the path to exascale computing - nvidiaimages.nvidia.com/events/...exascale-computing.pdf · bill...
TRANSCRIPT

Bill Dally
Chief Scientist and Senior Vice President of Research
THE PATH TO EXASCALE COMPUTING
2
The Goal: Sustained ExaFLOPs on problems of interest

3
Exascale Challenges
Energy efficiency
Programmability
Resilience
Sustained performance on real applications
Scalability

4
NVIDIA’s ExaScale Vision
Energy efficiency
Hybrid architecture, efficient architecture, aggressive circuits, data locality
Programmability
Target-independent programming, adaptation layer, agile network, hardware
support
Resilience
Containment domains, low SDC
Sustained performance on real applications
Scalability

5
NVIDIA’s ExaScale Vision
Energy efficiency
Hybrid architecture, efficient architecture, aggressive circuits, data locality
Programmability
Target-independent programming, adaptation layer, agile network, hardware
support
Resilience
Containment domains, low SDC
Sustained performance on real applications
Scalability
6
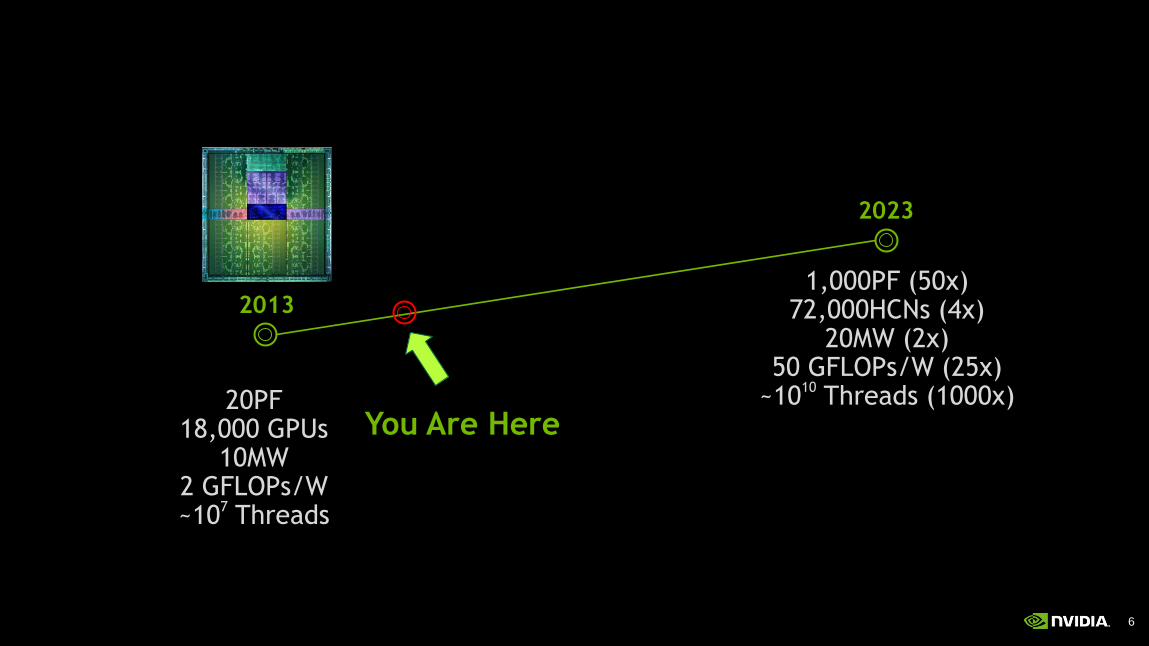
20PF 18,000 GPUs
10MW 2 GFLOPs/W ~10
7 Threads
You Are Here
1,000PF (50x) 72,000HCNs (4x)
20MW (2x) 50 GFLOPs/W (25x)
~1010 Threads (1000x)
2013
2023

7
20PF 18,000 GPUs
10MW 2 GFLOPs/W ~10
7 Threads
You Are Here
1,000PF (50x) 72,000HCNs (4x)
