gametheoryfordatascience - morgan claypool publishers · synthesislecturesonartificial...
TRANSCRIPT

GameTheory for Data ScienceEliciting Truthful Information

Synthesis Lectures on ArtificialIntelligence andMachine
LearningEditorsRonald J. Brachman, Jacobs Technion-Cornell Institute at Cornell TechPeter Stone,University of Texas at Austin
Game Theory for Data Science: Eliciting Truthful InformationBoi Faltings and Goran Radanovic2017
Multi-Objective Decision MakingDiederik M. Roijers and Shimon Whiteson2017
Lifelong Machine LearningZhiyuan Chen and Bing Liu2016
Statistical Relational Artificial Intelligence: Logic, Probability, and ComputationLuc De Raedt, Kristian Kersting, Sriraam Natarajan, and David Poole2016
Representing and Reasoning with Qualitative Preferences: Tools and ApplicationsGanesh Ram Santhanam, Samik Basu, and Vasant Honavar2016
Metric LearningAurélien Bellet, Amaury Habrard, and Marc Sebban2015
Graph-Based Semi-Supervised LearningAmarnag Subramanya and Partha Pratim Talukdar2014

iiiRobot Learning from Human TeachersSonia Chernova and Andrea L. Thomaz2014
General Game PlayingMichael Genesereth and Michael Thielscher2014
Judgment Aggregation: A PrimerDavide Grossi and Gabriella Pigozzi2014
An Introduction to Constraint-Based Temporal ReasoningRoman Barták, Robert A. Morris, and K. Brent Venable2014
Reasoning with Probabilistic and Deterministic Graphical Models: Exact AlgorithmsRina Dechter2013
Introduction to Intelligent Systems in Traffic and TransportationAna L.C. Bazzan and Franziska Klügl2013
A Concise Introduction to Models and Methods for Automated PlanningHector Geffner and Blai Bonet2013
Essential Principles for Autonomous RoboticsHenry Hexmoor2013
Case-Based Reasoning: A Concise IntroductionBeatriz López2013
Answer Set Solving in PracticeMartin Gebser, Roland Kaminski, Benjamin Kaufmann, and Torsten Schaub2012
Planning with Markov Decision Processes: An AI PerspectiveMausam and Andrey Kolobov2012
Active LearningBurr Settles2012

ivComputational Aspects of Cooperative Game TheoryGeorgios Chalkiadakis, Edith Elkind, and Michael Wooldridge2011
Representations and Techniques for 3D Object Recognition and Scene InterpretationDerek Hoiem and Silvio Savarese2011
A Short Introduction to Preferences: Between Artificial Intelligence and Social ChoiceFrancesca Rossi, Kristen Brent Venable, and Toby Walsh2011
Human ComputationEdith Law and Luis von Ahn2011
Trading AgentsMichael P. Wellman2011
Visual Object RecognitionKristen Grauman and Bastian Leibe2011
Learning with Support Vector MachinesColin Campbell and Yiming Ying2011
Algorithms for Reinforcement LearningCsaba Szepesvári2010
Data Integration: The Relational Logic ApproachMichael Genesereth2010
Markov Logic: An Interface Layer for Artificial IntelligencePedro Domingos and Daniel Lowd2009
Introduction to Semi-Supervised LearningXiaojinZhu and Andrew B.Goldberg2009
Action Programming LanguagesMichael Thielscher2008

vRepresentation Discovery using Harmonic AnalysisSridhar Mahadevan2008
Essentials of Game Theory: A Concise Multidisciplinary IntroductionKevin Leyton-Brown and Yoav Shoham2008
A Concise Introduction to Multiagent Systems and Distributed Artificial IntelligenceNikos Vlassis2007
Intelligent Autonomous Robotics: A Robot Soccer Case StudyPeter Stone2007

Copyright © 2017 by Morgan & Claypool
All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted inany form or by anymeans—electronic, mechanical, photocopy, recording, or any other except for brief quotationsin printed reviews, without the prior permission of the publisher.
Game Theory for Data Science: Eliciting Truthful Information
Boi Faltings and Goran Radanovic
www.morganclaypool.com
ISBN: 9781627057295 paperbackISBN: 9781627056083 ebook
DOI 10.2200/S00788ED1V01Y201707AIM035
A Publication in the Morgan & Claypool Publishers seriesSYNTHESIS LECTURES ON ARTIFICIAL INTELLIGENCE AND MACHINE LEARNING
Lecture #35Series Editors: Ronald J. Brachman, Jacobs Technion-Cornell Institute at Cornell Tech
Peter Stone, University of Texas at AustinSeries ISSNPrint 1939-4608 Electronic 1939-4616

GameTheory for Data ScienceEliciting Truthful Information
Boi FaltingsÉcole Polytechnique Fédérale de Lausanne (EPFL)
Goran RadanovicHarvard University
SYNTHESIS LECTURES ON ARTIFICIAL INTELLIGENCE ANDMACHINE LEARNING #35
CM&
cLaypoolMorgan publishers&

