s e ntroduce ata ining with apid iner ityhhuang13/cis600/notes/rapidminer.pdf · s u yracus nivers...
TRANSCRIPT

S
U
SYRACUS
UNIVERS
Clust
SE
ITY
tering, C
INTRO
Classific
DUCE D
cation an
DATA M
nd AssoBy
MINING
ociation y Huang, Hu
G WITH
Rules | uaming ; Wu
RAPID
u, Ge
MINERR

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
2 / 24
MENU
Abstract: .................................................................................................................................... 3
1. Introduction to RAPIDMINER .................................................................................................... 4
1) Introduction: ..................................................................................................................... 4
2) Preparation ........................................................................................................................ 5
2. Clustering .................................................................................................................................. 8
1) Clustering on iris datasets with class ................................................................................. 8
2) Clustering on iris datasets without class labels ............................................................... 14
3. Classification tree .................................................................................................................... 16
1) Classify using W‐J48 operator in RapidMiner: ................................................................ 16
2) Classify using DecisionTree operator in RapidMiner: ...................................................... 19
4. Association Rules .................................................................................................................... 22
5. Reference Books ...................................................................................................................... 24
Author: Chapter 1,2 Huang, HuaMing
Chapter 3,4, Chart Wu, Ge

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
3 / 24
Abstract:
In this project, we do the classification, clustering, association rules in Rapid Miner, and introduce
how to use the Rapid Miner to do these actions. At the same time, we will use the tool to analyze
iris datasets and diabetes datasets.
Data Mining is more and more important in the information industry and in society. It affects
almost all aspects of our lives such as market analysis, fraud detection, and customer retention,
to production control and science exploration.
Data mining refers to extracting or “mining” knowledge from large amounts of data. [Reference
from Morgan Kaufmann ‐ Data Mining ‐ Concepts and Techniques, 2nd]
There are also many DM tools for data mining, such as SAS, WEKA, MineSet and RapidMiner. We
will focus on RapidMiner in this topic.

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
4 / 24
1. Introduction to RAPIDMINER
1) Introduction:
Introduce to RapidMiner(from www.rapidminer.com):
RapidMiner (formerly YALE) is the world‐wide leading open‐source data mining solution due
to the combination of its leading‐edge technologies and its functional range. Applications of
RapidMiner cover a wide range of real‐world data mining tasks.
Use RapidMiner and explore your data! Simplify the construction of experiments and the
evaluation of different approaches. Try to find the best combination of preprocessing and
learning steps or let RapidMiner do that automatically for you.
Feature
The modular operator concept of RapidMiner (formerly YALE) allows the design of complex
nested operator chains for a huge number of learning problems in a very fast and efficient way
(rapid prototyping). The data handling is transparent to the operators. They do not have to cope
with the actual data format or different data views ‐ the RapidMiner core takes care of all
necessary transformations. Read here about the most important features of RapidMiner.
Operator Overview
RapidMiner (formerly YALE) and its plugins provide more than 400 operators for all aspects of
Data Mining. Meta operators automatically optimize the experiment designs and users no
longer need to tune single steps or parameters any longer. A huge amount of visualization
techniques and the possibility to place breakpoints after each operator give insight into the
success of your design ‐ even online for running experiments. On this page we discuss the main
groups of operators and give operator examples for each of the groups.
RapidMiner download link: http://rapid‐i.com/content/view/26/82/
RapidMiner Installation Guide: http://rapid‐i.com/content/view/17/40/
RapidMiner Tutorial:
http://sourceforge.net/project/downloading.php?groupname=yale&filename=rapidminer‐4.0‐tut
orial.pdf&use_mirror=internap
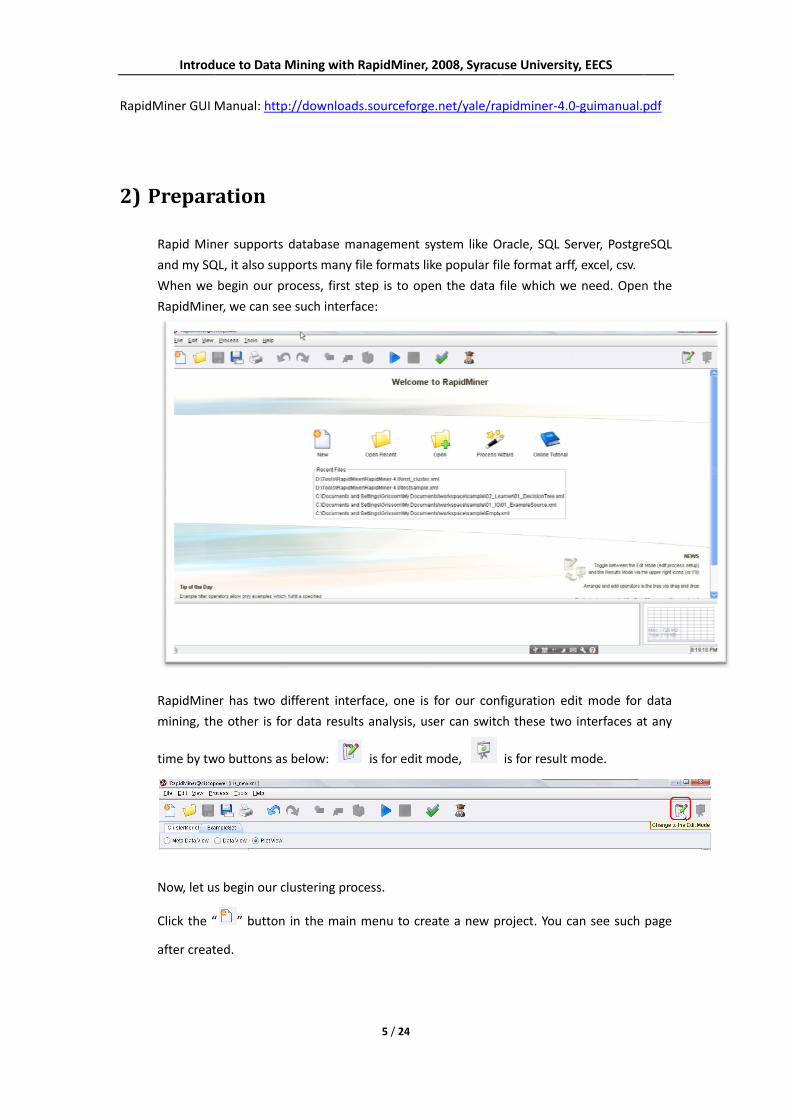
Rapi
2)
Introd
idMiner GUI
Prepar
Rapid Min
and my SQ
When we
RapidMine
RapidMine
mining, th
time by tw
Now, let u
Click the “
after creat
uce to Data M
Manual: http
ration
ner supports
QL, it also sup
begin our pr
er, we can see
er has two d
he other is fo
wo buttons as
s begin our c
“ ” button
ted.
