya(2001) 将人工神经网络模型也运用到财务困境预测。
国内研究与国外研究遵循了基本相同的路径。张玲(2000)将 120 家上市公司分为训练样
本和测试样本,构建了 MDA 模型,对样本陷入财务困境的可能性进行了预测,结果表明,模
型具有超前 4 年的预测效果。于立勇等(2004)利用某国有商业银行中同一行业且资产规模大
致相当的实际信贷交易数据为样本集,利用逐步判别分析和 Bayes 模型对样本的违约概率进行
了测算。吴世农等(2001)采用样本配对方式,运用 Logit 模型对 70 家 ST 上市公司和 70 家

80 非线性多重约束的内部评级违约概率模型的设计研究 总第 35 期
正常公司的财务困境进行了预测,结果为:Logit 模型的预测准确率高于 MDA 和线性概率模
型。管七海(2004)针对制造业的短期贷款企业,进行了分规模和分地区样本的多元判别分析
模型、Logit 模型与神经网络模型等的构建与实证探索,识别出了影响我国制造业企业违约的
关键变量,构建了最佳违约判别模型。黄善东等 (2007)、卢永艳 (2012)、谢赤等(2014)同样
利用 Logit 模型对公司陷入财务困境的概率进行了预测。吕长江等(2004)、杨淑娥等(2005)、
秦小丽等(2011)运用神经网络或改善后的神经网络,对公司财务困境进行了预测。陈诗一(2008)
利用 SVC 方法预测了德国公司的违约概率。
结合商业银行内部评级模型监管合规要求,以上研究存在如下不足:
一是尚未严格按照《办法》中的违约定义要求,界定违约样本和正常样本,而是多以上市
公司是否被特别处理来定义好坏样本。
二是尚未建立规范、合规的内部评级模型开发框架。相关研究普遍缺少模型校准环节,因
而得出的违约概率多为不能满足监管要求的、“不真实”的违约概率。
三是未能将授信业务人员的经验纳入模型结构中,因而模型存在不合理性,且不能满足新
资本协议的监管合规要求。原因在于,内部评级模型结果能够有效应用到商业银行的业务实践
是顺利通过合规验收的必要条件之一,而模型结果能够有效应用的前提是,应尽量包含银行业
务专家在授信审批过程中关注的财务信息;此外,通过提炼业务专家经验,并将其以业务约束
的方式纳入模型设计环节,有利于增强模型的稳健性,一定程度上可以消除因银行积累的数据
质量较差带来的“模型噪声”;再有,作为模型使用者的业务人员广泛参与模型开发过程,也
有助于加强其对模型结构和精神的理解,便于模型上线后的推广和应用。
三、非线性多重约束的违约概率模型设计
根据监管合规要求,实施内部评级初级法商业银行的模型开发框架如图 1 所示。
1. 2. 3. 4. 5. 6.
图 1:内部评级违约概率模型开发框架
图 1 中,数据采集、清洗和整理的主要内容包括采集模型的自变量和因变量数据等。前者
主要指银行业务系统中积累的财务报表数据(资产负债表、利润损益表、现金流量表及其附注);
后者指所标示出的是否违约的数据。《办法》中给出了法人客户层面的违约定义。

812014 年第 11 期
违约标识是指根据违约定义,对建模样本打上是否违约的标志。数据转换的目的在于消
除原始数据中包含的“噪音”,以确保变量的稳健性。不同于主流文献中的数据转换方式,为
使变量凝聚丰富的违约信息,引入了适应能力强和稳健性较高的局部非参数曲线拟合(Loess)