ABSTRACTIntelligent systems often depend on data provided by information agents, for example, sensordata or crowdsourced human computation. Providing accurate and relevant data requires costlyeffort that agents may not always be willing to provide. Thus, it becomes important not only toverify the correctness of data, but also to provide incentives so that agents that provide high-quality data are rewarded while those that do not are discouraged by low rewards.
We cover different settings and the assumptions they admit, including sensing, humancomputation, peer grading, reviews, and predictions. We survey different incentive mechanisms,including proper scoring rules, prediction markets and peer prediction, Bayesian Truth Serum,Peer Truth Serum, Correlated Agreement, and the settings where each of them would be suit-able. As an alternative, we also consider reputation mechanisms. We complement the game-theoretic analysis with practical examples of applications in prediction platforms, communitysensing, and peer grading.
KEYWORDSdata science, information elicitation, multi-agent systems, computational gametheory, machine learning

ix
ContentsPreface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiii
Acknowledgments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xv
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 Example: Product Reviews . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.1.2 Example: Forecasting Polls . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.1.3 Example: Community Sensing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.1.4 Example: Crowdwork . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2 Quality Control . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3 Setting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Mechanisms for Verifiable Information . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.1 Eliciting a Value . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.2 Eliciting Distributions: Proper Scoring Rules . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3 ParametricMechanisms for Unverifiable Information . . . . . . . . . . . . . . . . . . . . 273.1 Peer Consistency for Objective Information . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.1.1 Output Agreement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.1.2 Game-theoretic Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2 Peer Consistency for Subjective Information . . . . . . . . . . . . . . . . . . . . . . . . . . 323.2.1 Peer Prediction Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333.2.2 Improving Peer Prediction Through Automated Mechanism Design . . 363.2.3 Geometric Characterization of Peer Prediction Mechanisms . . . . . . . . 39
3.3 Common Prior Mechanisms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413.3.1 Shadowing Mechanisms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413.3.2 Peer Truth Serum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.4 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.4.1 Peer Prediction for Self-monitoring . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.4.2 Peer Truth Serum Applied to Community Sensing . . . . . . . . . . . . . . . . 493.4.3 Peer Truth Serum in Swissnoise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 513.4.4 Human Computation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56

x
4 NonparametricMechanisms:Multiple Reports . . . . . . . . . . . . . . . . . . . . . . . . . 594.1 Bayesian Truth Serum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 594.2 Robust Bayesian Truth Serum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 624.3 Divergence-based BTS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.4 Two-stage Mechanisms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 694.5 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5 NonparametricMechanisms:Multiple Tasks . . . . . . . . . . . . . . . . . . . . . . . . . . . 715.1 Correlated Agreement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 715.2 Peer Truth Serum for Crowdsourcing (PTSC) . . . . . . . . . . . . . . . . . . . . . . . . . 765.3 Logarithmic Peer Truth Serum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 795.4 Other Mechanisms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 815.5 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
5.5.1 Peer Grading: Course Quizzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 815.5.2 Community Sensing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6 PredictionMarkets: Combining Elicitation and Aggregation . . . . . . . . . . . . . . 89
7 AgentsMotivated by Influence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 977.1 Influence Limiter: Use of Ground Truth . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 987.2 Strategyproof Mechanisms When the Ground Truth is not Accessible . . . . 103
8 DecentralizedMachine Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1078.1 Managing the Information Agents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1078.2 From Incentives to Payments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1118.3 Integration with Machine Learning Algorithms . . . . . . . . . . . . . . . . . . . . . . 114
8.3.1 Myopic Influence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1158.3.2 Bayesian Aggregation into a Histogram . . . . . . . . . . . . . . . . . . . . . . . . 1168.3.3 Interpolation by a Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1178.3.4 Learning a Classifier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1178.3.5 Privacy Protection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1188.3.6 Restrictions on Agent Behavior . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
9 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1219.1 Incentives for Quality . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1219.2 Classifying Peer Consistency Mechanisms . . . . . . . . . . . . . . . . . . . . . . . . . . . 1229.3 Information Aggregation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1259.4 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125

xiBibliography . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
Authors’ Biographies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135


xiii
PrefaceData has very different characteristics from material objects: its value is crucially dependent onnovelty and accuracy, which are determined only from the context where it is generated. On theother hand, it can be freely copied at no extra cost. Thus, it cannot be treated as a resource withan intrinsic value, as is the focus in most of game theory.
Instead, we believe that game theory for data has to focus on incentives for generatingnovel and accurate data, and we bring together a body of recent work that takes this perspective.
We describe a variety of mechanisms that can be used to provide such incentives. We startby showing incentive mechanisms for verifiable information, where a ground truth can be usedas a basis for incentives. Most of this book is about the much harder problem of incentives forunverifiable information, where the ground truth is never known. It turns out that even in thiscase, game-theoretic schemes can provide incentives that make providing accurate and truthfulinformation the best interest of contributors.
We also consider scenarios where agents are mainly interested in influencing the result oflearning algorithms through the data they provide, including malicious agents that do not re-spond to monetary rewards. We show how the negative influence of any individual data provideron learning outcomes can be limited and thus how to thwart malicious reports.
While our main goal is to make the reader understand the principles for constructingincentive mechanisms, we finish by addressing several other aspects that have to be consideredfor their integration in a practical distributed machine learning system.
This book is a snapshot of the state of the art in this evolving field at the time of thiswriting. We hope that it will stimulate interest for further research, and make it itself obsoletesoon!
Boi Faltings and Goran RadanovicJuly 2017


xv
AcknowledgmentsOur interest in this topic goes back to 2003 and much of the early work was carried out incollaboration with Radu Jurca, who has developed several of the mechanisms described in thisbook and is responsible for many important insights. We also thank numerous researchers fordiscussions and comments over the years, in particular Yiling Chen, Vincent Conitzer, ChrisDellarocas, Arpita Ghosh, Kate Larson, David Parkes, David Pennock, Paul Resnick, TuomasSandholm, Mike Wellmann, and Jens Witkowski.
Boi Faltings and Goran RadanovicJuly 2017