Mining with
p://download
database ma
pports many f
rocess, first s
e such interfa
different inte
or data result
s below:
lustering pro
in the main
RapidMiner,
5 / 24
ds.sourceforge
anagement s
file formats li
step is to ope
ace:
rface, one is
ts analysis, us
is for edit m
cess.
menu to cre
2008, Syracu
e.net/yale/ra
system like O
ke popular fi
en the data f
for our con
ser can switc
mode,
eate a new p
use Universit
apidminer‐4.0
Oracle, SQL Se
le format arff
file which we
figuration ed
ch these two
is for result m
roject. You c
ty, EECS
0‐guimanual.
erver, Postgr
f, excel, csv.
e need. Open
dit mode for
interfaces at
mode.
an see such
eSQL
n the
data
t any
page
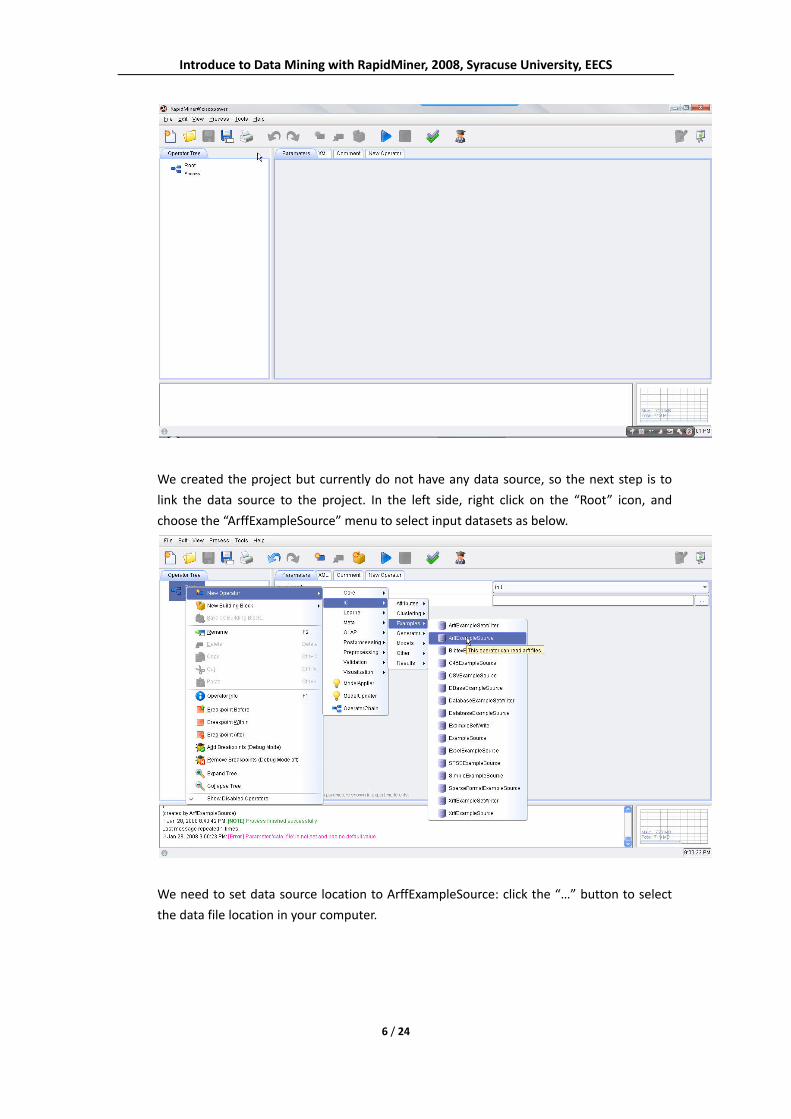
Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
6 / 24
We created the project but currently do not have any data source, so the next step is to
link the data source to the project. In the left side, right click on the “Root” icon, and
choose the “ArffExampleSource” menu to select input datasets as below.
We need to set data source location to ArffExampleSource: click the “…” button to select
the data file location in your computer.

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
7 / 24
RapidMiner displays the path of data file in parameters page of ArffExampleSource.
Please note that the “label_attribute” column below the “data_file” is a special parameter
which can let the RapidMiner ignore the data field you specify.