方法,它可在每一自变量值处拟合一个零阶、一阶或二阶的局部多项式。单变量分析是指对自
变量的集合进行筛选,以确定进入多变量分析环节的变量。
多变量分析是指基于自变量集合,运用一定方法估计模型结构和自变量系数。由于具有“黑
匣子”特征的神经网络技术无法查验自变量系符号指向是否符合银行业务实践以及存在泛化能
力较差等问题,因此,国内实施内部评级法的商业银行在进行定量财务模型开发时基本上全部
以 Logit 或 Probit 模型进行违约概率的估计。两者的主要区别为 Logit 模型比 Probit 模型曲线
的尾部厚。但在样本中没有太多极端观测值的情况下,该差异不会造成实际应用的重大差别。
鉴于此,本文以 Probit 模型对模型系数进行估计和实现结果输出。考虑到内部评级模型的主要
目的是实现授信客户的风险排序,因此,以模型结果的区分能力最大为目标,同时将业务专家
的行业审批经验和统计检验要求以约束方式纳入,构建了非线性多重约束的违约概率结构模型,
形式如下。
目标:模型区分能力最优
约束:① 固定某个或组合财务比率
② L1 ≤分组 1 ≤ U1
L2 ≤分组 2 ≤ U1
…… (1)
Ln ≤分组 n ≤ Un
③ L ≤模型变量总数≤ U
④ 模型统计检验满足设定标准,且 HLP_value>0.5
⑤ 系数权重分布满足业务实践要求
式(1)中,区分能力一般用准确率 AR 系数和 KS 衡量,Li (i=1~n) 为变量组进入模型的
变量个数下限,Ui(i=1~n) 为变量组进入模型的变量个数上限,L 为模型自变量总数下限,U 为
模型自变量总数上限。AR 的计算公式为:
AR=2×AUC–1 (2)
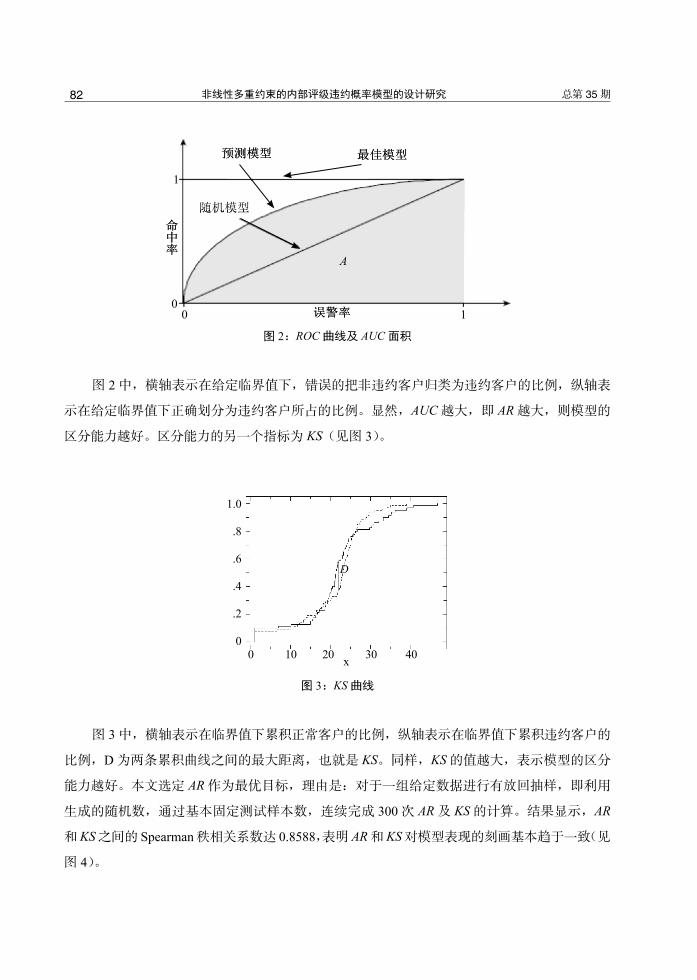
式(2)中,AUC 为 ROC 曲线下的面积,如图 2 所示(图中阴影部分为 AUC 面积)1。
1关于 AR 和 KS 以及下文二项检验的详细分析参见《商业银行资本计量高级方法验证指引(第二次征求
意见稿)》。
82 非线性多重约束的内部评级违约概率模型的设计研究 总第 35 期
A
00
1
1
图 2:ROC 曲线及 AUC 面积
图 2 中,横轴表示在给定临界值下,错误的把非违约客户归类为违约客户的比例,纵轴表
示在给定临界值下正确划分为违约客户所占的比例。显然,AUC 越大,即 AR 越大,则模型的
区分能力越好。区分能力的另一个指标为 KS(见图 3)。
1.0
.8
.6
.4
.2
0
D
0 10 20 30 40x
图 3:KS 曲线
图 3 中,横轴表示在临界值下累积正常客户的比例,纵轴表示在临界值下累积违约客户的
比例,D 为两条累积曲线之间的最大距离,也就是 KS。同样,KS 的值越大,表示模型的区分
能力越好。本文选定 AR 作为最优目标,理由是:对于一组给定数据进行有放回抽样,即利用
生成的随机数,通过基本固定测试样本数,连续完成 300 次 AR 及 KS 的计算。结果显示,AR
和 KS 之间的 Spearman 秩相关系数达 0.8588,表明 AR 和 KS 对模型表现的刻画基本趋于一致(见
图 4)。

832014 年第 11 期
1.20000000
1.00000000
0.80000000
0.60000000
0.40000000
0.20000000
0.00000000