1
C H A P T E R 1
Introduction1.1 MOTIVATIONThe use of Big Data for gaining insights or making optimal decisions has become a mantra ofour time. There are domains where data has been used for a long time, such as financial marketsor medicine, and where the improvements in current technology have enabled innovations suchas automated trading and personalized health. The use of data has spread to other domains, suchas choosing restaurants or hotels based on reviews by other customers and one’s own past pref-erences. Automated recommendation systems have proven very useful in online dating servicesand thus influence the most important choice of our lives, that of our spouse. More controversialuses, such as to profile potential terrorists, profoundly influence our society already today.
Given that data is becoming so important—it has been called the “oil of the 21stcentury”—it should not be restricted to be used only by the entity that collected it, but becomea commodity that can be traded and shared. Data science will become a much more powerfultool when organizations can gather and combine data gathered by others, and outsource datacollection to those that can most easily observe it.
However, different from oil, it is very difficult to tell the quality of data. Just from a piece ofdata itself, it is impossible to tell a random number from an actual measurement. Furthermore,datamay be redundant with other data that is already known. Clearly, the quality of data dependson its context, and paying for data according to its quality will require more complex schemesthan for oil.
Another peculiarity of data is that it can be copied for free. A value is generated only whendata is observed for the first time. Thus, it makes sense to focus on how to reward those thatprovide those initial observations in a way that not only compensates them for the effort, butmotivates them to provide the best possible quality. This is the problem we address in this book.
To understand the quality issue, let us consider four examples where data is obtained fromothers: product reviews, opinion polls, crowdsensing, and crowdwork.
1.1.1 EXAMPLE: PRODUCTREVIEWSAnyone who is buying a product, choosing a restaurant, or booking a hotel should take intoaccount the experiences of other, like-minded customers with the different options. Thus, re-views have become one of the biggest successes of the internet, a case where users truly shareinformation for each others’ benefit. Reviews today are so essential for running a restaurant or ahotel that there is a lot of reason for manipulating them, and we have to wonder if we can trust
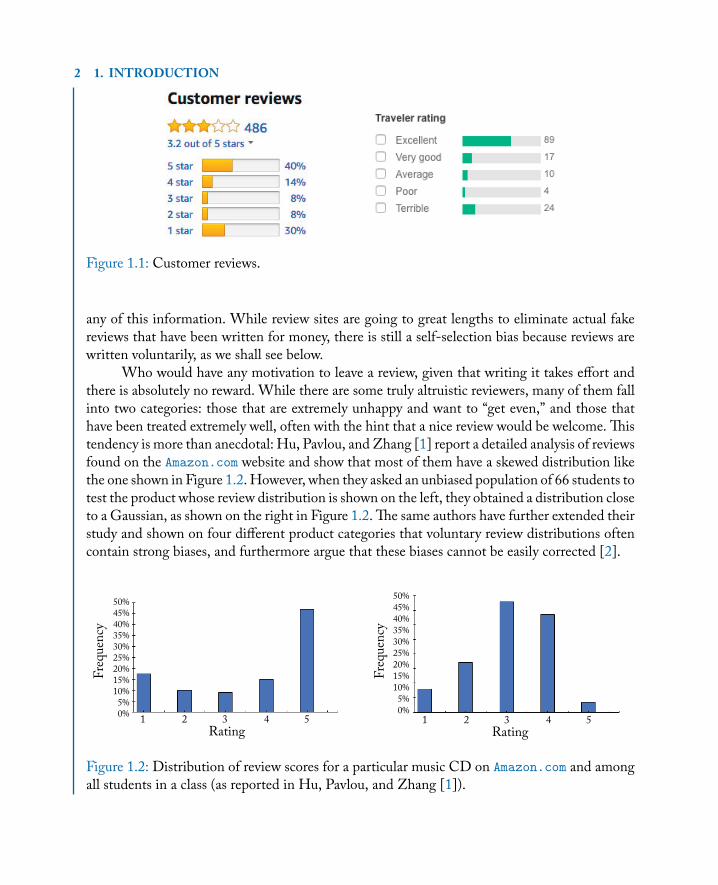
2 1. INTRODUCTION
Figure 1.1: Customer reviews.
any of this information. While review sites are going to great lengths to eliminate actual fakereviews that have been written for money, there is still a self-selection bias because reviews arewritten voluntarily, as we shall see below.
Who would have any motivation to leave a review, given that writing it takes effort andthere is absolutely no reward. While there are some truly altruistic reviewers, many of them fallinto two categories: those that are extremely unhappy and want to “get even,” and those thathave been treated extremely well, often with the hint that a nice review would be welcome. Thistendency is more than anecdotal: Hu, Pavlou, and Zhang [1] report a detailed analysis of reviewsfound on the Amazon.com website and show that most of them have a skewed distribution likethe one shown in Figure 1.2. However, when they asked an unbiased population of 66 students totest the product whose review distribution is shown on the left, they obtained a distribution closeto a Gaussian, as shown on the right in Figure 1.2. The same authors have further extended theirstudy and shown on four different product categories that voluntary review distributions oftencontain strong biases, and furthermore argue that these biases cannot be easily corrected [2].
1 2 3 4 5 1 2 3 4 5Rating
Frequency
Frequency
Rating
50%45%40%35%30%25%20%15%10%5%0%
50%45%40%35%30%25%20%15%10%5%0%
Figure 1.2: Distribution of review scores for a particular music CD on Amazon.com and amongall students in a class (as reported in Hu, Pavlou, and Zhang [1]).

