gg v1.1 microarrays and promoter analysis gregory gonye topic 5 eleg-667
Post on 20-Dec-2015
224 views
TRANSCRIPT

gg v1.1
Microarrays and Promoter Analysis
Gregory Gonye
Topic 5
ELEG-667

gg v1.1
Overview• Opportunity: general
• cDNA data, ESTs
• Genomic data
• Microarrays– nuts and bolts
– analysis
• Opportunity: specific– Yeast example (Church et al.)
– Statement of Work: Project Review

gg v1.1
Opportunity• Large scale EST projects for many organisms
• Genome sequencing projects for many organisms
• Highly parallel technologies for gene expression measurement
• Sophisticated analysis for associating genes by expression
• Full length cDNA sequence data

gg v1.1
Opportunity• Large scale EST projects for many
organisms– Sequence data for mRNAs and some protein– Clones corresponding to mRNAs (cDNA
clones) for reagents– Expression data (significance with scale)– Homologies between species

gg v1.1
Opportunity• Genome sequencing projects for many
organisms– genomic DNA data contains all the information
• mRNA
• transcriptional control elements: promoters and enhancers
• organization
– Comparative genomics• Conservation=Function

gg v1.1
Opportunity• Highly parallel technologies for gene
expression measurement• Sophisticated analysis for associating genes
by expression
– exploits EST projects for data and reagents– produces associations/hypotheses to be tested– uses and produces annotation

gg v1.1
Opportunity• Large scale EST projects for many
organisms
• Genome sequencing projects for many organisms
• Highly parallel technologies for gene expression measurement
• Sophisticated analysis for associating genes by expression

gg v1.1
Opportunity• Full length cDNA sequence data
– Promoter-proximal mRNA sequence– “real” protein data (full length ORFs)– reagents for expression– data for converting mRNA to gene

gg v1.1
Opportunity• Large scale EST projects for many organisms
• Genome sequencing projects for many organisms
• Highly parallel technologies for gene expression measurement
• Sophisticated analysis for associating genes by expression
• Full length cDNA sequence data

gg v1.1
Opportunity• Whole greater then sum of parts:
[mRNA data, EST and full length]X[genomic data] = Genes
[Genes]X[genomic data] = [Promoters]
[cDNA]microarray X [mRNA] = [Genes]assoc
[Genes]assocX [Promoters] = Functional data

gg v1.1
Opportunity• In plain English:
The cDNA data is used to identify and locate genes in the genomic data. Using the gene location and gene structure, we predict the promoter region for each gene. A subset of these genes are associated by a microarray experiment. Analysis of the promoters of the associated genes, within and across species, can lead to knowledge of how these genes are regulated.

gg v1.1
Overview• Opportunity: general
• cDNA data, ESTs
• Genomic data
• Microarrays– nuts and bolts
– analysis
• Opportunity: specific– Yeast example (Church et al.)
– Statement of Work: Project Review

gg v1.1
Molecular Biology 101:Genome (DNA) to Genes to mRNA
Required to understand relationships of data sets
Three large scale efforts:
• Expressed Sequence Tag
• Full length cDNA
• Genomic DNA