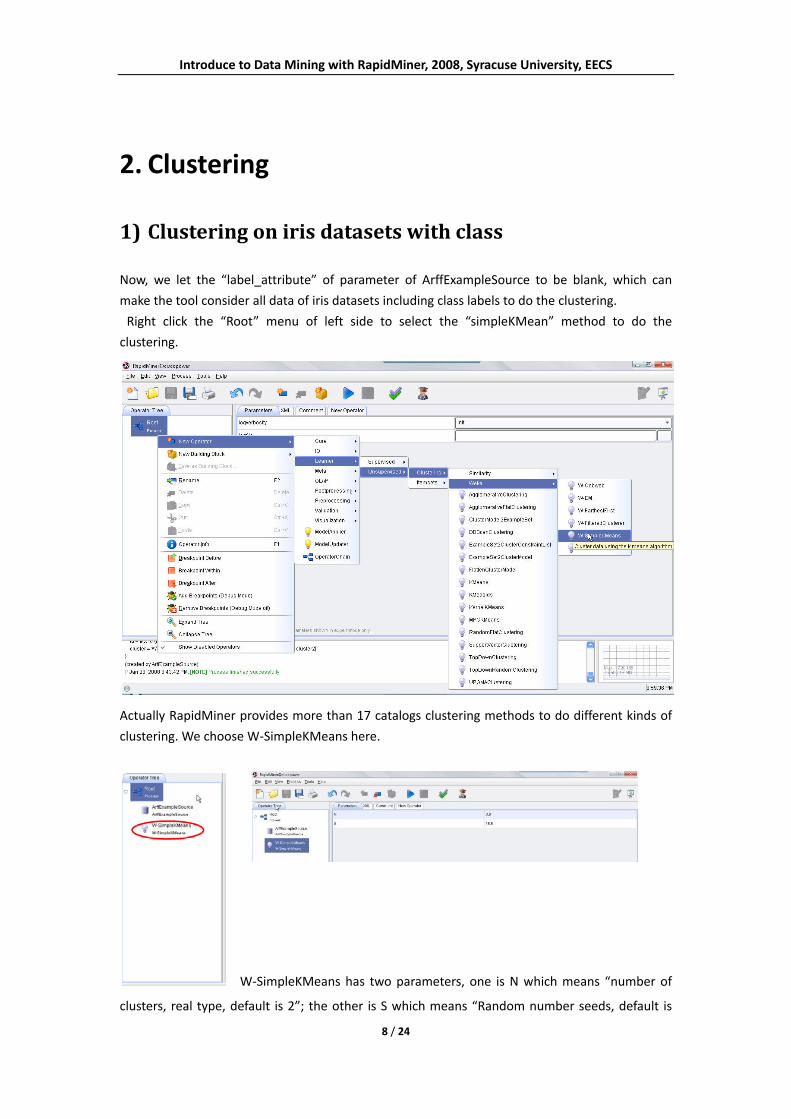
Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
8 / 24
2. Clustering
1) Clustering on iris datasets with class
Now, we let the “label_attribute” of parameter of ArffExampleSource to be blank, which can
make the tool consider all data of iris datasets including class labels to do the clustering.
Right click the “Root” menu of left side to select the “simpleKMean” method to do the
clustering.
Actually RapidMiner provides more than 17 catalogs clustering methods to do different kinds of
clustering. We choose W‐SimpleKMeans here.
W‐SimpleKMeans has two parameters, one is N which means “number of
clusters, real type, default is 2”; the other is S which means “Random number seeds, default is

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
9 / 24
10”.
After setting the S=3 and N=10, click the “ ” button in top side to run the clustering.
ClusterModel Panel:
RapidMiner will show the clustering results after finish the process. “ClusterModel” panel
provides all kinds of information about cluster groups including detail records of cluster groups
and graph view of clusters.
RapidMiner shows the summary information in Text View of ClusterModel panel such as :
Cluster cluster1 [characterization: cluster1]: 50 items
Cluster cluster0 [characterization: cluster0]: 50 items
Cluster cluster2 [characterization: cluster2]: 50 items
Total number of items: 150
Obviously, due to class label of the datasets, RapidMiner do the clustering by the class label first.
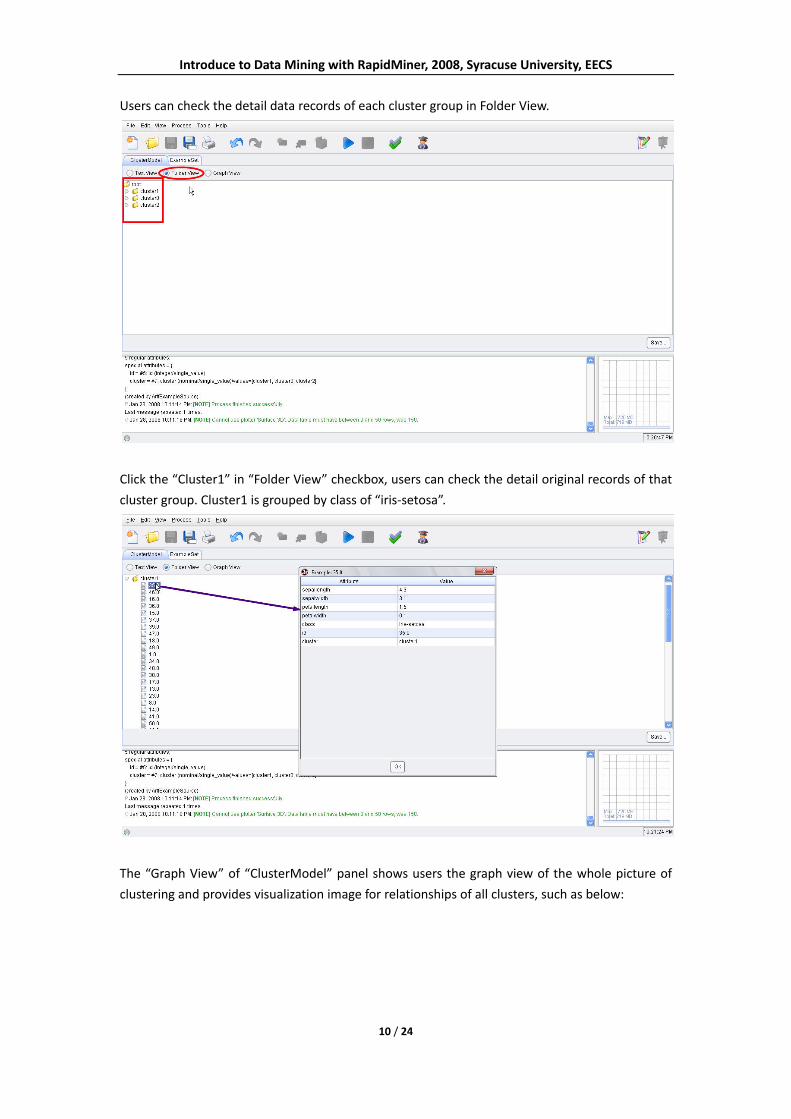
Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
10 / 24
Users can check the detail data records of each cluster group in Folder View.