20MW (2x) 50 GFLOPs/W (25x)
~1010 Threads (1000x)
2013
2023
2017
CORAL 150-300PF (5-10x)
11MW (1.1x) 14-27 GFLOPs/W (7-14x)
Lots of Threads

8
Energy Efficiency

9
Its not about the FLOPs
16nm chip, 10mm on a side, 200W
DFMA 0.01mm2 10pJ/OP – 2GFLOPs
A chip with 104 FPUs:
100mm2
200W
20TFLOPS
Pack 50,000 of these in racks
1EFLOPS
10MW

10
Overhead
Locality
11
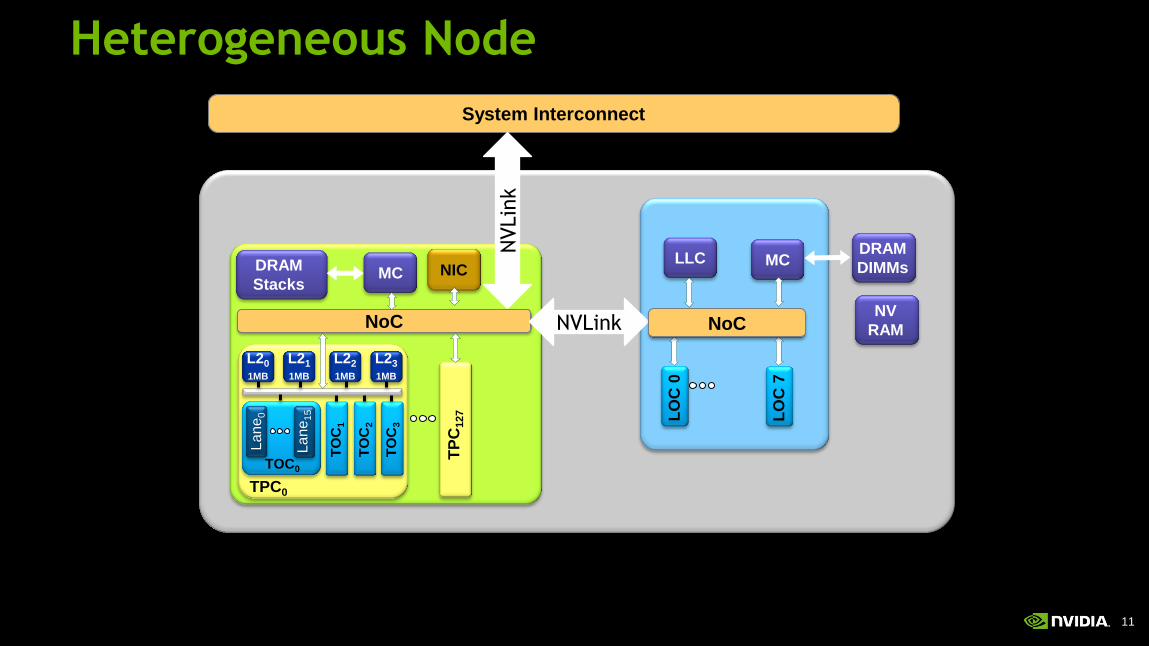
Heterogeneous Node
System Interconnect
NoC
MC NIC
LO
C 0
LO
C 7
DRAM
Stacks
TO
C1
TO
C2
TO
C3
TOC0
Lane
15
Lane
0
TPC0
L20
1MB
L21
1MB
L22
1MB
L23
1MB
TP
C127
NVLin
k
NVLink NoC
MC
DRAM
DIMMs LLC
NV
RAM

12
CPU 130 pJ/flop (Vector SP)
Optimized for Latency