1 20 39 58 77 96 115
134
153
172
191
210
229
248
267
286
KS
AR
图 4: AR 和 KS 的相关性分析
基于式(1)得到的模型区分能力是 AR 的绝对水平,还应判断该水平的可靠性。为此,
引入 AR 置信区间检验。显然,对于相同的 AR 值,置信区间越小,表明该模型的区分能力越
可靠。由式(2)可知,AR 置信区间可由 AUC 的置信区间计算得到。一种获得置信区间的方
法是 Bootstrapping,核心思想是通过放回抽样,估计每一次抽样结果的 AR 值或 AUC 值。当
放回抽样的次数增加时,其 AR/AUC 的分布趋于稳定,可在此基础上估计其置信区间。但该方
法的缺点在于计算量较大,为了得到稳定的分布,需要进行大批次的放回抽样并估计每次抽样
结果的 AR 值。于是,Delong 等人提出了另外一种比较 AUC 值的非参数统计检验方法:假设
共有 k 种分类器,其中第 r 种分类算法在各个正常样本上的输出等于 miX ri ,...,2,1, = ,在各个违
约样本上的输出等于 njY rj ,...,2,1, = ,则 AUC 值等价于 Mann-Whitney 统计量 ,可以用 rθ̂ 对第
r 个分类器的 AUC 值进行估计:
( )∑∑= =
=n
j
m
i
rj
ri
r YXm n 1 1
,1ˆ ψθ (3)
其中:
( )
>
=
<
=
XY
XY
XY
YX
0211
,ψ
为了更好的结构化表示,定义:
( ) ( ) miYXn
XVn
j
rj
rii
r ,...2,1,11
1 0 == ∑=
ψ ( ) ( ) njYXm
YVm
i
rj
rij
r ,...2,1,11
0 1 == ∑=
ψ (4)

84 非线性多重约束的内部评级违约概率模型的设计研究 总第 35 期
同时定义一个 k×k 的矩阵 S10 和 S01,它们的第 (r,s) 个元素分别等于:
( )[ ] ( )[ ]∑=
−−−
=m
i
si
sri
rsr XVXVm
s1
1 01 0,
1 0ˆˆ
11 θθ (5)
( )[ ] ( )[ ]∑=
−−−
=n
j
sj
srj
rsr YVYVn
s1
0 10 1,
0 1ˆˆ
11 θθ (6)
如此,向量 ( )kθθθθ ˆ,...ˆ,ˆˆ 21= 的协方差矩阵 S 等于:
0 11 011 Sn
Sm
S += (7)
Delong 设计了一个符合标准正态分布的统计量:
2/1
0 11 0 '11''ˆ
+
−
LSn
Sm
L
LL θθ (8)
式(8)中 L 是行向量,对应于不同分类器的系数,因此该统计量可以比较不同模型的
AUC 值是否有显著差异。当只考虑单个模型的 AUC 值时,k=1 且 L=1。根据该统计量我们可
以获得 AUC 的置信区间:
)*ˆ,*ˆ( SzSz αα θθ +−
此外,《办法》明确要求,若商业银行的建模数据未能覆盖一个完整的经济周期,则应对
参数估计结果进行审慎调整,并将其称之为模型校准。本质而言,式(1)模型的原始输出为
样本内的违约概率,而不是样本实际的违约概率,应利用长期中心违约趋势(以下称“CT”)
或总体违约概率,对其进行调整或校准。本文利用贝叶斯条件概率方法完成校准过程,推导如下:
( 1 )( 1| )( )