Click the “Cluster1” in “Folder View” checkbox, users can check the detail original records of that
cluster group. Cluster1 is grouped by class of “iris‐setosa”.
The “Graph View” of “ClusterModel” panel shows users the graph view of the whole picture of
clustering and provides visualization image for relationships of all clusters, such as below:

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
11 / 24
More than tree view, RapidMiner also provides Ballon, KKLayout, FRLayout, ISOM, Circle, Spring
views for our clusters results. Choose the red circle above to select different views.
When clicks clusters in the tree view, all datasets of that cluster will appear in the right side of the
panel.
ExampleSet Panel:
ExampleSet panel provides data view for the users which is different from the ClusterModel. Data
view focus on the data points among the clustering. It has three kinds of data view such as “Meta
Data View”, “Data View” and “Plot View”.

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
12 / 24
First, “Meta View” shows the data types, value types and data statistics of datasets.
The raw data of iris has five fields which are “sepallenth”, “sepalwidth”, “petallength”,
“petalwidth”, “class”. After clustering, RapidMiner will add one cluster label field named “cluster”.
Second, “Data View” displays raw data records of data source, also you can do filter for datasets:
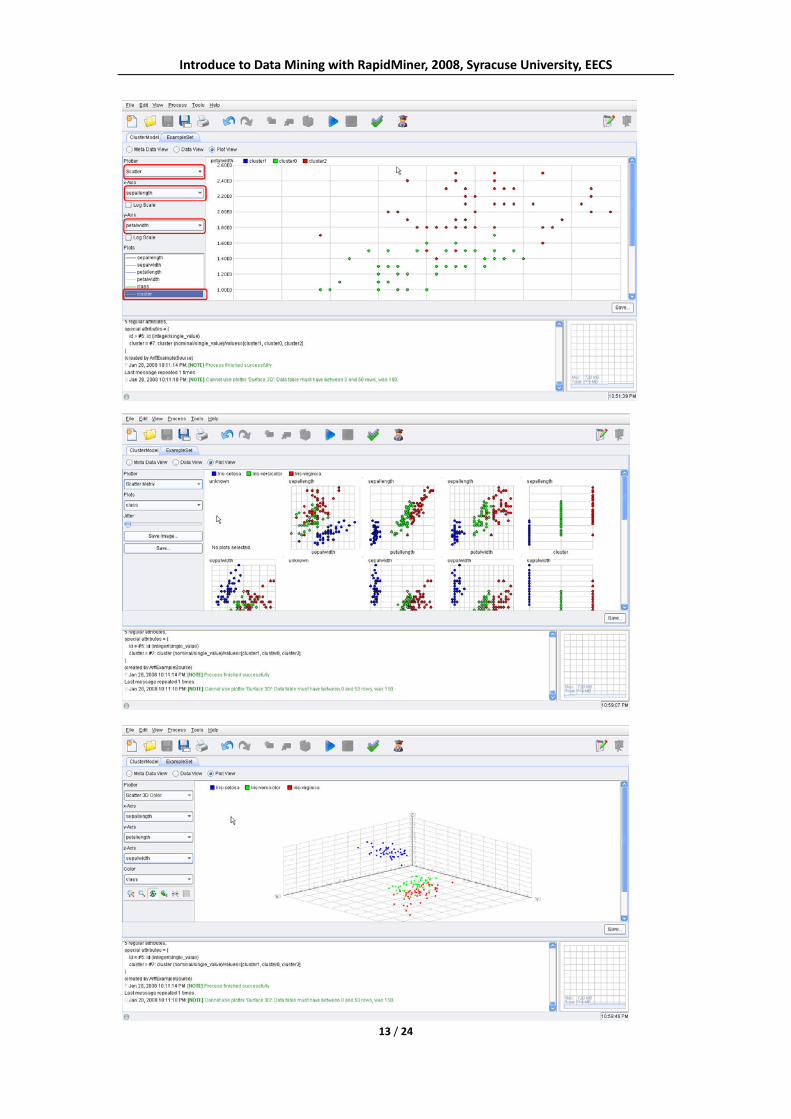
Last view is “Plot View” which shows the chart of clustering dataset points. In “Plot View”, you
can choose different chart types such as “Scatter”, “Scatter Matrix”, “Scatter 3D Color”, “Bubble”.
In different chart type, there are different parameters.
Different cluster often has different color or shape in the plot view.
Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
13 / 24

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
14 / 24
ClusterModel and ExampleSet panels show information of all aspects about clustering we care
about. They are our basic materials for future analysis. RapidMiner provides us a very flexible,
easy to use and visualization tool for data mining.