1.1. MOTIVATION 3Given such a biased distribution, we have to ask ourselves if it makes sense to give so much
weight to reviews when we make decisions. Clearly, there is a lot of room for improvement inthe way that reviews are collected, and this will be one of the main topics of this book.
1.1.2 EXAMPLE: FORECASTINGPOLLSAnother area where data has a huge impact on our lives are opinion polls, such as forecasts ofelection outcomes, of public opinion about policies and issues, or of the potential success ofnew products. We have seen some spectacular failures of these polls, such as in predicting theoutcome of the vote about Scottish independence in 2014 (see Figure 1.3), or the vote aboutBritain leaving the EU in 2016. Political campaigns and party platforms could more accuratelyreflect true voter preferences if they could rely on accurate polls. But political polls are just the tipof the iceberg: huge inefficiencies are caused by products and services that do not fit the needs oftheir customers because these have not been accurately determined by the polls that were usedin planning.
Figure 1.3: Evolution of the online opinion poll Swissnoise during the time leading up thereferendum on Scottish independence on September 18, 2014.
The internet could provide a great tool for collecting this information, but we find similarissues of self-selection and motivation as we had with reviews. People who are fans of particularidols or who have particular agendas will go to great lengths to influence poll outcomes to servetheir ulterior motives, while the average citizen has no interest in spending the effort necessaryto answer polls. We need schemes that encourage unbiased, knowledgeable participants, andaccurate estimates.
1.1.3 EXAMPLE: COMMUNITY SENSINGAccording to an estimate released by the World Health Organization in March 2014, air pol-lution kills 7 million people each year. This makes it a more serious issue than traffic accidents,which are held responsible for 1.25 million deaths by the same organization. While it was long

4 1. INTRODUCTIONthought that air pollution spreads quite uniformly across cities, recent research has shown it tobe a very localized phenomenon with big variations of over 100% even in the space of 100 m.Figure 1.4 shows an example of fine particle distribution in the city of Beijing. Huge variationsof up to a factor of 5 exist not only between places that are only a few kilometers apart, but alsoat one and the same place within just one hour. The influence on human health could be reducedif people could adjust their movements to minimize exposure to the most polluted zones.
Figure 1.4: Fine particle distribution in the city of Beijing. Courtesy of Liam Bates, OriginsTechnology Limited.
While some pollution can be seen and smelled, truly harmful substances such as fineparticles, CO and NO2, cannot be detected by humans, so theymust be alerted by sensors to avoidexposure. Newly developed low-cost sensors hold the promise to obtain real-time measurementsat reasonably low cost. As a city does not have easy access to all locations, the best way to deploysuch sensors is through community sensing, where sensors are owned and operated by individualsand they get paid by the city for feeding the measurements into a system that aggregates theminto a pollution map that is made available to the public.
An early example of such a low-cost sensor is the Air Quality Egg, an open source de-sign developed in a kickstarter project in 2013, and sold over 1,000 times at a price of $185
(2013 price). The measurements are uploaded to a center controlled by manufacturer, and thusprovide a (albeit not dense enough) map of air pollution that everyone can inspect. While theaccuracy of such first-generation sensors is insufficient for practical use, the strong public interestshows that such schemes are feasible.
Sensor quality is improving rapidly. At the time of this writing, the LaserEgg shownin Figure 1.5 offers highly accurate fine particle measurements for just $85 (2016 price), and

1.1. MOTIVATION 5more comprehensive devices are under development at similar low cost. Buyers of the LaserEggcan upload their data to the internet, and the map in Figure 1.5 shows the distribution of thethousands of devices that have been connected in the city of Beijing alone; together they producea the real-time pollution map shown in Figure 1.4.
Figure 1.5: Example of a low-cost sensor: the Laser Egg. Courtesy of Liam Bates, OriginsTechnology Limited.
Thus, we can expect community sensing to become commonplace in the near future.How-ever, an important issue is how to compensate sensor operators for their efforts in procuring andoperating the sensors. This problem will be solved by the techniques we show in this book.
1.1.4 EXAMPLE: CROWDWORKIt has become common to outsource intellectual work, such as programming, writing, and othertasks, through the internet. An extreme form of such outsourcing is crowdsourcing, where smalltasks are given to a large anonymous crowd of workers who get small payments for executing eachtask. Examples of tasks found on the Amazon Mechanical Turk platform shown in Figure 1.6include verifying the consistency of information on websites, and labeling images or naturallanguage texts.
Crowdwork is also used in massive open online courses (MOOC) where students gradeeach others’ homework, a process known as peer grading.
Later in the book, we will show practical experiences with incentive schemes both incrowdwork and peer grading. The difficulty in crowdwork is not only to obtain the right selectionof workers, but also to make them invest the effort needed to obtain results of good quality. Thus,it is important that the incentives are significant enough to cover the cost of this effort.

6 1. INTRODUCTION
Figure 1.6: Example of a crowdworking platform: Amazon Mechanical Turk.
1.2 QUALITYCONTROLThere are three different ways to improve the quality of contributed data. They can all be usedtogether, and in fact often they can mutually strengthen each other.
The first and easiest to implement is filtering: eliminating outliers and data that is other-wise statistically inconsistent. For example, in crowdwork it is common to give the same task toseveral workers, and apply a weighted majority vote to determine the answer. When noise andbiases are known in more detail, statistical methods, such as those by Dawid and Skene [5], canhelp to the underlying truth. As these techniques are well developed, they are not our focus inthis book, and should be used in parallel with the techniques we show.
The second way is to associate a quality score to the agents providing the data. For ex-ample, in a crowdworking setting it is common to include gold tasks that have known answers;workers are assigned a quality score based on the proportion of gold tasks they answer correctly.Alternatively, worker quality can be estimated as a latent variable [3] by fitting a model of bothworker accuracy and true values to the reported data.
The third way is to provide incentives for agents to do their best to provide accurate in-formation. For example, in a prediction platform, we could reward data as a function of howaccurately it predicted the eventual outcome. However, in many cases, data is not that easy toverify, either because it may be subjective, as in customer experience, or the ground truth maynever be known, as in most elicitation settings. Somewhat surprisingly, using game-theoretic