Deep Cache Hierarchy
Haswell 22 nm
GPU 30 pJ/flop (SP)
Optimized for Throughput
Explicit Management of On-chip Memory
Maxwell 28 nm

13
CPU 2nJ/flop (Scalar SP)
Optimized for Latency
Deep Cache Hierarchy
Haswell 22 nm
GPU 30 pJ/flop (SP)
Optimized for Throughput
Explicit Management of On-chip Memory
Maxwell 28 nm
14
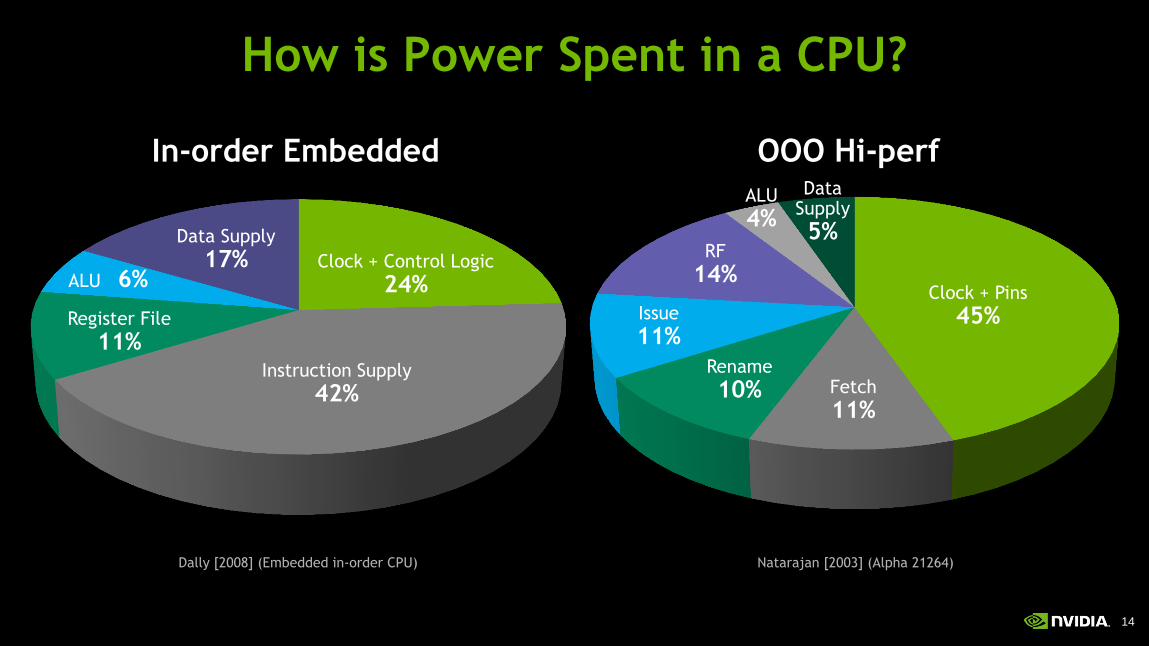
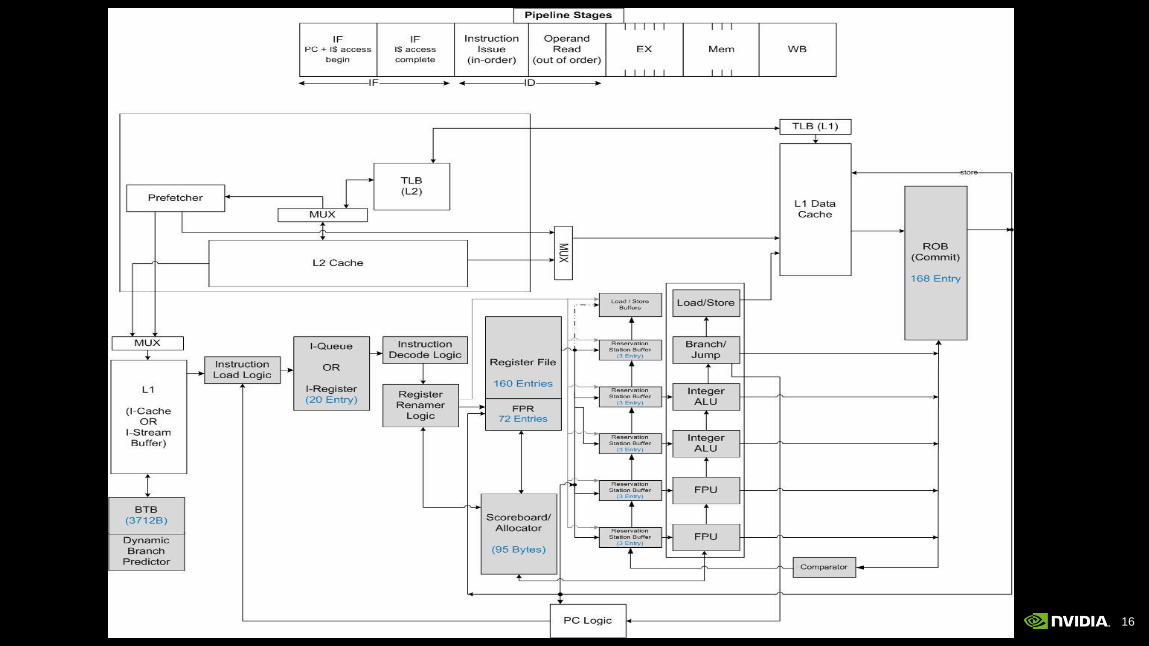
How is Power Spent in a CPU?
In-order Embedded OOO Hi-perf
Clock + Control Logic
24%
Data Supply
17%
Instruction Supply
42%
Register File
11%
ALU 6% Clock + Pins
45%
ALU
4%
Fetch
11%
Rename
10%
Issue
11%
RF
14%
Data Supply
5%