2) Clustering on iris datasets without class labels
Now, we let the “label_attribute” of parameter of ArffExampleSource to be “class” which is the
field name of class label in our raw data of iris. This setting will let RapidMiner ignore the original
class label among raw data when do clustering.
Part of iris ARFF datasets are showed below:
@RELATION iris
@ATTRIBUTE sepallength REAL
@ATTRIBUTE sepalwidth REAL
@ATTRIBUTE petallength REAL
@ATTRIBUTE petalwidth REAL
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
@DATA
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
…
When we do clustering in this case, the results will different from the data with class label.
The clusters are group by combination of the other
fields except the class. This time, the numbers of
clusters are 61,50,39 which are not 50,50,50 in before.
Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
15 / 24
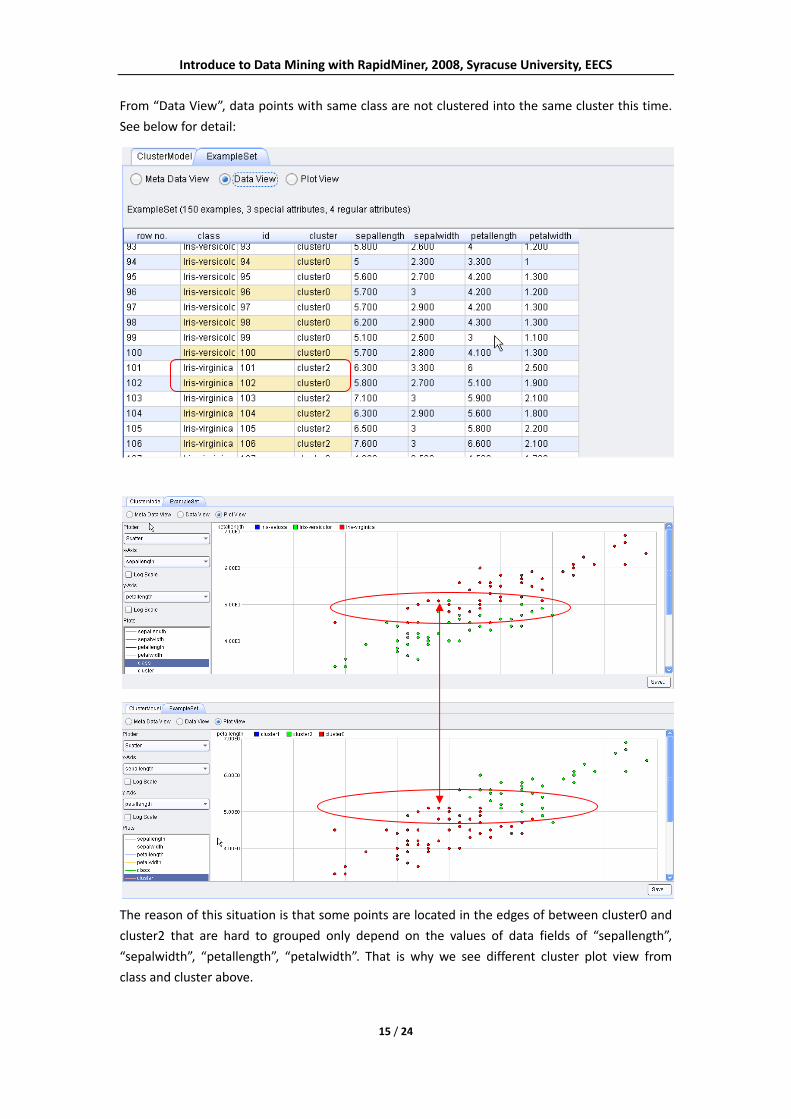
From “Data View”, data points with same class are not clustered into the same cluster this time.
See below for detail:
The reason of this situation is that some points are located in the edges of between cluster0 and
cluster2 that are hard to grouped only depend on the values of data fields of “sepallength”,
“sepalwidth”, “petallength”, “petalwidth”. That is why we see different cluster plot view from
class and cluster above.
Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
16 / 24
3. Classification tree
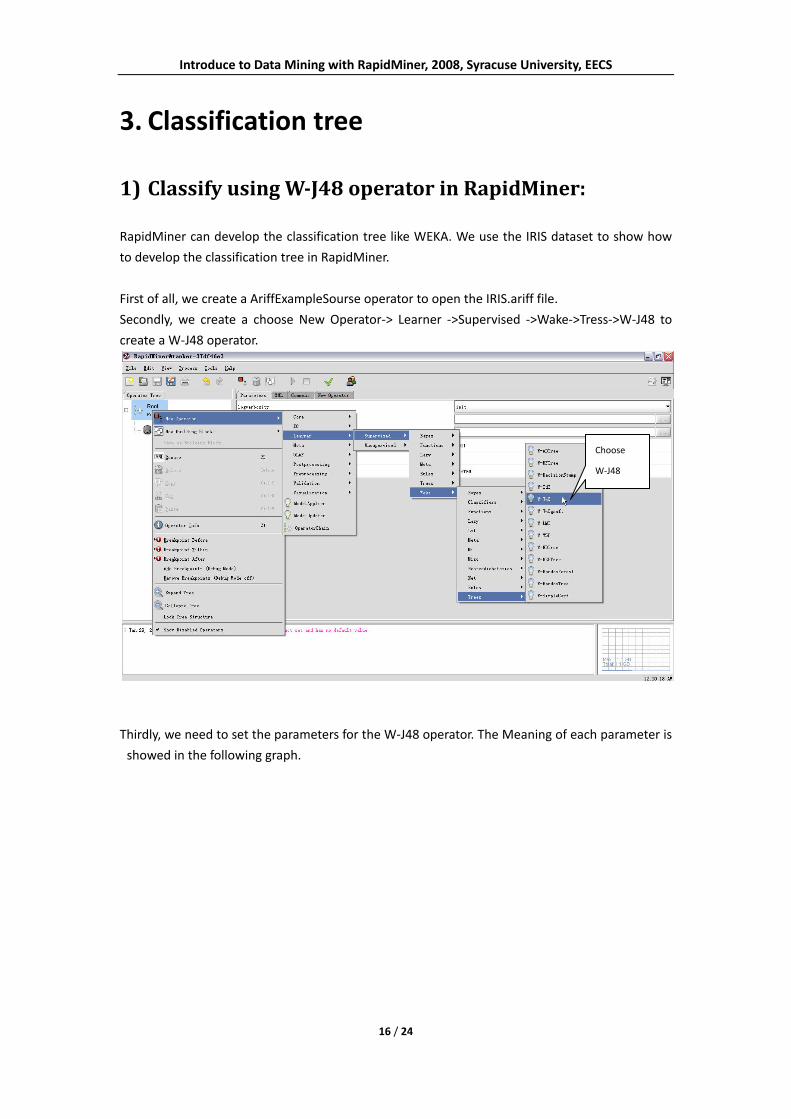
1) Classify using WJ48 operator in RapidMiner:
RapidMiner can develop the classification tree like WEKA. We use the IRIS dataset to show how
to develop the classification tree in RapidMiner.