( 0 )( 0 | )( )
P y ampleP y SampleP Sample
P y ampleP y SampleP Sample
== =
== =
(9)
而:
( 0 ) ( | 0)* ( 0)( 1 ) ( | 1)* ( 1)
P y Sample P Sample y P yP y Sample P Sample y P y
= = = == = = =
且
且 (10)
因此:
( 1) ( | 0) ( 1| )*( 0) ( | 1) ( 0 | )
P y P Sample y P y SampleP y P Sample y P y Sample
= = ==
= = = (11)
式(11)中,P(y=1) 为总体违约率,即 CT;P(y=0) 为总体未违约概率,即 1-CT;P(y=1|
sample) 表示样本违约率,即 PDsample;P(y=0| sample) 表示样本未违约的概率,即 1–P(y=1|
sample),此时式(11)变为:

852014 年第 11 期
(1 ) ( | 0)=(1 ) ( | 1)
( 0)1- ( 0) ·( 1) 1-
( 1)
sample
sample
CT PD P sample yPD CT P sample y
P sample yPD PDP y
P sample y PD PDP y
⋅ − =⋅ − =
=== =
==
(12)
由式(12)可得:
=
1(1 )
·(1 ) 1sample
sample
kPDk
CT PD PDk
PD CT PD
+⋅ −
=⋅ − −
(13)
完成模型校准后,根据《办法》要求,还应将模型结果映射至主标尺,并判断其在主标尺
上的区分能力、准确性和审慎性。可称该过程为模型评估。其中,主标尺是指为区分非零售客
户信用风险,以便于对非零售客户的差别化和精细化管理,以违约概率区间划分信用等级,针
对所有非零售客户建立违约概率和信用等级之间的对应关系。主标尺上每个信用等级一般由违
约概率区间的下限、区间上限、区间代表值组成,信用等级的违约概率以违约概率区间的代表
值表示。其反应了银行处于该等级客户的长期平均违约率,也是最终计算风险加权资产的违约
概率值。鉴于我国银行数据的积累情况,主标尺的等级数目以 12—15 个为宜。准确性和审慎
性的检验指标分别为二项检验的单边和双边检验。
鉴于方法论成熟度、模型表现稳定性以及业务适用性考虑,Probit 模型已成为商业银行开
发内部评级模型的首选。但不可否认的是,任何模型都是存在假设的,也就直接导致了其存在
一定的局限性,Porbit 模型的主要假设为事件发生概率服从累积正态分布。
四、实证研究
下文将以某商业银行的实际运行业务数据为实证数据 , 利用本文设计的模型设计框架 , 完
成对模型的设计、校准和验证评估。需要说明的是,图 1 给出的是单一模型的开发框架,在此
之前,应首先综合权衡银行风险暴露敞口的数据积累、业务发展和内部管理需求等情况来确定
模型开发的数目,称之为模型细分。模型细分时考虑的常见因素包括国标行业或规模等。例如
对于企业法人风险暴露敞口,首先,在规模层面划分为大中和中小两类风险暴露敞口;其次,
在行业层面进一步细分为制造业、批发零售业等模型。因不同细分下模型设计思路类似,仅存
在数据差异,故本文以制造业评级模型为例。