gg v1.1
Biological Information Flow = Central Dogma
AUGACUGCUUUU
TACTGACGAAAAATGACTGCTTTT
Met-Thr-Ala-Phe
DNA
RNA
Protein
transcription
splicing (higher organisms)
translation
gg v1.1
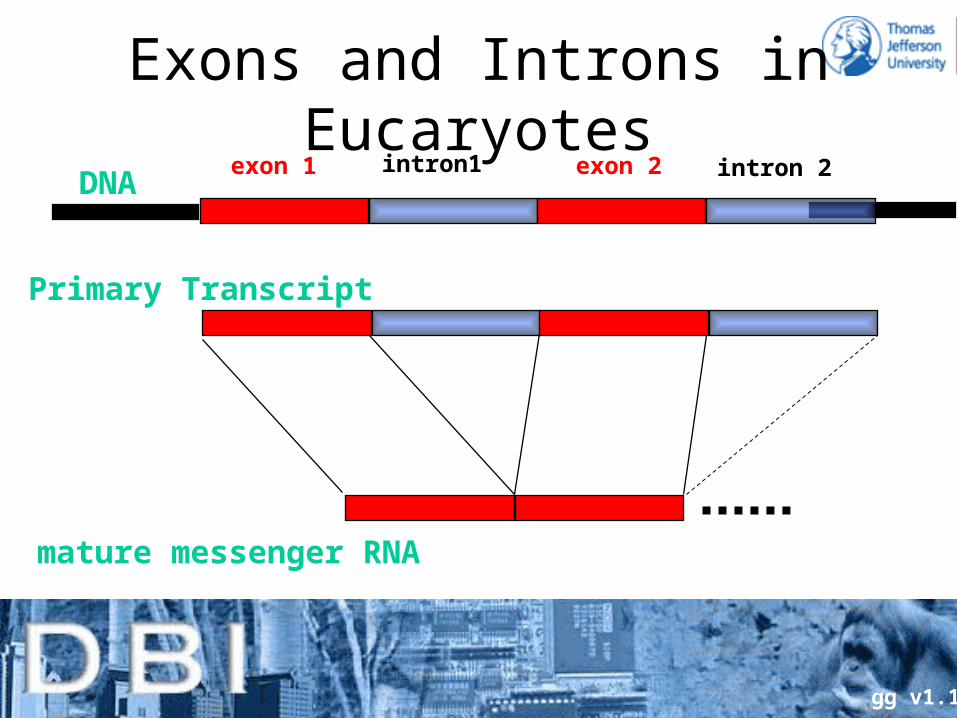
Exons and Introns in EucaryotesDNA
mature messenger RNA
exon 1 exon 2intron1 intron 2
Primary Transcript

gg v1.1
cDNA and ESTs
mRNA is converted to a DNA copy
= complementary DNA, cDNA

gg v1.1
cDNA Synthesis
AAAAAnmRNA
TTTTTn
3’
3’Reverse Transcriptase
AAAAAnTTTTTn
3’mRNA
cDNAfirst strand RNAse H, DNAP
AAAAAnTTTTTn
Second Strand
dNTPs and primer
dNTPs

gg v1.1
cDNA and ESTs
mRNA is converted to a DNA copy
= complementary DNA, cDNA

gg v1.1
cDNA and ESTs
•mRNA is converted to a DNA copy
= complementary DNA, cDNA
•cDNA is directionally inserted into a vector (plasmid) DNA
1. Clonal propagation/amplification in E. coli
2. Addition of known sequence flanking unknown cDNA

gg v1.1
cDNA and ESTs
•mRNA is converted to a DNA copy
= complementary DNA, cDNA
•cDNA is directionally inserted into a vector (plasmid) DNA
1. Clonal propagation/amplification in E. coli
2. Addition of known sequence flanking unknown cDNA
•EST is obtained from cDNA insert (~400-800 bases) using known vector sequence (universal) as priming site
EST is sequence data. EST clone is reagent used to obtain that data. EST is sequence for only part of cDNA in EST clone .

gg v1.1
EST data resources• dbEST and UniGene
– http://ncbi.nlm.nih.gov/UniGene
• TIGR Gene Indexes– http://www.tigr.org/tdb/tgi.shtml
Objectives:• Cluster sequences to identify individual mRNAs (~1
cluster=1 mRNA)• Annotate clusters• Distribute clones

gg v1.1
Molecular Biology 101:Genome (DNA) to Genes to mRNA
Required to understand relationships of data sets
Three large scale efforts:
• Expressed Sequence Tag
• Full length cDNA
• Genomic DNA

gg v1.1
Full length cDNA
• Why?:– complete protein coding information– complete exon information (=gene when
combined with genomic data)– 5’ end directs search for promoter elements

gg v1.1
Full length cDNA
• Why?:– complete protein coding information– complete exon information (=gene when
combined with genomic data)– 5’ end directs search for promoter elements
• Who?:– Y. Hayashizaki, RIKEN group Yokohama,
Japan http://genome.rtc.riken.go.jp/

gg v1.1
Full Length cDNA: How?• Issues:
– Need copying to be complete, no partial products– Need to differentiate full length mRNAs from
degraded mRNAs– Cloning requirements remain the same:
• directional, universal vector, high efficiency
– Need to redirect sequencing to full insert, not single run from one end