Dally [2008] (Embedded in-order CPU) Natarajan [2003] (Alpha 21264)
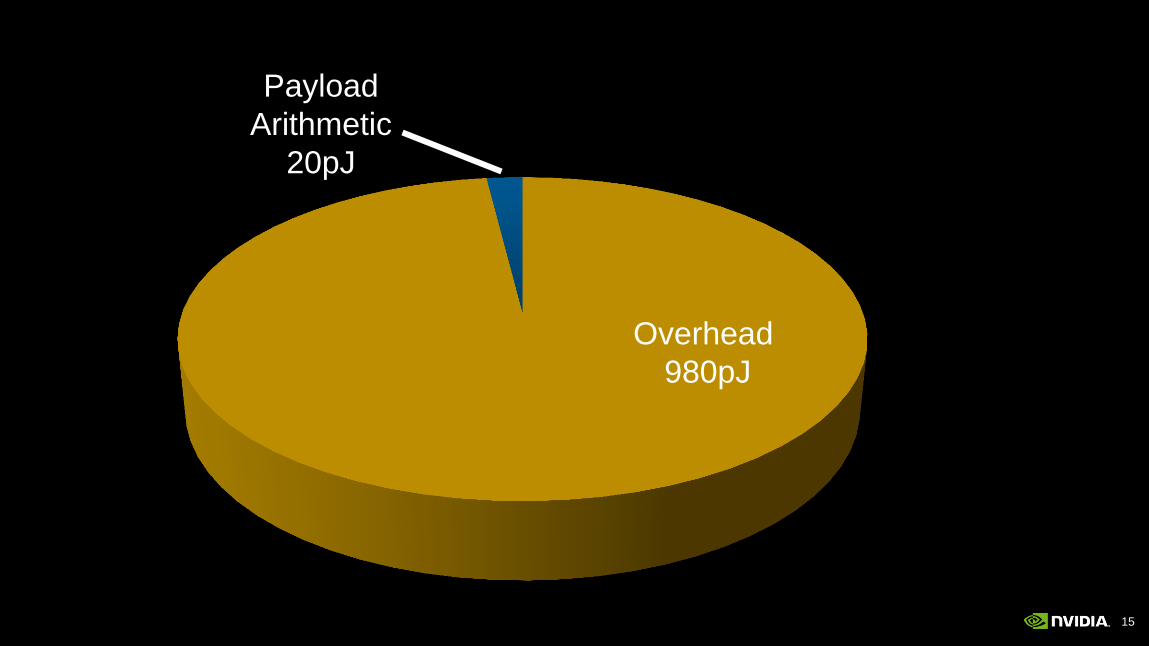
15
Overhead
980pJ
Payload
Arithmetic
20pJ
16
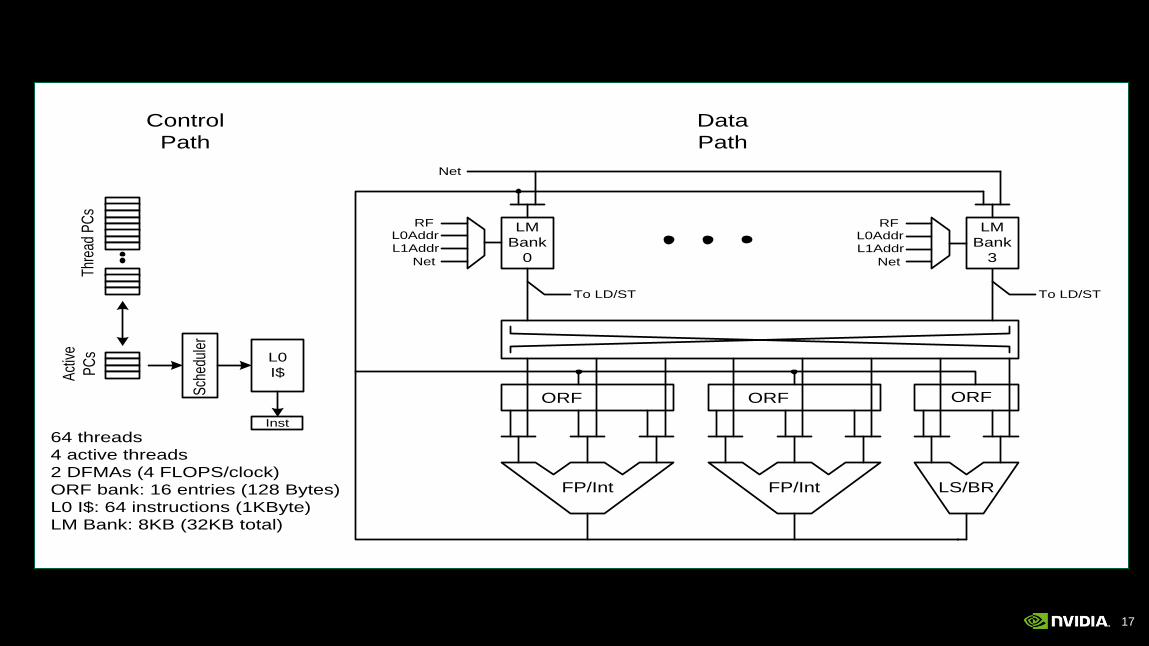
17
ORF ORFORF
LS/BRFP/IntFP/Int
To LD/ST
L0Addr
L1Addr
Net
LM
Bank
0
To LD/ST
LM
Bank
3
RFL0Addr
L1Addr
Net
RF
Net
Data
Path
L0
I$
Thre
ad P
Cs
Act
ive
PC
s
Inst
Control
Path
Sch
edul
er
64 threads
4 active threads
2 DFMAs (4 FLOPS/clock)
ORF bank: 16 entries (128 Bytes)
L0 I$: 64 instructions (1KByte)
LM Bank: 8KB (32KB total)
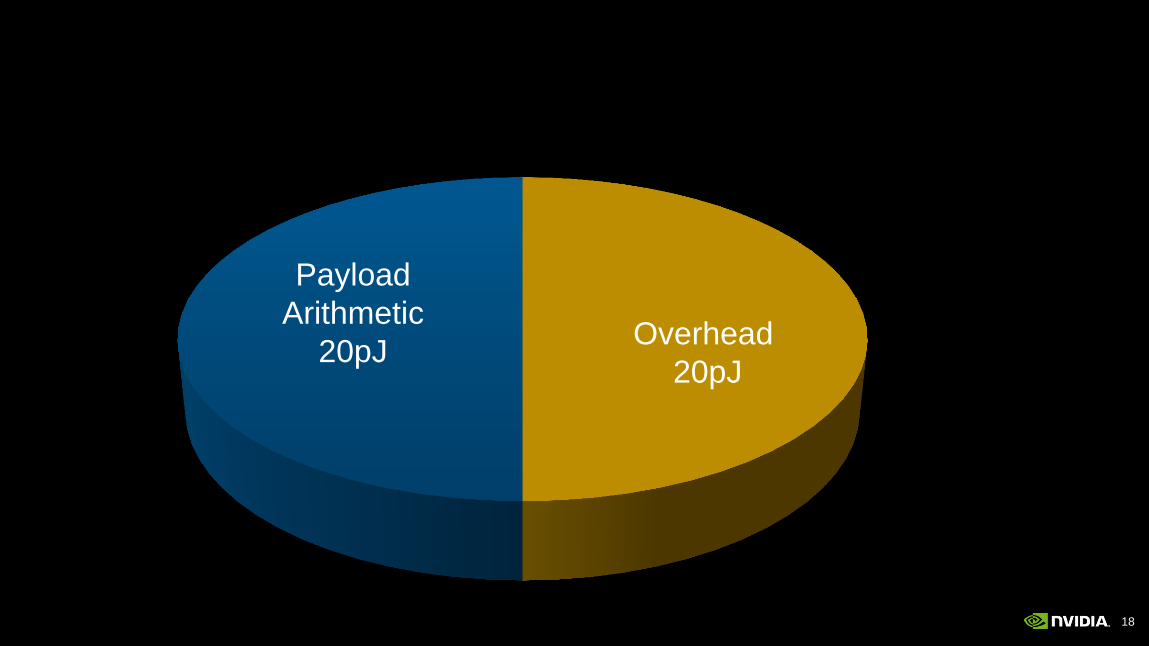
18
Overhead
20pJ
Payload
Arithmetic
20pJ

19
Energy-Efficient Architecture
See Steve Keckler’s Booth Talk – Wednesday 2:30PM