(一)数据采集、清洗和整理
实证数据的时间区间为 2004—2009 年共 6 年数据,满足了《办法》中“用于估计非零售
86 非线性多重约束的内部评级违约概率模型的设计研究 总第 35 期
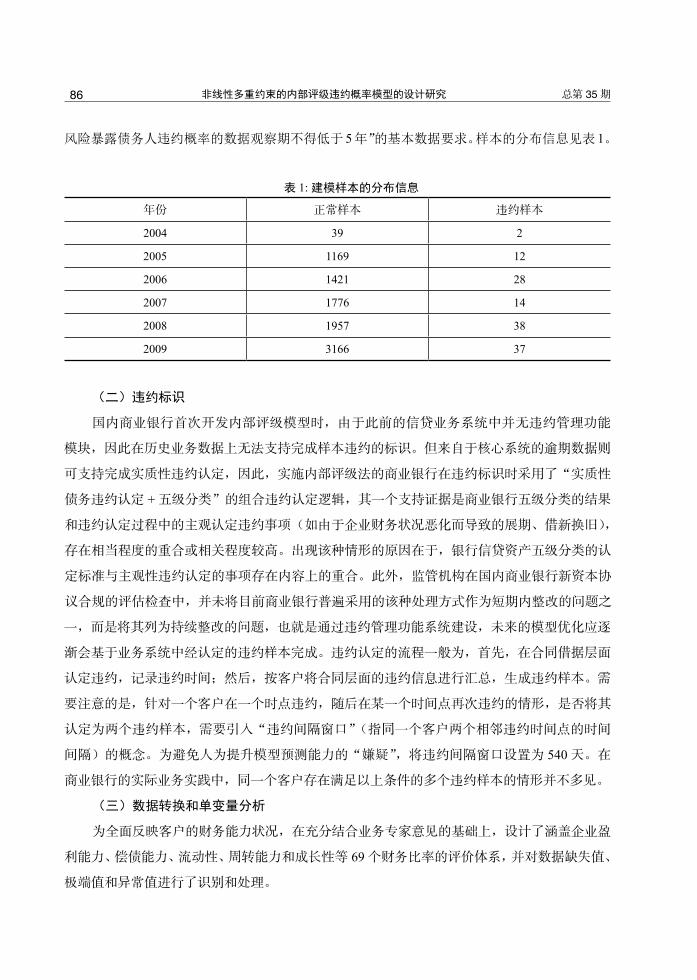
风险暴露债务人违约概率的数据观察期不得低于 5年”的基本数据要求。样本的分布信息见表 1。
表 1: 建模样本的分布信息
年份 正常样本 违约样本
2004 39 2
2005 1169 12
2006 1421 28
2007 1776 14
2008 1957 38
2009 3166 37
(二)违约标识
国内商业银行首次开发内部评级模型时,由于此前的信贷业务系统中并无违约管理功能
模块,因此在历史业务数据上无法支持完成样本违约的标识。但来自于核心系统的逾期数据则
可支持完成实质性违约认定,因此,实施内部评级法的商业银行在违约标识时采用了“实质性
债务违约认定 + 五级分类”的组合违约认定逻辑,其一个支持证据是商业银行五级分类的结果
和违约认定过程中的主观认定违约事项(如由于企业财务状况恶化而导致的展期、借新换旧),
存在相当程度的重合或相关程度较高。出现该种情形的原因在于,银行信贷资产五级分类的认
定标准与主观性违约认定的事项存在内容上的重合。此外,监管机构在国内商业银行新资本协
议合规的评估检查中,并未将目前商业银行普遍采用的该种处理方式作为短期内整改的问题之
一,而是将其列为持续整改的问题,也就是通过违约管理功能系统建设,未来的模型优化应逐
渐会基于业务系统中经认定的违约样本完成。违约认定的流程一般为,首先,在合同借据层面
认定违约,记录违约时间;然后,按客户将合同层面的违约信息进行汇总,生成违约样本。需
要注意的是,针对一个客户在一个时点违约,随后在某一个时间点再次违约的情形,是否将其
认定为两个违约样本,需要引入“违约间隔窗口”(指同一个客户两个相邻违约时间点的时间
间隔)的概念。为避免人为提升模型预测能力的“嫌疑”,将违约间隔窗口设置为 540 天。在
商业银行的实际业务实践中,同一个客户存在满足以上条件的多个违约样本的情形并不多见。
(三)数据转换和单变量分析
为全面反映客户的财务能力状况,在充分结合业务专家意见的基础上,设计了涵盖企业盈
利能力、偿债能力、流动性、周转能力和成长性等 69 个财务比率的评价体系,并对数据缺失值、
极端值和异常值进行了识别和处理。
872014 年第 11 期
利用非参数 Wilcoxon 检验完成了单变量分析,保留了 P 值 <0.1 的 36 个变量。为使进入
模型的变量凝聚丰富的违约信息,利用 Loess 转换分析完成了变量至实际违约率的转换。此外,
为消除变量共线性的影响,利用 Spearman 秩相关系数删除了存在 70% 相关性且区分能力 AR
值较低的变量,结果最终进入模型多变量分析环节的变量个数为 18 个。
(四)模型设计、校准和评估
为明确确定式(1)中的约束条件,征求了具有风险授信审批经验专家的意见,并结合制
造业的风险判断要点,明确了式(1)中的业务约束条件,最终建立的非线性约束模型如下:
目标:模型区分能力最优
约束: ①固定净资产利润率财务指标
② 0 ≤短期偿债能力指标≤ 1 1 ≤长期偿债能力指标≤ 2
0 ≤营运能力指标≤ 2 0 ≤盈利能力指标≤ 2