gg v1.1
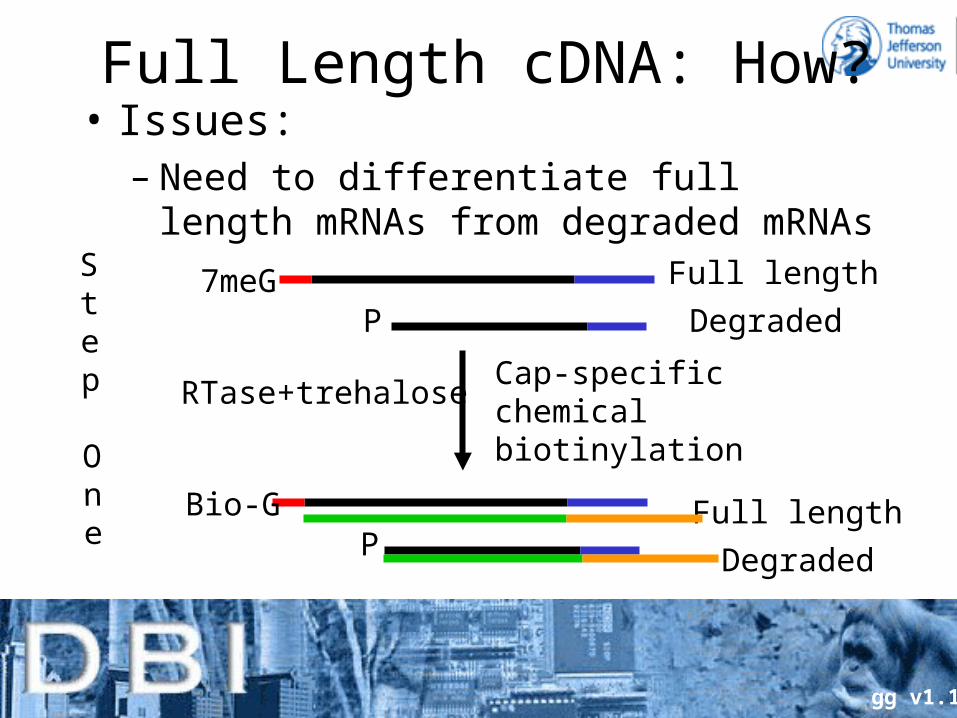
Full Length cDNA: How?• Issues:• Need copying to be complete, no partial
products– Problem is secondary structure of mRNAs and
lack of processivity of Reverse Transcriptase– Solution: Thermo-stabilize RTase using
trehalose, run RT reaction at high temperature destabilizing secondary structure, allowing longer elongation produces
gg v1.1
Full Length cDNA: How?• Issues:
– Need to differentiate full length mRNAs from degraded mRNAs
P7meG Full length
Degraded
Bio-G Full length
Degraded
Cap-specificchemical biotinylation
Step
One
RTase+trehalose
P

gg v1.1
SA
Full Length cDNA: How?
• Issues:– Need to differentiate full length mRNAs from
degraded mRNAs
Bio-G Full length
Degraded
Step Two SA Bio-G
Purified Full length

gg v1.1
Full length cDNA
• Results:– FANTOM Consortium: Functional Annotation
of Mouse ~21,000 nonredundant cDNAs– Full length clones used for protein expression
• Large scale protein-protein interaction matrix
– 5’ mRNA sequence available on large scale