How to reduce energy 10x when process gives 2x
Do Less Work
Eliminate redundancy, waste, and overhead
Move fewer bits – over less distance
Move data more efficiently
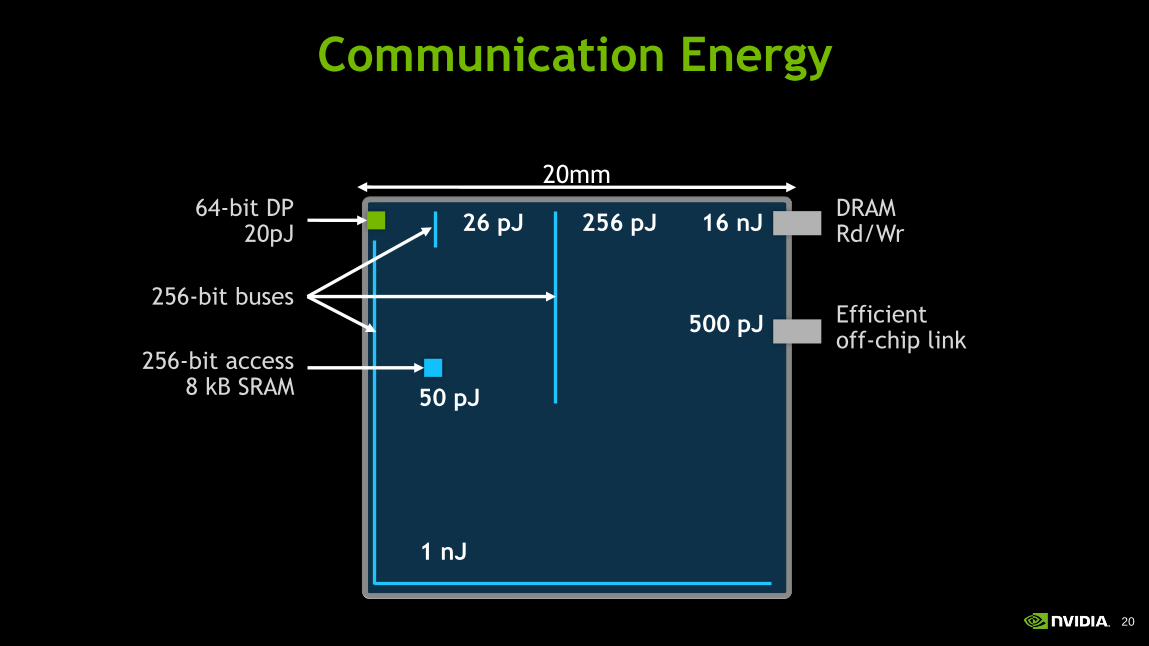
20
64-bit DP 20pJ 26 pJ 256 pJ
1 nJ
500 pJ Efficient off-chip link
256-bit buses
16 nJ DRAM Rd/Wr
256-bit access 8 kB SRAM 50 pJ
20mm
Communication Energy
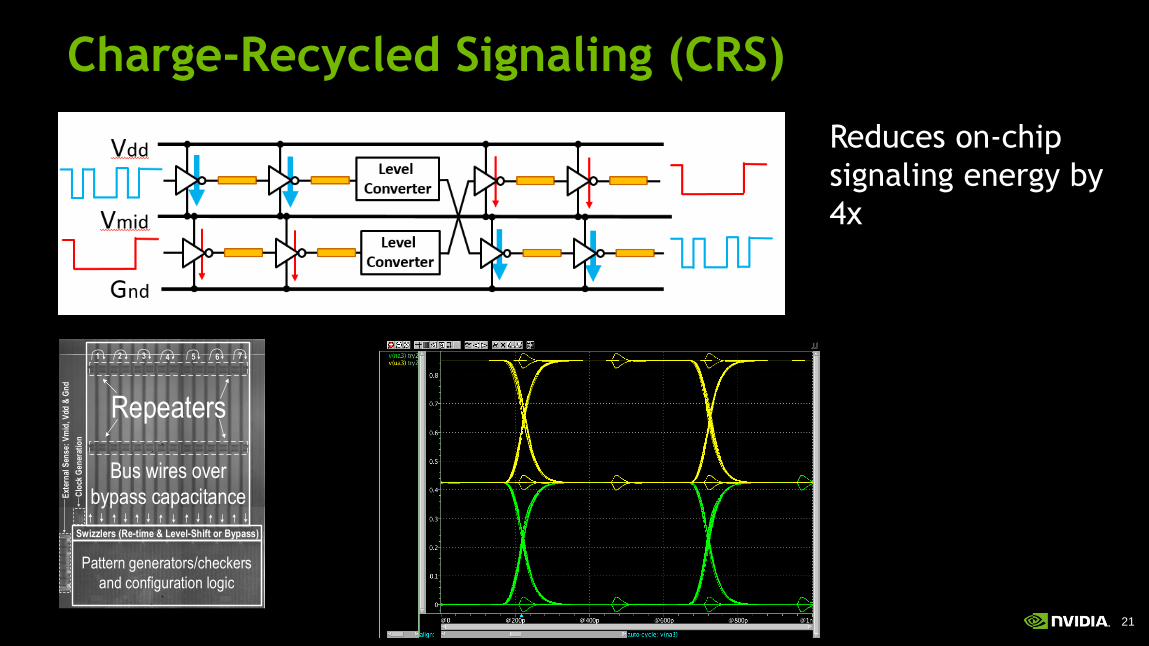
21
Charge-Recycled Signaling (CRS)
Repeaters
Swizzlers (Re-time & Level-Shift or Bypass)
Pattern generators/checkers
and configuration logic
Bus wires over
bypass capacitanceExt
ern
al S
ens
e: V
mid
, Vd
d &
Gn
d
Clo
ck G
en
erat
ion