First of all, we create a AriffExampleSourse operator to open the IRIS.ariff file.
Secondly, we create a choose New Operator‐> Learner ‐>Supervised ‐>Wake‐>Tress‐>W‐J48 to
create a W‐J48 operator.
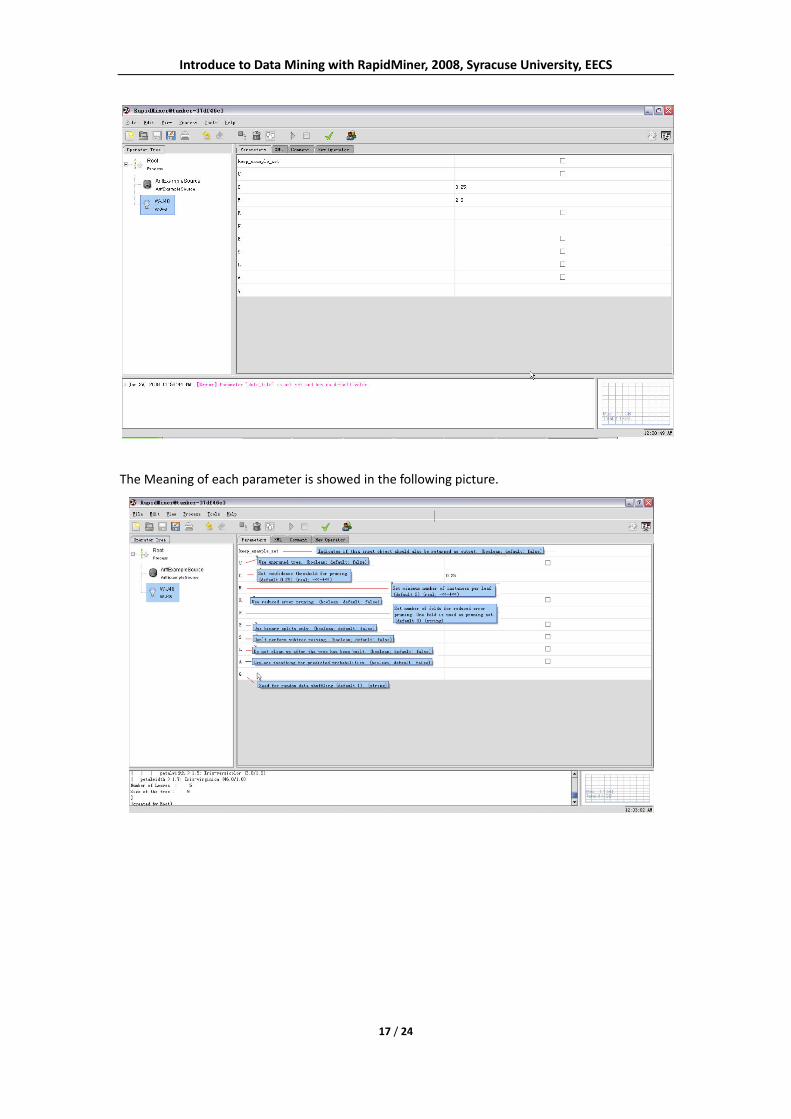
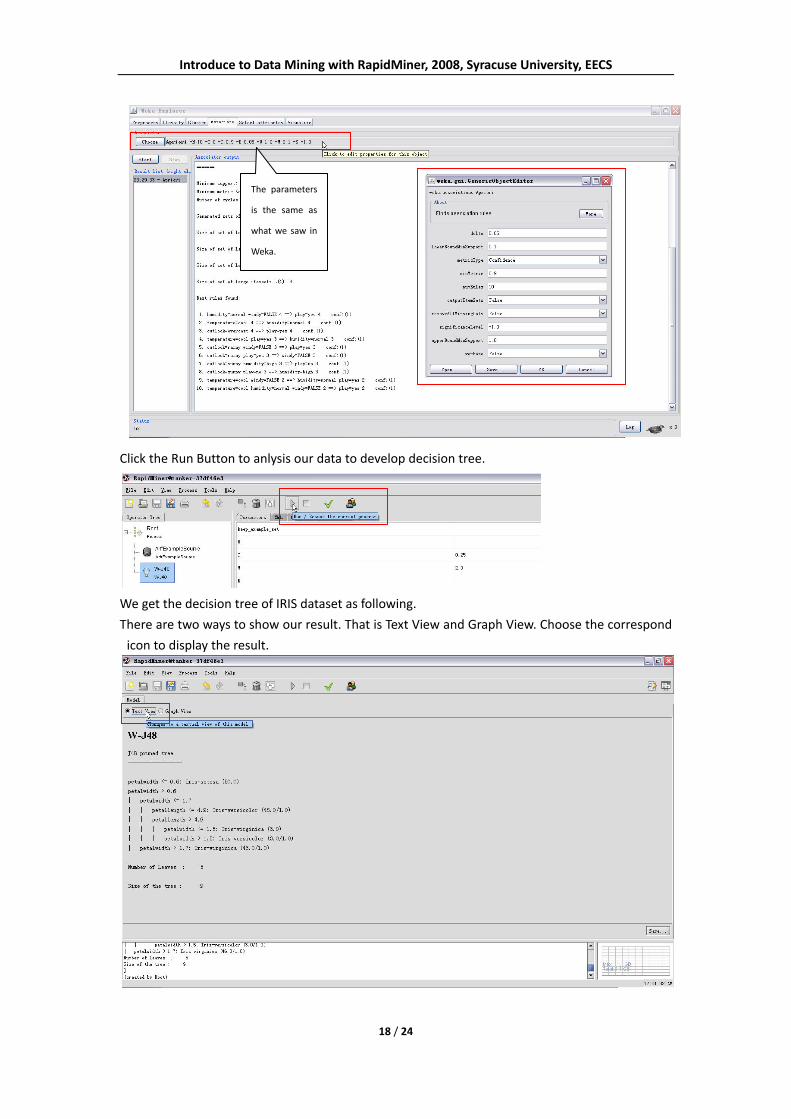
Thirdly, we need to set the parameters for the W‐J48 operator. The Meaning of each parameter is
showed in the following graph.
Choose
W‐J48
Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
17 / 24
The Meaning of each parameter is showed in the following picture.
Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
18 / 24
Click the Run Button to anlysis our data to develop decision tree.
We get the decision tree of IRIS dataset as following.
There are two ways to show our result. That is Text View and Graph View. Choose the correspond