gg v1.1
Molecular Biology 101:Genome (DNA) to Genes to mRNA
Required to understand relationships of data sets
Three large scale efforts:
• Expressed Sequence Tag
• Full length cDNA
• Genomic DNA
gg v1.1
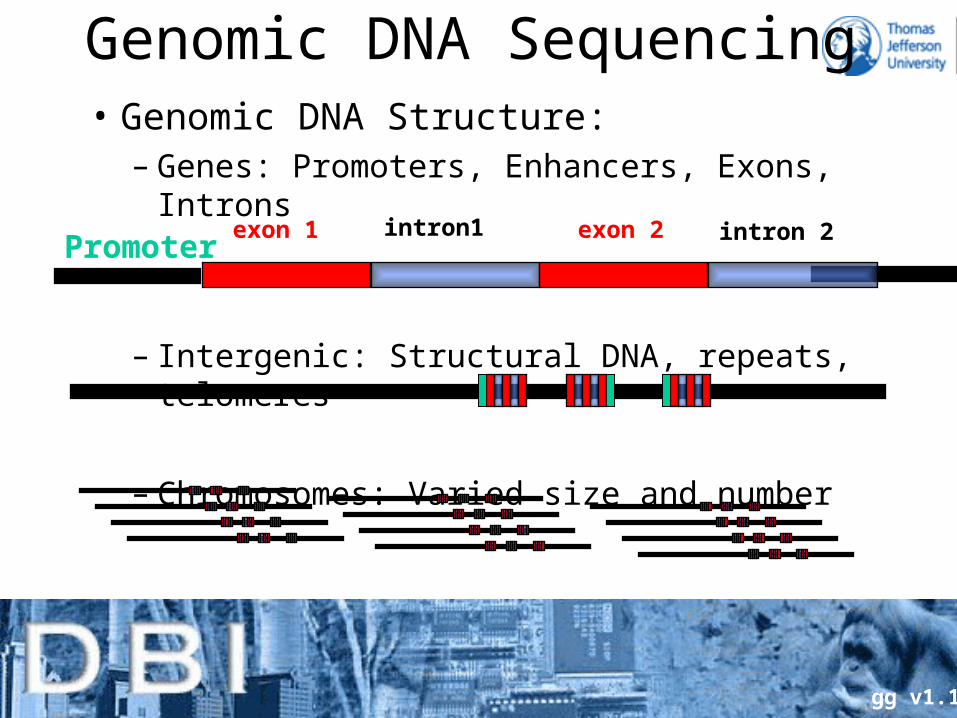
Genomic DNA Sequencing• Genomic DNA Structure:
– Genes: Promoters, Enhancers, Exons, Introns
– Intergenic: Structural DNA, repeats, telomeres
– Chromosomes: Varied size and number
Promoterexon 1 exon 2intron1 intron 2

gg v1.1
Genomic DNA Sequencing• Mammalian genomes about 3 billion bases
• Genomes broken into chunks of 100-500kb– Bacterial Artificial Chromosomes, BAC libraries– BAC inserts ordered by end sequencing and
cross hybridization to generate nonredundant “Golden path”
• Sequencing effort distributed/coordinated internationally

gg v1.1
Genomic DNA Sequencing• Two complementary approaches:
– Walking: • Subclone pieces of BAC inserts
• start from both ends of sub-BAC inserts and sequence inward
• from sequence generated design next set of sequencing primers, rerun, redesign,…
– Shotgun:• Generate random fragments and size-select ~2000bp
• Sequence from both ends
• Assemble sequences to contigs, assemble contigs

gg v1.1
Genomic DNA Sequencing
• Resources:– Trace Archives (NCBI): Individual
unassembled shotgun sequence data– Genomic section of GenBank (NCBI): Contigs,
BAC end sequences, BAC assemblies– Whitehead Institute: Assemblies – Ensembl: Annotation of assembled genomes

gg v1.1
Annotated Genome
Convergence of DataThree large scale efforts:
• Expressed Sequence Tag>>partial Exons
• Full length cDNA>>5’ Exons
• Genomic DNA>>Gene Predictions

gg v1.1
Overview• Opportunity: general
• cDNA data, ESTs
• Genomic data
• Microarrays– nuts and bolts
– analysis
• Opportunity: specific– Yeast example (Church et al.)
– Statement of Work: Project Review

gg v1.1
Overview• Opportunity: general
• cDNA data, ESTs
• Genomic data
• Microarrays– nuts and bolts– analysis
• Opportunity: specific– Yeast example (Church et al.)
• Statement of Work: Project Review

gg v1.1
Highly Parallel Gene Expression Analysis: cDNA Microarrays
• Molecular reagents produced from EST sequencing projects– EST= Expressed Sequence Tag – Clustering of ESTs identifies mRNA diversity– Nonredundant sets of reagents available (>40,000 for
human)
• Technology to use reagents in parallel: microarrays– cDNA or oligonucleotide microarrays