1 2 3 4 5 6 7
Reduces on-chip
signaling energy by
4x

22
Ground-Referenced Signaling (GRS)
Probe Station
Test Chip #1 on Board
Test Chip #2 fabricated on production GPU
Eye Diagram from Probe Poulton et al. ISSCC 2013, JSSCC Dec 2013

23
Programmability
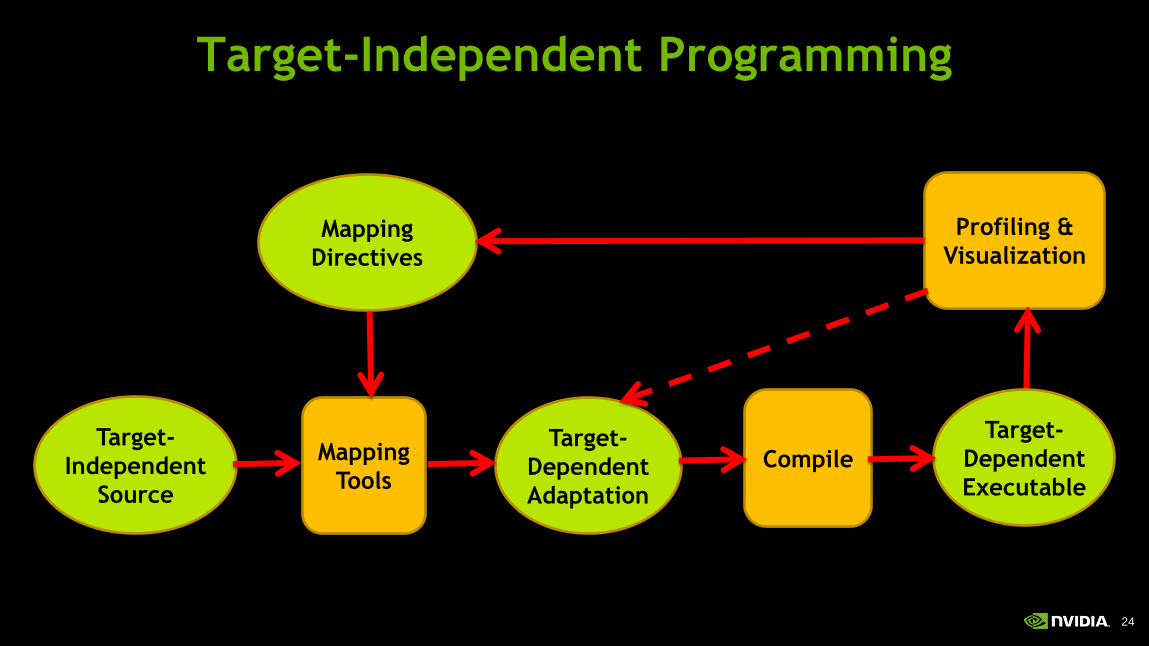
24
Target-
Independent
Source
Mapping
Tools
Target-
Dependent
Adaptation
Profiling &
Visualization Mapping
Directives
Compile
Target-
Dependent
Executable
Target-Independent Programming
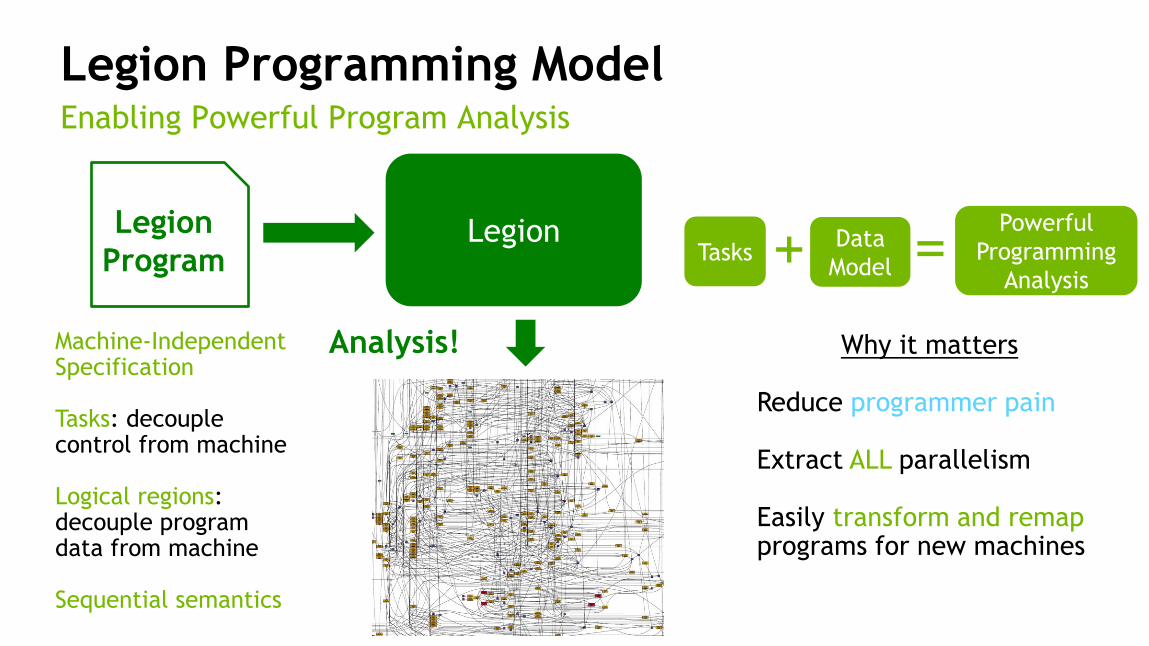
25
Legion Programming Model Enabling Powerful Program Analysis
Legion
Program