0 ≤规模指标≤ 1 0 ≤流动性指标≤ 1
0 ≤财务结构指标≤ 2 0 ≤成长性指标≤ 2
③ 5 ≤模型自变量总数≤ 10
④系数通过检验(系数显著性水平为 0.05),且拟合优度检验 HLP_value>0.5
⑤ 5% ≤系数权重占比≤ 40%
(14)
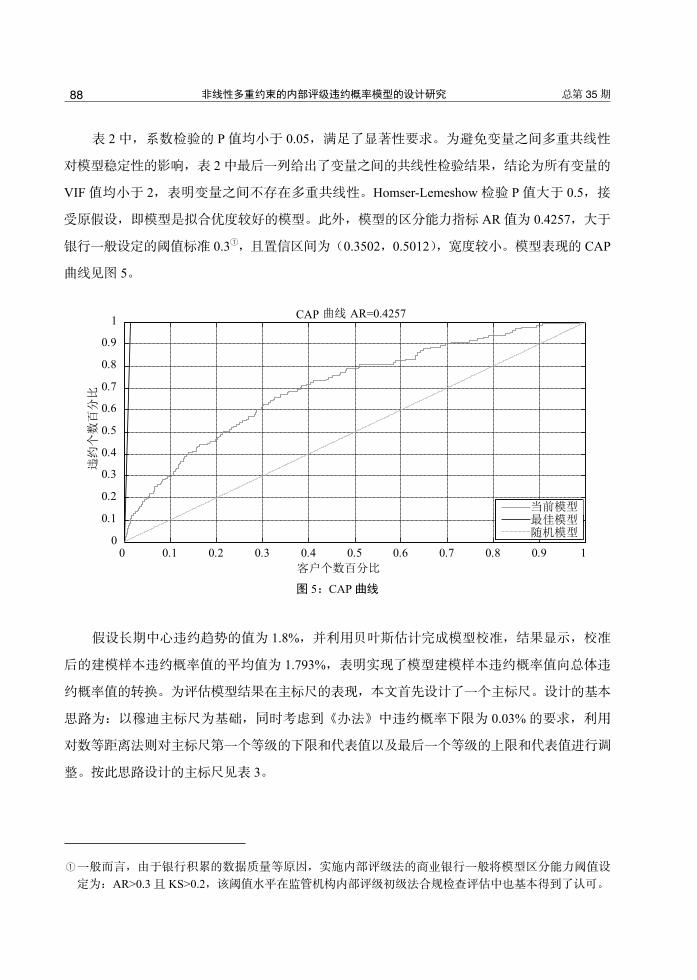
最终,满足式(14)中约束条件的模型和统计检验结果见表 2。
表 2:满足约束条件的模型结构
变量名称 系数 Wald 检验 P 值 VIF 值
常数项 -4.53655 <.0001
主营业务净利率 0.36198 0.0263 1.1162
速动比率 0.16581 0.0463 1.08157
现金利息保障倍数 0.33516 0.0006 1.04349
主营业务收入净额规模 0.3072 0.0049 1.05493
存货与总资产比率 0.2841 0.0078 1.02232
业务费用与存货比率 0.52995 0.0002 1.01595
总资产增长比率 0.24968 0.0002 1.03776
Homser-Lemeshow 检验 P 值 0.8238>0.5
88 非线性多重约束的内部评级违约概率模型的设计研究 总第 35 期
表 2 中,系数检验的 P 值均小于 0.05,满足了显著性要求。为避免变量之间多重共线性
对模型稳定性的影响,表 2 中最后一列给出了变量之间的共线性检验结果,结论为所有变量的
VIF 值均小于 2,表明变量之间不存在多重共线性。Homser-Lemeshow 检验 P 值大于 0.5,接
受原假设,即模型是拟合优度较好的模型。此外,模型的区分能力指标 AR 值为 0.4257,大于
银行一般设定的阈值标准 0.31,且置信区间为(0.3502,0.5012),宽度较小。模型表现的 CAP
曲线见图 5。
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1 CAP AR=0.4257
图 5:CAP 曲线
假设长期中心违约趋势的值为 1.8%,并利用贝叶斯估计完成模型校准,结果显示,校准
后的建模样本违约概率值的平均值为 1.793%,表明实现了模型建模样本违约概率值向总体违
约概率值的转换。为评估模型结果在主标尺的表现,本文首先设计了一个主标尺。设计的基本
思路为:以穆迪主标尺为基础,同时考虑到《办法》中违约概率下限为 0.03% 的要求,利用
对数等距离法则对主标尺第一个等级的下限和代表值以及最后一个等级的上限和代表值进行调
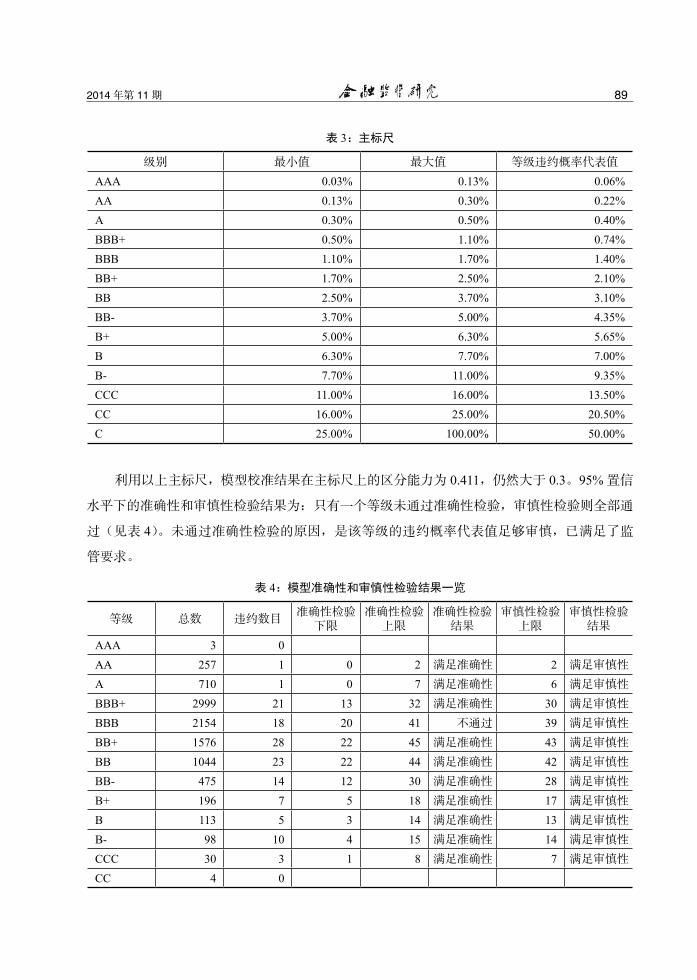
整。按此思路设计的主标尺见表 3。
1一般而言,由于银行积累的数据质量等原因,实施内部评级法的商业银行一般将模型区分能力阈值设
定为:AR>0.3 且 KS>0.2,该阈值水平在监管机构内部评级初级法合规检查评估中也基本得到了认可。
892014 年第 11 期
表 3:主标尺
级别 最小值 最大值 等级违约概率代表值