gg v1.1
Microarray-based Gene Expression Analysis
• Manufactured at high density with robotics– 1x3” glass slide common format
– “printing” or “in situ synthesis”
– 20-30,000 spots per slide
• mRNA is converted to labeled cDNA for fluorescent hybridization analysis
• Ratio-metric approach compares expression between samples or to a reference sample by cohybridization: “fold-change”
gg v1.1
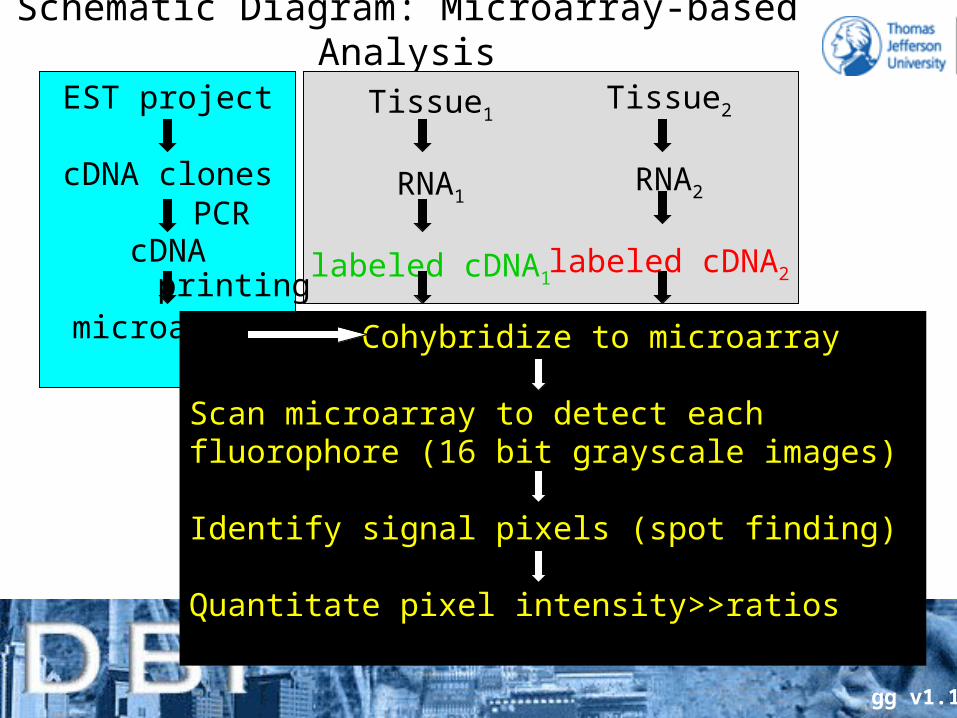
Schematic Diagram: Microarray-based Analysis
EST project
cDNA clones
cDNA
microarray
Tissue1
RNA1
labeled cDNA1
Tissue2
RNA2
labeled cDNA2
Cohybridize to microarray
Scan microarray to detect eachfluorophore (16 bit grayscale images)
Identify signal pixels (spot finding)
Quantitate pixel intensity>>ratios
PCR
printing