1.3. SETTING 7mechanisms it is nevertheless possible to provide strong incentives for accurate data in mostpractical settings, and this is the focus of this book.
Among the three options, incentives is the only one that does not need to throw awaydata—in fact, they work to increase the amount and quality of available data. Incentives can besomewhat inaccurate, as long as agents believe that they are correct on average. Even a slightlyinaccurate incentive can elicit correct data 100% of the time, while filtering and reputation cannever completely eliminate inaccuracies.
However, an important condition for incentives to work is that the agents providing theinformation are rational: they act to optimize their expected reward. Agents who misunderstand,who don’t care, or who have strong ulterior motives will not react. Thus, it is important for theschemes to be simple and easy to evaluate by agents providing information.
1.3 SETTINGIn this book, we consider the multi-agent setting shown in Figure 1.7. We collect data aboutthe state of a phenomenon, which can be, for example, the quality of a restaurant in the case ofreviews, the true answer to a task in the case of crowdwork, or a physical phenomenon such asthe pollution in a city.
Qi(X|Si)
Agent i
Agent j
Agent k
CenterPhenomenon
2
1
3
4
Si
Sj
Sk
1. Observe Signals2. Update Beliefs3. Report Observations4. Reward Agents and Publish the Distribution of the Reports
Figure 1.7: Multi-agent setting assumed in this book.
The state is characterized by a variable X that takes values in a discrete space fx1; : : : ; xng.The phenomenon is observed by several information agents A D fa1; : : : ; akg. Agent ai observes

8 1. INTRODUCTIONa signal si taken from the same vocabulary as the states so that we assume that si takes values infx1; : : : ; xng as well.
A center is interested in data about the phenomenon in order to learn a model or makedecisions that depend on it. It asks the agents to report their information about the phenomenon.In return, it provides agents with a reward that is chosen to motivate the agents to provide thehighest quality of information possible.
We distinguish between objective data, where every agent observes the same realization ofthe phenomenon, and subjective data, where each agent observes a possibly different realization ofthe same phenomenon. Measuring the temperature at a particular time and place is an exampleof objective data. Judging the quality of meals in a restaurant is subjective data since every agenteats a different meal but from the same kitchen. For objective data, the center is interested inobtaining the most accurate estimate of this value, whereas for subjective data, the goal willusually be to obtain the distribution of values observed by different agents.
For objective data, the state of the phenomenon has a ground truth that distinguishesaccurate from inaccurate reports. We distinguish the case of verifiable information, where thecenter will eventually have access to the ground truth, and unverifiable information, where suchground truth will never be known or does not exist. Examples of verifiable information areweather forecasts and election polls. Subjective data such as a product review is always unverifi-able; and in practice most objective data is also never verified since it would be too costly to doso.
For subjective data, the objective of the center cannot be to obtain a ground truth, as sucha ground truth cannot be defined. The best it can do is to model the distribution of the signalsobserved by the information agents: for restaurant reviews, the center would like to predict howmuch another customer will like the meal, not the reasons why the restaurant obtains mealswith this quality distribution. Even for objective information, the center will sometimes be moreinterested in modeling the observations rather than the objective truth: weather forecasts reporta subjective temperature that accounts for wind and humidity.
Therefore, we assume throughout this book that the center’s objective is to obtain accuratereports of the signals observed by the information agents. Consequently, we will consider a su-perficial but simple model of the phenomenon where the state is just the distribution of signalsthat the population of agents observes. For example, for pollution measurements this would be adistribution indicating a noisy estimate, and for product reviews it would reflect the distributionof ratings. This allows methods to be general without the need for assumptions about detailedmodels of the phenomenon itself.
Influencing an agent’s choice of strategy The crucial elements of the scenario, as given above,are the agents that observe the phenomenon. Each agent is free to choose a strategy for reportingthis observation to the center. We distinguish heuristic strategies, where the agent does not evenmake the effort to observe the phenomenon.

1.3. SETTING 9Definition 1.1 A reporting strategy is called heuristicwhen the reported value does not dependon an observation of the phenomenon.
And cooperative strategies.
Definition 1.2 A reporting strategy is called cooperative if the agent invests effort to observethe phenomenon and truthfully reports the observation.
Examples of heuristic strategies are to always report the same data, to report random data, orto report the most likely value according to the prior distribution. In cooperative strategies,we sometimes distinguish different levels of effort that result in different accuracy. Cooper-ative strategies are a subclass of truthful strategies, where agents report their belief about thephenomenon truthfully. We will see later that when we are able to strictly incentivize truthfulstrategies, we can also incentivize the effort required for cooperative strategies with the properscaling.
Except in the chapter on limiting influence, we assume that the agents have no interest ininfluencing the data collected by the center toward a certain result. We assume furthermore thatagents are rational and risk-neutral in that they always chose the strategy that maximizes theirexpected utility, and we assume that their utilities are quasi-linear so that they can be calculatedas the difference between reward and cost of their effort.
These characteristics make it possible for the center to influence the agents’ choice ofstrategy through the rewards they offer. In game theory, this is called a mechanism, and thedesign of such mechanisms is the main topic of this book. In general, we strive to achieve thefollowing properties:
• truthfulness: it induces agents to choose a cooperative and truthful strategy;
• individually rational: agents can expect a positive utility from participating; and
• positive self-selection: only agents that are capable of providing useful data can expect apositive utility from participating.
Principle for mechanism design Agents incur a cost for obtaining and reporting data to thecenter. They will not do so without being at least compensated for this cost. Depending on thecircumstances, they may be interested in monetary compensations for the cost they incur (wheremonetary could also mean recognition, badges, or other such rewards), or they may be interestedin influencing the model the center learns from their data. In most of the book, we considerthe case of monetary incentives, and only Chapter 7 addresses the case of agents motivated byinfluence. This is because such agents can hardly be expected to provide truthful data, but ratheropinions, and it is not clear that such situations actually allow accurate models.
The principle underlying all truthful mechanisms is to reward reports according to con-sistency with a reference. In the case of verifiable information, this reference is taken from the