icon to display the result.
The parameters
is the same as
what we saw in
Weka.

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
19 / 24
It represents the concept of predicated class of iris plant. That is, it predicts what class a plant
likely to be. In the graph, internal nodes are denoted by ovals, and leaf nodes are denoted by
rectangles.
For example, Iris‐virginica(46.0/1.0) means that totally 46 points in this branch but only 1 point
does not match( error).
The classification error or performance will be showed in another operator of RapidMiner.
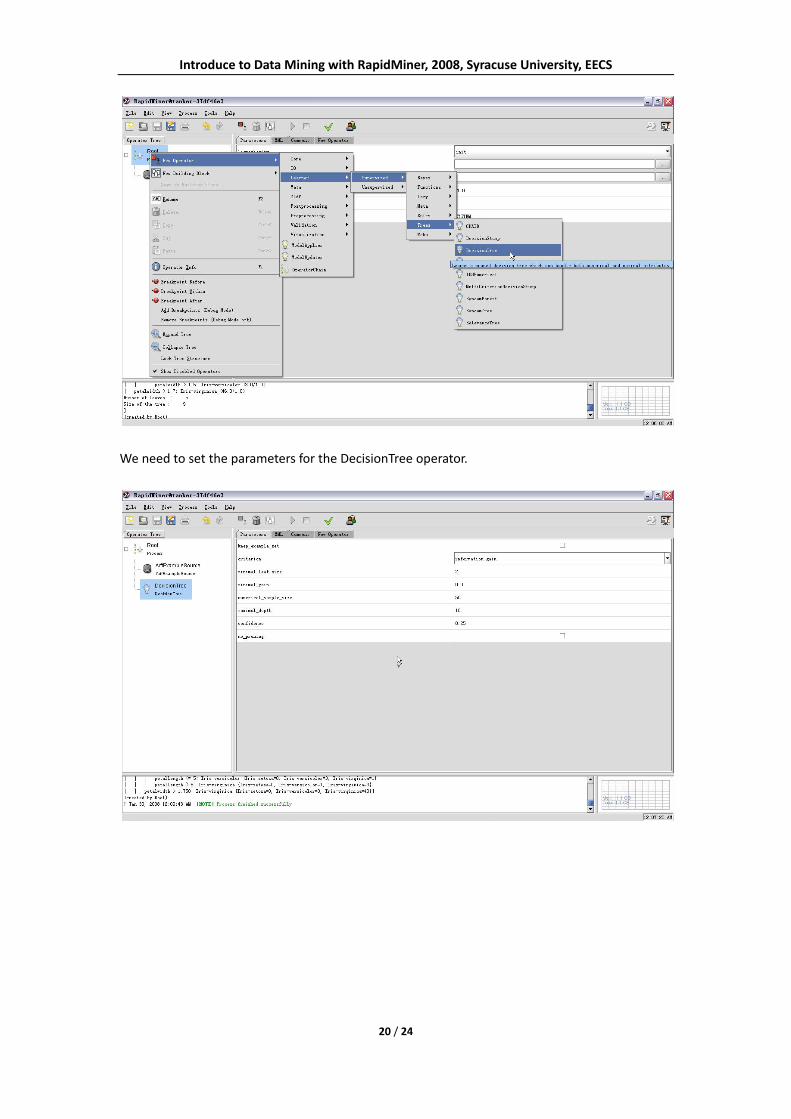
2) Classify using DecisionTree operator in RapidMiner:
We can choose New Operator ‐> Learner ‐> Supervised ‐> Tress ‐> DecisionTree to create a
DecisionTree operator.
Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
20 / 24
We need to set the parameters for the DecisionTree operator.

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
21 / 24
Click the Run Button to analysis our data to develop decision tree.
There are Text View and Graph View. Choose the correspond icon to display the result.
In the Graph View mode, the each color in the leaf node denotes a value of label class. As
showed above, the green denotes Iris‐versicolor; the blue denotes Iris‐setosa, the red denotes
Iris‐virginica.
If a node has two or three color in it, that means the ratio of error in that node.
For example : , means there 25% Iris‐versicolor (green) are classified to Iris‐virginica
(red) by mistake.

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
22 / 24
4. Association Rules
RapidMiner can do the association rules like WEKA and MineSet. Because We cannot use the
number value to do the association rules, we use the weather.nominal dataset instead of IRIS to
see how to use the association rules in RapidMiner.
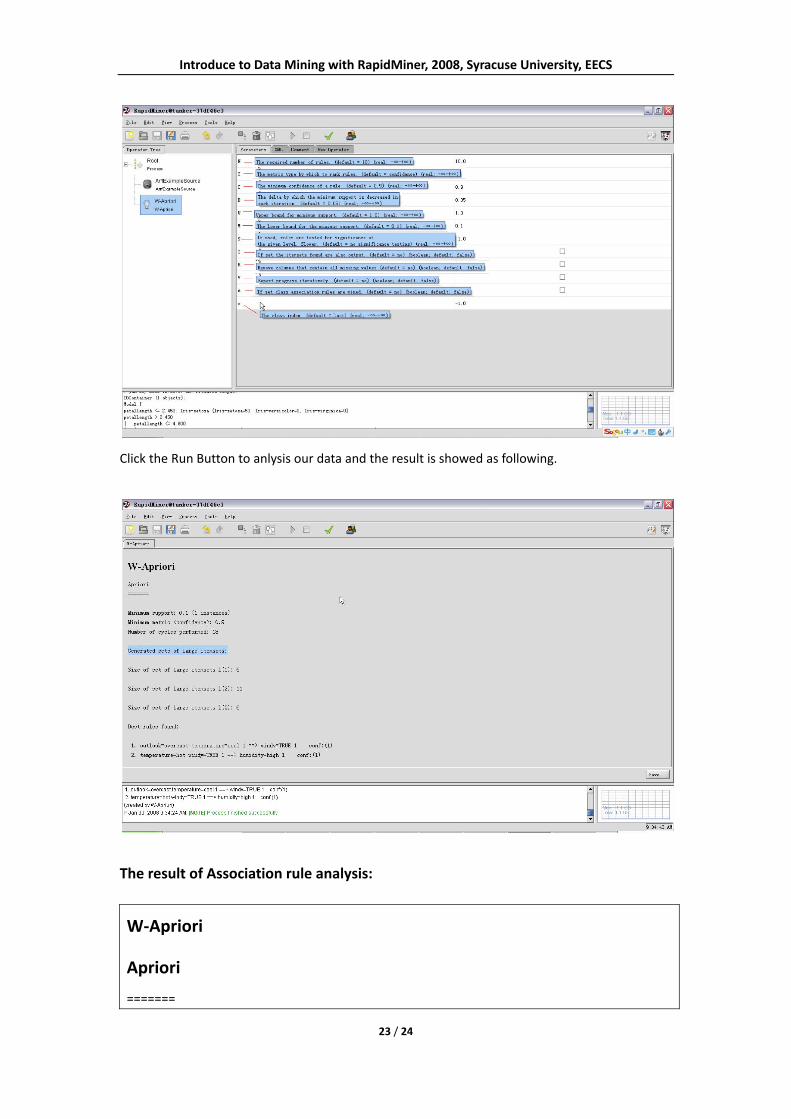
After create a AriffExampleSource operator and open the weather.nominal.arff file, we can
choose New Operator ‐> Learner ‐> Unsupervised ‐> Itemsets ‐> Wake ‐> W‐Apriori to create the
W‐Apriori operator.
Choose the W‐Apriori operator to set the parameters.
Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
23 / 24
Click the Run Button to anlysis our data and the result is showed as following.
The result of Association rule analysis:
W‐Apriori
Apriori
=======

Introduce to Data Mining with RapidMiner, 2008, Syracuse University, EECS
24 / 24
Minimum support: 0.1 (1 instances)
Minimum metric <confidence>: 0.9
Number of cycles performed: 18
Generated sets of large itemsets:
Size of set of large itemsets L(1): 7
Size of set of large itemsets L(2): 16
Size of set of large itemsets L(3): 13
Size of set of large itemsets L(4): 3
Best rules found:
1. outlook=rainy play=no 2 ==> windy=TRUE 2 conf:(1)
2. outlook=rainy windy=TRUE 2 ==> play=no 2 conf:(1)
3. temperature=hot play=no 2 ==> humidity=high 2 conf:(1)
4. outlook=overcast temperature=cool 1 ==> windy=TRUE 1 conf:(1)
5. temperature=cool play=no 1 ==> outlook=rainy 1 conf:(1)
6. temperature=hot windy=TRUE 1 ==> humidity=high 1 conf:(1)
7. temperature=hot windy=TRUE 1 ==> play=no 1 conf:(1)
8. temperature=cool play=no 1 ==> windy=TRUE 1 conf:(1)
9. temperature=cool windy=TRUE play=no 1 ==> outlook=rainy 1 conf:(1)
10. outlook=rainy temperature=cool play=no 1 ==> windy=TRUE 1 conf:(1)
The result discovers elements that co‐occur frequently within the Weather dataset and shows
some rules , such as implication or correlation, which relate co‐occurring elements.
5. Reference Books
RapidMiner Tutorial Guide
RapidMiner GUI Manual