gg v1.1
Control Mix Control 92 Ethanol 91
100 1000 10000
100
1000
10000
C
100 1000 10000
100
1000
10000
Control
Control
Ethanol
Control
Hormone-sensitive lipase testicular isoform AI060165 0.79 ± 0.41 0.3134Superoxide dismutase precursor AI029806 0.54 ± 0.26 0.0540
NeuronalSynuclein, alpha AA819897 2.80 ± 0.44 0.0044Basignin AA819719 1.87 ± 0.49 0.0817Synuclein, gamma AI070517 2.08 ± 0.35 0.0150Secretory granule neuroendocrine, protein 1 (7B2 protein) AA998689 2.57 ± 0.49 0.0130Syntaxin 12 AI059347 1.98 ± 0.47 0.0545Dopa decarboxylase AI044610 2.09 ± 0.32 0.0101Cannabinoid receptor 1 AA997501 1.82 ± 0.26 0.0128Neuron-glia-CAM-related cell adhesion molecule AI144588 2.96 ± 0.63 0.0146Copine VI (neuronal) AI145705 0.76 ± 0.29 0.2125
Protein DegradationMetallothionein-III AA924772 2.68 ± 0.45 0.0069Ubiquitin conjugating enzyme AA859229 1.89 ± 0.34 0.0266Cathepsin S AA925933 2.10 ± 0.41 0.0259Pancreatic secretory trypsin inhibitor type II AA858673 1.79 ± 0.29 0.0245
Ribosomal ProteinsRibosomal protein L30 AI030687 3.00 ± 0.28 0.0002Ribosomal protein S7 AA819435 2.36 ± 0.53 0.0290Ribosomal protein S26 AA900527 2.06 ± 0.19 0.0009
Signal TransductionIntegrin-associated protein AI044792 6.58 ± 1.91 0.0183Estrogen-responsive uterine transcript AI045552 3.29 ± 0.35 0.0003Diacylglycerol kinase 90kDa AA818983 2.74 ± 0.41 0.0036Phosphatase and tensin homolog AI136569 4.13 ± 0.20 <0.0001PTP-S, protein-tyrosine phosphatase AI072210 4.55 ± 0.98 0.0077Protein phosphatase 1, catalytic subunit, gamma isoform 1 AA818834 1.94 ± 0.18 0.0014Lysosomal-associated membrane protein 2 AI029935 5.12 ± 2.22 0.0728Striatin-1 AI030330 2.31 ± 0.45 0.0185Rab28 mRNA for ras-homologous GTPase AA955601 2.66 ± 0.73 0.0424Phosphatidate phosphohydrolase type 2 AA818593 2.39 ± 0.39 0.0087Guanine nucleotide-binding protein G-s, alpha subunit AI385146 2.67 ± 0.68 0.0337GTP-binding protein (G-alpha-i2) AA875418 0.26 ± 0.05 <0.0001Cortactin isoform B AI069969 0.75 ± 0.35 0.2498Granulin AA899852 0.45 ± 0.08 <0.0001SAP kinase-3 AA924917 0.62 ± 0.13 0.0105Fibromodulin AI070507 0.56 ± 0.25 0.0587Gonadotropin-releasing hormone receptor AI146077 0.42 ± 0.08 <0.0001Inhibin alpha AA955146 0.4 ± 0.06 <0.0001Retinoic acid receptor rxr-alpha AA957988 1.21 ± 0.68 0.385
Structural ProteinsNoerythroid alpha-spectrin 2 AI030460 10.35 ± 3.62 0.0283Actin, gamma 2, smooth muscle, enteric AA817767 1.94 ± 0.36 0.0266Heme-binding protein 23 kDa AA875245 2.01 ± 0.24 0.0040Dynein, cytoplasmic, intermediate chain 1 AI145198 3.71 ± 1.03 0.0264Beta-chain clathrin associated protein complex AP-2 AA964379 2.74 ± 0.78 0.0443Keritin, type II cytoskeletal 8 AA866466 1.93 ± 0.28 0.0116Lens epithelial protein AA900176 2.49 ± 0.36 0.0043
Function Gene Description accession Ratio p valueApoptosis
Defense against death-1 AA963226 2.19 ± 0.36 0.0108Channels and Pumps
NaPi-2 beta AI146132 3.52 ± 0.56 0.0027ATPase, Na+K+ transporting, alpha 2 polypeptide AA818371 2.04 ± 0.23 0.0027Proton/phosphate symporter, mitochondrial AI044410 9.57 ± 3.73 0.0412
MetabolismSialyltransferase 7C AA956521 2.92 ± 0.53 0.0076Enoyl hydratase-like protein, peroxisomal AA926032 2.78 ± 0.57 0.0138Isocitrate dehydrogenase 1, soluble AA925731 2.45 ± 0.43 0.0100Proteasomal ATPase (Tat-binding protein7) AI060152 4.31 ± 1.08 0.0151Peroxisomal multifunctional enzyme type II AA874974 2.29 ± 0.27 0.0019Cytochrome c oxidase subunit Va, mitochondrial AA998201 2.39 ± 0.54 0.0282Cytochrome c oxidase subunit Vb AA955550 3.64 ± 0.98 0.0245Cytochrome c oxidase subunit VIa (liver) AA899832 1.91 ± 0.16 0.0009Cytochrome c oxidase subunit VIIa 3 AA819708 2.42 ± 0.09 <0.0001CDK110 (cytochrome b ortholog) AA899443 1.97 ± 0.45 0.0504Carboxypeptidase E AA957068 2.28 ± 0.21 0.0005Acetyl-Co A acetyltransferase 1, mitochondrial AA926170 2.18 ± 0.28 0.00383-hydroxyisobutyrate dehydrogenase AA859729 2.62 ± 0.41 0.0053F1-ATPase beta subunit AI146173 8.72 ± 3.35 0.0406Palmitoyl-protein thioesterase AA818995 1.66 ± 0.36 0.0749Peptidylprolyl isomerase A (cyclophilin A) AA818858 2.75 ± 0.51 0.0097Tyrosine 3-monooxygenase activation protein, theta polypeptide AA858957 1.85 ± 0.39 0.04763-hydroxy-3-methylglutaryl-Coenzyme A synthase 1 AA924800 1.86 ± 0.36 0.0345Stearoyl-CoA desaturase 2 AA859213 3.04 ± 1.10 0.0728Lactate dehydrogenase A AI072330 1.86 ± 0.31 0.0215Long-chain 3-ketoacyl-CoA thiolase, mitochondrial AI070082 2.51 ± 0.45 0.010714-3-3 protein, gamma-subtype AA858958 2.20 ± 0.45 0.0253ATP synthase gamma-subunit AI044995 7.01 ± 3.18 0.0697Peroxisome assembly factor-1 AI043801 0.46 ± 0.06 <0.0001Hormone-sensitive lipase testicular isoform AI060165 0.79 ± 0.41 0.3134Superoxide dismutase precursor AI029806 0.54 ± 0.26 0.0540
NeuronalSynuclein, alpha AA819897 2.80 ± 0.44 0.0044Basignin AA819719 1.87 ± 0.49 0.0817Synuclein, gamma AI070517 2.08 ± 0.35 0.0150Secretory granule neuroendocrine, protein 1 (7B2 protein) AA998689 2.57 ± 0.49 0.0130Syntaxin 12 AI059347 1.98 ± 0.47 0.0545Dopa decarboxylase AI044610 2.09 ± 0.32 0.0101Cannabinoid receptor 1 AA997501 1.82 ± 0.26 0.0128Neuron-glia-CAM-related cell adhesion molecule AI144588 2.96 ± 0.63 0.0146Copine VI (neuronal) AI145705 0.76 ± 0.29 0.2125
Protein DegradationMetallothionein-III AA924772 2.68 ± 0.45 0.0069Ubiquitin conjugating enzyme AA859229 1.89 ± 0.34 0.0266Cathepsin S AA925933 2.10 ± 0.41 0.0259