10 1. INTRODUCTIONground truth as it will eventually be available. In the case of unverifiable information, it will beconstructed from peer reports provided by other agents. The trick is that the common signal thatallows the agents to coordinate their strategies is the phenomenon they can all observe. Thus,by rewarding this coordination, they can be incentivized to make their best effort at observ-ing the phenomenon and reporting it accurately. However, care must be taken to avoid otherpossibilities of coordination.
Another motivation for this principle was pointed out recently by Kong andSchoenebeck [4]. We can understand an agent’s signal si and a reference signal sj to be re-lated only through the fact that they derive from the same underlying phenomenon. To makea prediction of sj , the center can only use information from agent reports such as si . By thedata processing lemma, a folk result in information theory, no amount of data processing canincrease the information that signal si gives about sj . In fact, any transformation of si other thanpermutations can only decrease the information that si gives about sj . Thus, scoring the reportssi by the amount of information they provide about sj is a good principle for motivating agentsto report information truthfully. It also aligns the agent’s incentives with the center’s goal ofobtaining a maximum amount of information for predicting sj .
Agentbeliefs Ourmechanisms use agents’ self-interest to influence their strategies.This influ-ence depends crucially on how observations influence the agent’s beliefs about the phenomenonand about the reward it may receive for different strategies. Thus, it is crucial to model beliefsand belief updates in response to the observed signal.
The belief of an information agent ai is characterized by a prior probability distributionPi .x/ D fpi .x1/; : : : ; pi .xn/g of what the state X of the phenomenon might be, where we dropthe subscript if it is clear from the context.1 Following an observation, based on the receivedsignal si it will update its prior to a posterior distribution Pri .X D xjsi D s/ D Pi .xjs/, whichwe often write as Qi .xjs/. As a shorthand, we often drop the subscript identifying the agent andinstead put the observed signal as a subscript. For example, we may write qs.x/ for qi .xjs/ whenthe agent is clear form the context. Note also that we use Pr to denote objective probabilitieswhile P and Q are subjective agent beliefs.
Importantly, we assume that si is stochastically relevant to the states of the phenomenonx1; : : : ; xn, meaning that for all signal values xj ¤ xk Qi .xjxj / ¤ Qi .xjxk/ so that they can bedistinguished by their posterior distributions.
Belief updates We assume that agents use Bayesian updates where the prior belief reflects allinformation before observation, and the posterior belief also includes the new observation. Thesimplest case is when the signal si simply indicates a value o as the observed value. When theprobability distribution is given by the relative frequencies of the different values, the update
1Throughout the book, we use uppercase letters to denote variables and probability distributions, and lowercase letters todenote values or probabilities of individual values.

1.3. SETTING 11could be weighted mean between the new observation and the prior distribution:
Oq.x/ D
�.1 � ı/p.x/C ı for x D o
.1 � ı/p.x/ for x ¤ oD .1 � ı/p.x/C ı � 1xDo; (1.1)
where ı is a parameter that can take different values according to the weight that that an agentgives to its own measurement vs. that of others.
Two properties will be particularly useful for guaranteeing properties of mechanisms thatwe show in this book: self-dominating and self-predicting.
Consider first objective data, where agents believe that the phenomenon they observe hasone true state and they all observe this state with some measurement noise. For example, theycount the number of customers in the same restaurant at a specific time, or they measure thetemperature at the same place and time.
Provided themeasurement is unbiased, the belief update would be to replace the prior withthe probabilities obtained by the measurement, since it more accurately characterizes the actualvalue. This would correspond to ı D 1. We could allow for the case where the agent mistrustsits observations and thus forms a convex combination of prior and observation.
As long as the measurement dominates the prior information, i.e., ı > 0:5, we can showthat the belief update will satisfy the following self-dominating condition.
Definition 1.3 An agent’s belief update is self-dominating if and only if the observed value o
has the highest probability among all possible values x:
q.ojo/ > q.xjo/ 8x ¤ o: (1.2)
The proof is straightforward: since ı > 0:5, q.ojo/ > 0:5 and is thus larger than all otherp.xjo/ that must be less than 0:5.
For subjective data, where agents observe different samples from the distribution, anagent’s observation, even if absolutely certain, should not replace the prior belief, as it knowsthat other agents observe a different instance. For example, a customer who is dissatisfied witha product that has a very high reputation may believe that he has received a bad sample, andthus could still believe that the majority of customers are satisfied. Thus, for subjective data theobservation is just one sample while the prior represents potentially many other samples.
The belief update should therefore consider an agent’s observation as just one of manyother samples, and give it much lower weight by using a much smaller ı. For example, ı D 1=t
would compute the moving average if o is the t th observation. ı could also be chosen differentlyto reflect the confidence in the measurement. We call this update model the subjective update.

12 1. INTRODUCTIONClearly, subjective belief updates do not always satisfy the self-dominating condition, as is al-ready shown in the example of poor service. Thus, we introduce a weaker condition by onlyrequiring the increase in the probability of the observed value to be highest.
Definition 1.4 An agent’s belief update is self-predicting if and only if the observed value hasthe highest relative increase in probability among all possible values:
q.ojo/=p.o/ > q.xjo/=p.x/ 8x ¤ o: (1.3)
This condition is satisfied when an agent updates its beliefs in a subjective way as in Equa-tion (1.1), since its reported value o is the only one that shows in increase over the prior proba-bility.
In amore general scenario, an agentmay obtain from its observation a vector p.obsjx/ thatgives the probability of its observation given the different possible values x of the phenomenon.Using the maximum likelihood principle, it would report the value o that assigns the highestprobability to the observation:
o D argmaxx
p.si D obsjx/:
For its belief update, Bayes rule also allows to compute a vector u of probabilities for each of thevalues:
ui .x/ D p.xjsi D obs/ Dp.si D obsjx/p.x/
p.si D obs/
where p.si D obs/ is unknown but can be obtained from the condition thatP
x ui .x/ D 1. ABayesian agent will use this vector for its belief update:
Oqi .x/ D .1 � ı/p.x/C ıui .x/ D .1 � ı C ı˛p.si D obsjx//p.x/; (1.4)
where ˛ D 1=.P
x p.si D obsjx/p.x// is a normalizing constant. This form of updating has thecapability of taking into account correlated values. For example, when measuring a temperatureof 20ı, due to measurement inaccuracies 19 and 21 may also increase their likelihood. This couldbe reflected in increases in the posterior probability not only for 20, but also the neighboringvalues 19 and 21.
Provided that the agent chooses the value o it reports according to the maximum like-lihood principle, this more precise update also satisfies the self-predicting condition, sinceOqi .x/=p.x/ D .1 � ı C ı˛p.si D obsjx// is largest for the maximum likelihood estimate o thatmaximizes p.si D obsjx/. However, even for high ı there is no guarantee of satisfying the self-dominating condition, since the prior probability of the maximum-likelihood value could bevery small.