AAA 0.03% 0.13% 0.06%AA 0.13% 0.30% 0.22%A 0.30% 0.50% 0.40%BBB+ 0.50% 1.10% 0.74%BBB 1.10% 1.70% 1.40%BB+ 1.70% 2.50% 2.10%BB 2.50% 3.70% 3.10%BB- 3.70% 5.00% 4.35%B+ 5.00% 6.30% 5.65%B 6.30% 7.70% 7.00%B- 7.70% 11.00% 9.35%CCC 11.00% 16.00% 13.50%CC 16.00% 25.00% 20.50%C 25.00% 100.00% 50.00%
利用以上主标尺,模型校准结果在主标尺上的区分能力为 0.411,仍然大于 0.3。95% 置信
水平下的准确性和审慎性检验结果为:只有一个等级未通过准确性检验,审慎性检验则全部通
过(见表 4)。未通过准确性检验的原因,是该等级的违约概率代表值足够审慎,已满足了监
管要求。
表 4:模型准确性和审慎性检验结果一览
等级 总数 违约数目准确性检验
下限准确性检验
上限准确性检验
结果审慎性检验
上限审慎性检验
结果
AAA 3 0
AA 257 1 0 2 满足准确性 2 满足审慎性
A 710 1 0 7 满足准确性 6 满足审慎性
BBB+ 2999 21 13 32 满足准确性 30 满足审慎性
BBB 2154 18 20 41 不通过 39 满足审慎性
BB+ 1576 28 22 45 满足准确性 43 满足审慎性
BB 1044 23 22 44 满足准确性 42 满足审慎性
BB- 475 14 12 30 满足准确性 28 满足审慎性
B+ 196 7 5 18 满足准确性 17 满足审慎性
B 113 5 3 14 满足准确性 13 满足审慎性
B- 98 10 4 15 满足准确性 14 满足审慎性
CCC 30 3 1 8 满足准确性 7 满足审慎性
CC 4 0

90 非线性多重约束的内部评级违约概率模型的设计研究 总第 35 期
五、研究结论与建议
本文立足于现有关于商业银行信用风险评估的研究现状,结合模型开发和监管合规要求,
首次设计了一个包括违约样本标识、数据清洗、单变量分析、多变量分析、模型校准和验证评
估等环节在内的模型开发框架。其显著特色是创新设计了基于多重业务约束和统计约束的非线
性违约概率模型。基于银行实际运行业务数据的实证结果表明,模型区分能力绝对水平和鲁棒
性良好,基本全部通过了准确性和审慎性检验,满足了监管阈值要求。
实际上,模型开发是商业银行内部评级管理体系中的基础性工作。商业银行还应建立包括
评级发起、审查、审批和推翻等环节在内的评级生成流程,并深入推动风险参数的业务应用,
坚持“模型开发管理和业务应用管理”两条腿走路,建立模型开发和业务应用不断循环、互相
验证反馈的良好运行机制,不断提升风险管理的精细化管理水平,确保监管资本计量结果能够
充分反映风险水平。风险参数的业务应用,包括核心应用和高级应用两个层次:核心应用范围
包括内部评级结果在授信审批、贷后监控、差异化信贷政策制定等方面的应用;高级应用范围
包括在经济资本计量、贷款定价、贷款损失准备金计提以及基于经风险调整的资本收益率绩效
(RAROC)考核等领域的应用。根据监管合规要求,计划实施新资本协议内部评级初级法的商
业银行,应使风险参数计量结果在核心应用范围得到充分体现,在高级应用范围有所体现。
参考文献
1. 陈诗一,德国违约公司概率预测及其对我国信用风险管理的启示,金融研究,2008 年第 8 期,53-71.