gg v1.1
Advanced Analyses• Clustering
– What:• genes
• experiments
• experiments and genes
– Why:• Classification: how many “types” of samples are there? can type
be predicted? Which genes are best predictors?
• Coregulation: which genes respond alike? Pathway(s) implicated? Epistasis? Regulatory network prediction

gg v1.1
Overview• Opportunity: general
• cDNA data, ESTs
• Genomic data
• Microarrays– nuts and bolts
– analysis
• Opportunity: specific– Yeast example (Church et al.)
– Statement of Work: Project Review

gg v1.1
Overview• Opportunity: general
• cDNA data, ESTs
• Genomic data
• Microarrays– nuts and bolts
– analysis
• Opportunity: specific– Yeast example (Church et al.)
– Statement of Work: Project Review

gg v1.1
Post-Clustering Analysis
• Why are members of a cluster clustering together?– Functional (Pathway): all ribosomal proteins,
DNA synthesis machinary, lysine biosynthesis– Serial regulation: cascades– Transcriptional coregulation via common
regulatory elements: conserved promoters

gg v1.1
What is a promoter?• Cis-acting: physically associated with the gene• Directional: defines transcription initiation site and coding
strand – with TATA box fairly homogeneous– without TATA box less stringent
• Core elements recruit pol II (but inactive)• Regulatory elements are binding sites for Transcription
Factors (+/- active pol II complex)• Sequence-specificity determines P(occupied)

gg v1.1
Convergence at Harvard• Yeast:
– Large genomic-scale gene expression data set– complete annotated genome– NO introns, minimal intergenic sequence– Predicted promoters for every ORF
• Church et al.: Combined microarray data, clustering, and promoter informatics to identify conserved, cluster enriched, regulatory domains