1.3. SETTING 13Deriving agent beliefs from ground truth One way to model an agent’s observation of ob-jective data is that it observes the ground truth through a filter that has certain noise and sys-tematic biases. Sometimes there exists a model of this filter in the form of a confusion matrixF.sj!/ D Pr.si D sj� D !/ that gives the probability of an observed signal si given a groundtruth !, shown as an example in Figure 1.8. Such models have proven useful to correct noise in
Phenomenon state !
a b cagent a 0.8 0.2 0signal b 0.2 0.6 0.2s c 0 0.2 0.8
Figure 1.8: Example confusion matrix, giving the probability distribution F.sj!/ D Pr.si D
sj� D !/ .
postprocessing data; for example, Dawid and Skene [5] show a method that uses the expectationmaximization algorithm to construct an optimal estimation of underlying values that is consis-tent with the signal reports. Such a model could let us derive what an agent’s beliefs and beliefupdates should be. This confusion matrix could arise, for example in the following crowdworkingscenario: agents are asked to classify the content of web pages into inoffensive (value a), mildlyoffensive (b), and strongly offensive (c). The prior distribution for this example might be:
P.!/
p(a) p(b) p(c)0.79 0.20 0.01
and the confusionmatrix of Figure 1.8might characterize the observation bias applied by crowd-workers, who tend to err on the side of caution and classify inoffensive content as offensive. Notethat given this observation bias, the prior distribution of the signals shows this bias:
P.si /
p(a) p(b) p(c)0.67 0.28 0.05
For our purposes, knowing the confusion matrix of the agents reporting the informationallows computing the posterior beliefs that an agent should have about its peers following an

14 1. INTRODUCTIONobservation. Using the confusion matrix and the prior probabilities given above:
q.sj jsi / DX!2�
f .sj j!/f .!jsi /
DX!2�
f .sj j!/f .si j!/p.!/
p.si /
D
P!2� f .sj j!/f .si j!/p.!/P
!2� f .si j!/p.!/;
where f refers to the probabilities defined by the confusion matrix model in Figure 1.8. Fig-ure 1.9 gives the posterior probabilities q.sj jsi / assuming the shown prior probabilities for eachvalue. This prediction can be useful for designing incentive mechanisms, or for understanding
Agent i’s observation si
a b cagent j’s a 0.77 0.54 0.17observation b 0.22 0.37 0.53sj c 0.01 0.09 0.3
Figure 1.9: Resulting belief updates: assuming the shown prior beliefs and the confusion matrixshown in Figure 1.8, an agent would form the posterior probabilities q.sj jsi / shown.
conditions on agent beliefs that are necessary for such mechanisms to work.We can see that for predicting the observation of the peer agent j , value a is dominating
for observations a and b, and b is dominating for observation c. Thus, the distributions areclearly not self-dominating. Are they at least self-predicting? Using the same confusion matrixand prior probabilities as above, we can obtain the relative increases of probability q.sj jsi /=p.sj /
as the following matrix:
Agent i’s observation si
a b cagent j’s a 1.137 0.80 0.25observation b 0.80 1.32 1.90sj c 0.25 1.90 6.25
Clearly, the values on the diagonal are the highest in their respective columns, meaning the theobserved value also sees that largest increase in probability for the peer observation. Thus, thedistribution satisfies the self-predicting property.
However, this is not always the case. When the proportion of errors increases further, eventhe self-predicting condition can be violated. Consider, for example, the following confusionmatrix:

1.3. SETTING 15
World state �
a b cagent a 0.8 0.2 0observation b 0.1 0.5 0.3si c 0.1 0.3 0.7
This leads to the following prior probabilities of the different observations:
P.si /
p(a) p(b) p(c)0.67 0.18 0.15
and so we can obtain the relative increases of probability p.sj jsi /=p.sj / as the following matrix:
Agent i’s observation si
a b cagent j’s a 1.137 0.68 0.77observation b 0.68 1.78 1.51sj c 0.77 1.50 1.44
and it turns out that this belief structure is not self-predicting since p.bjc/=p.c/ D 1:51 >
p.cjc/=p.c/ D 1:44. This increased likelihood of b happens because mildly offensive contentis often misclassified as offensive. As mildly offensive content is much more likely than offen-sive content, it is the most likely cause of an “offensive” signal, and the most likely peer signal.
What theoretical guarantees can be given for belief updates given based onmodeling filtersin this way? We present three simple cases, the first valid for general situations and the othertwo for binary answer spaces. For the self-dominating condition, we can observe the following.
Proposition 1.5 Whenever for all agents i and all x, f .si D xj� D x/ and f .� D xjsi D x/ areboth greater than
p0:5 D 0:71, then the belief structure satisfies the self-dominating condition, even
if agents have different confusion matrices and priors.
Proof. The conditional probability q.sj jsi / for si D sj D x is:
q.sj D xjsi D x/ DX
w
f .sj D xj� D w/f .� D wjsi D x/
> f .sj D xj� D x/f .� D xjsj D x/
� 0:5:
Since q.sj D x0jsi D x/ � 1 � q.sj D xjsi D x/ < 0:5, we obtain that q.sj D xjsi D x/ >
q.sj D x0jsi D x/. �

16 1. INTRODUCTIONTo ensure the self-predicting condition, we can impose a weaker condition, provided that
agents have identical confusion matrices and priors.
Proposition 1.6 For binary answer spaces and identical confusion matrices and priors, wheneverF.sj!/ is fully mixed and non-uniform, belief updates satisfy the self-predicting condition.
For conditional probability q.sj jsi / and si D sj D x we have:
q.si D xjsj D x/ DX
!
f .si D xj� D !/ � f .� D !jsj D x/ DX
!
f .xj!/2�
p.!/
p.x/
D
P! f .xj!/2 � p.!/P! f .xj!/ � p.!/
>
�P! f .xj!/ � p.!/
�2P! f .xj!/ � p.!/
;
where the inequality is due to Jensen’s inequality, with the strictness following from the conditionthat F.sj!/ is fully mixed and non-uniform.
Therefore:
q.si D xjsj D x/ >X
!
f .xj!/ � p.!/ D p.si D x/ D 1 � p.si D y/
> 1 � q.si D yjsj D y/ D q.si D xjsj D y/
where the last inequality is due to q.si D yjsj D y/ > p.si D y/.For heterogeneous beliefs, we can ensure the self-predicting condition under a slightly
stronger condition, but only valid for binary answer spaces.
Proposition1.7 For binary answer spaces and heterogenous confusionmatrices and priors, wheneverp.s D xj� D x/ > p.s D x/, belief updates satisfy the self-predicting condition.
Proof. Notice that:
q.si D xjsj D z/ D f .si D xj� D x/ � f .� D xjsj D z/C f .si D xj� D y/ � f .! D yjsj D z/
D Œf .si D xj� D x/ � f .si D xj� D y/� � f .� D xjsi D z/C f .si D xj� D y/:
Since:
f .si D xj� D x/ � f .si D xj� D y/ D f .si D xj� D x/ � 1C f .si D yj� D y/
> f .si D x/ � 1C f .si D y/ D 0
z that (strictly) maximizes q.si D xjsj D z/ is equal to z that (strictly) maximizes f .� D xjsj D
z/. Using Bayes rule and the condition of the proposition, we obtain:
f .� D xjsj D x/ Df .sj D xj� D x/
p.sj D x/� p.� D x/ >
p.sj D x/
p.sj D x/� p.� D x/ D p.� D x/
f .� D xjsj D y/ Df .sj D yj� D x/
p.sj D y/� p.� D x/ <
p.sj D y/
p.sj D y/� p.� D x/ D p.� D x/

1.3. SETTING 17so it must also hold that f .� D xjsj D x/ > f .� D xjsj D y/. Therefore, z D x strictly max-imizes pj .� D xjz/ and consequently p.xjz/. �
NOTATIONNotation MeaningP; Q; R; : : : uppercase: probability distributionp.x/; q.x/; r.x/; : : : lowercase: probability of value x
EP Œf .x/� expected value of f .x/ under distribution P :P
x p.x/ � f .x/
H.P / entropy of probability distribution P , H.P / DP
x �p.x/ log p.x/
DKL.P jjQ/ Kullback-Leibler Divergence DKL.P jjQ/ DP
x p.x/ log p.x/q.x/
�.P / Simpson’s diversity index �.P / DP
x p.x/2
1cond selector function: 1cond D 1 if cond is true, D 0 otherwisef .�x/, f�x f is a function that is independent of x
freq.x/ frequence of value x normalized so thatP
x freq.x/ D 1
gm.x1; : : : ; xn/ geometric mean of x1; : : : ; xn, gm.x1; : : : ; xn/ D np
x1 � : : : � xn
ROADMAPThis books presents an overview of incentives for independent self-interested agents to accuratelygather and truthfully report data. We do not aim to be complete, but our main goal is to makethe reader understand the principles for constructing such incentives, and how they could playout in practice.
We distinguish scenarios with verifiable information, where the mechanism learns, alwaysor sometimes, a ground truth that can be used to verify data, and unverifiable information, wherea ground truth is never known.
When information is verifiable, incentives can be provided to each agent individuallybased on the ground truth, and we describe schemes in Chapter 2. When information is notverifiable, incentives can still be derived from comparison with other agents through a game-theoretic mechanism. However, this necessarily involves assumptions about agent beliefs. Thus,in Chapter 3, we describe mechanisms where these assumptions are parameters of the mecha-nism that have to be correctly set from the outside. Often, setting these parameters is problem-atic, so there are nonparametric mechanisms that obtain the parameters either from additionaldata provided by the agents, or from statistics of the data provided by a group of agents. Wepresent mechanisms that follow these approaches in Chapters 4 and 5.
As verification also allows assessing the influence of data on the output of a learning algo-rithm, incentives can be used to align incentives of agents with those of the learning mechanism.One way is to reward agents for their positive influence on the model through prediction mar-kets, a technique we describe in Chapter 6. Another is to limit their influence on the learningoutcome so as to thwart malicious data providers whose goal is to falsify the learning outcome.

18 1. INTRODUCTIONWe discuss how maintaining reputation can achieve this effect in Chapter 7. In Chapter 8, weconsider issues that present themselves when the techniques are integrated into a machine learn-ing system: managing the information agents and self-selection, scaling payments and reducingtheir volatility, and integration with machine learning algorithms.