2. 管七海和冯宗宪,我国制造业企业短期贷款信用违约判别研究,经济科学,2004 年第 5 期,77-87。
3. 黄善东和杨淑蛾,公司治理与财务困境预测,预测,2007 年第 2 期,63-67。
4. 李海涛,内部评级模型中的长期中心违约趋势估计研究,财经理论与实践,2014 年第 1 期,15-20。
5. 卢永艳,基于面板数据的上市公司财务困境预测,东北财经大学博士学位论文,2012 年。
6. 吕长江、徐丽莉和周琳,上市公司财务困境与财务破产的比较分析,经济研究,2004 年第 8 期,
64-72。
7. 秦小丽和田高良,基于灰色理论和神经网络的公司财务预警模型,统计与决策,2011 年第 16 期,
176-178。
8. 吴世农和卢贤义,我国上市公司财务困境的预测模型研究,经济研究,2001 年第 6 期,46-55。
9. 谢赤、赵亦军和李为章,基于 CFaR 模型与 Logistic 回归的财务困境预警研究,财经理论与实践,
2014 年第 35 期,57-61。
10. 杨淑娥和黄礼,基于 BP 神经网络的上市公司财务预警模型,系统工程理论与实践,2005 年第 1 期,
12-18。
11. 于立勇,内部评级法中违约概率与违约损失率的测算研究,统计研究,2004 年第 12 期,22-26。

912014 年第 11 期
12. 张玲,财务危机预警分析判别模型及其应用,预测,2000 年第 6 期,38-40。
13. 赵先信,银行内部模型和监管模型,风险计量与资本分配,上海人民出版社,2004 年。
14. 中国银监会,商业银行实施资本管理高级方法监管暂行细则,2012 年。
15. 中国银监会,商业银行资本管理办法,2012 年。
16. Altman, E., Fanancial Ratios, Discriminant Analysis and the Prediction of Corporate Bankruptcy, Journal
of Finance, 1968, Vol.23, 589-609.
17. Altman, E., R. Haldeman, and P. Narayanan, ZETA Analysis: A New Model to Identify Bankruptcy Risk
of Corporations, Journal of Banking and Finance, 1977, Vol.1, 29 -54.
18. Atiya, A., Bankruptcy Prediction for Credit Risk Using Neural Networks: A Survey and New Results, Ieee
Transactions on Neural Networks, 2001, Vol.12, 929-935.
19. Jones, J., and D. Hensher, Predicting Firm Financial Distress: A Mixed Logit Model, The Accounting
Review, 2004, Vol.79, 1011-1038.
20. Koh, H., and S. Tan , A Neural Network Approach to the Prediction of Going Concern Status, Accounting
and Business Reseach, 1999, 29(3), 211-216.
21. Mark, E., Methodological Isuues Related to the Estimation of Financial Distress Prediction Model, Journal
of Accounting (Supplement), 1984, Vol.22, 52-92.
22. Ohlson, J., Financial Ratios: and the Probabilistic Prediction of Bankruptcy, Journal of Accounting
Research, 1980, Vol.18, 109-131.
23. Odom, M., and R. Sharda, A Neural Netwok Model for Bankruptcy Prediction, Ieee Inns Ijcnn, 1990,
Vol.2, 163-168.
24. Sunti, T., A. Aekkachai, An Investigation of Thai Listed Firm'Financial Distress Using Macro and Micro
Variables, Multinational Finance Journal, 1999, Vol.2, 103-125.
25. Theodossiou, P., Alternative Models for Assessing the Financial Condition of Business in Greece, Journal
of Business Finance and Accounting, 1991,18(5), 697-720.
Abstract: Six domestic banks have been approved to implement advanced methods of capital measurement in April 2014, whose significant characteristic is to measure risk-weighted assets and regulatory capital based on the probability of default after the transition period. However, present research findings have some shortcomings, such as failing to identify default samples according to regulatory requirements, failing to establish a development framework (including calibration etc.) of the internal rating model and being incapable of fully bringing banking business experience into the model design. Therefore, the paper establishes a model development framework meeting regulatory compliance requirements, innovates to design a nonlinear multi-constraint internal rating model of default probability, and implements an empirical study with the business data of a bank, and introduces the classification principles to evaluate the model's reliability. Empirical study results show that this model has a good performance.
Keyword: New Capital Accord; Internal Rating; Default Probability; Advanced Method of Capital Measurement
(责任编辑:赵京)