gg v1.1
Tavazoie et al.
• Whole genome expression data (Affy) – Synchronized culture– 15 time points across two cell cycles
• K-means clustering (Euclidian distance) of 3000 highest variance ORFs to 30 clusters
• Obtained 600bp promoter sequence from genome sequence for each ORF
• Used AlignAce (Gibb’s sampling algorithm) to discover motifs
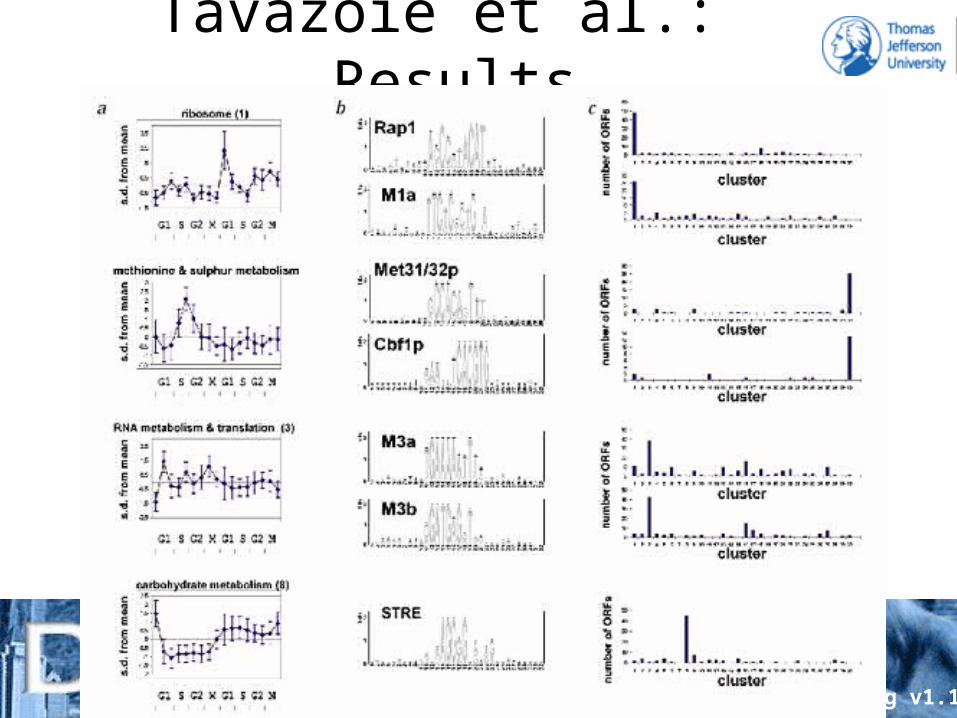
gg v1.1
Tavazoie et al.: Results

gg v1.1
Livesey et al: extend to mouse• Crx knockout mouse vs. wt
– cone and rod differentiation in retina
• Microarray analysis– Crx+/+ vs Crx-/- retina RNA – 16 genes out of 960 tested
• Promoter analysis– proximal 250bp of genes with available promoters (5) used
AlignAce to detect motifs– found single or tandem CBE elements in all

gg v1.1
Overview• Opportunity: general
• cDNA data, ESTs
• Genomic data
• Microarrays– nuts and bolts
– analysis
• Opportunity: specific– Yeast example (Church et al.)
– Statement of Work: Project Review

gg v1.1
Project 5: Microarray data and Promoter Analysis
• Microarray data is “clone limited”– clone set defines subset of all genes under study
• Convergence of genomic, EST, and FL-cDNA data make promoter identification tractable in mammalian systems
• Glaring need for clone::gene::promoter annotation

gg v1.1
Project Summary• Starting from Clone ID recover cDNA sequence and
annotation (multiple paths)
• Use gene annotation, or sequence if none, to locate gene in annotated genome
• Recover genomic sequence associated with gene including 2000 bp upstream of predicted or known exon 1
• Create front end to take clone lists (clustering results) as input, output passed to analysis sw.

gg v1.1
Preprocessing vs “on the fly”
• Clone collection relatively stable, array design relatively stable subset of clone set
• Cluster members dynamic, experiment-dependent
• Prefer rapid results from many queries• Integration with downstream software
Preprocessing to relational database is the best solution

gg v1.1
Opportunity• Large scale EST projects for many organisms
• Genome sequencing projects for many organisms
• Highly parallel technologies for gene expression measurement
• Sophisticated analysis for associating genes by expression
• Full length cDNA sequence data

gg v1.1
Project 5 Handout