Machine-Independent Specification Tasks: decouple control from machine Logical regions: decouple program data from machine Sequential semantics
Legion
Analysis! Why it matters Reduce programmer pain Extract ALL parallelism Easily transform and remap programs for new machines
Tasks + Data
Model = Powerful
Programming
Analysis
26
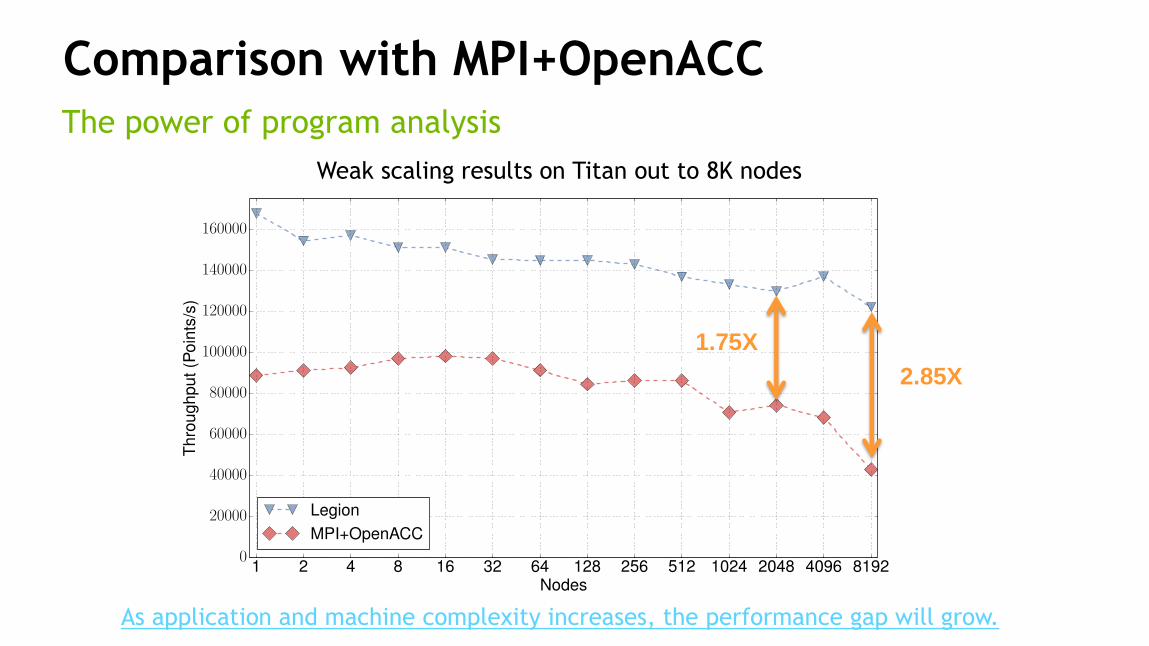
Comparison with MPI+OpenACC
The power of program analysis
1.75X
2.85X
Weak scaling results on Titan out to 8K nodes
As application and machine complexity increases, the performance gap will grow.

27
Scalability
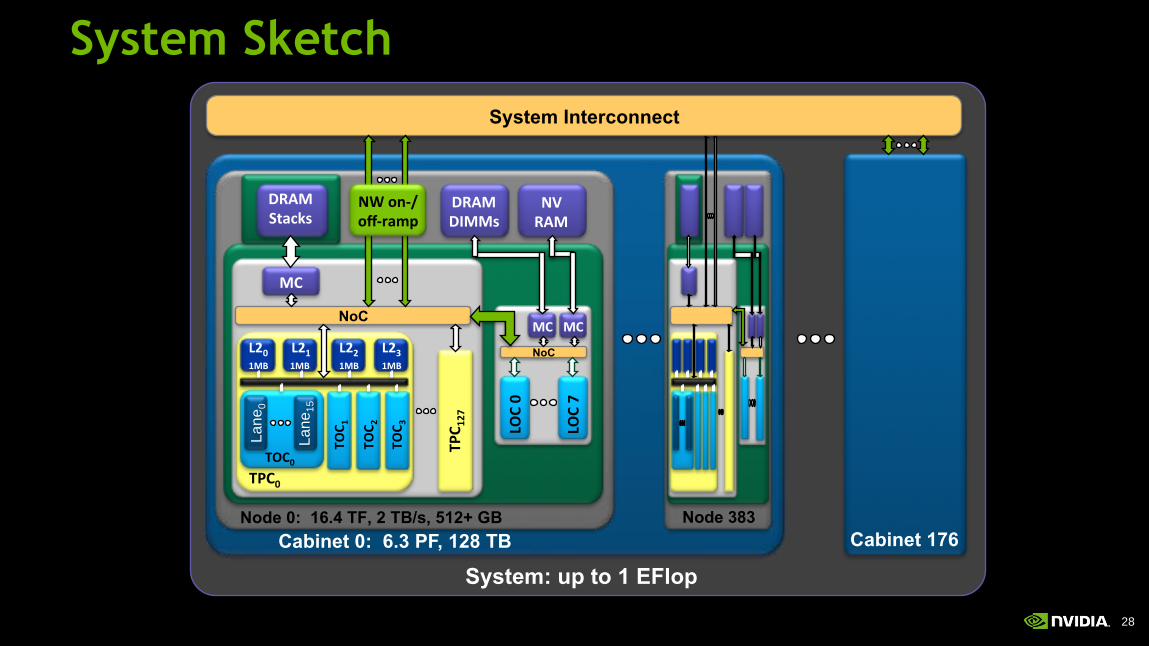
28
System Sketch
System Interconnect
Cabinet 0: 6.3 PF, 128 TB
System: up to 1 EFlop
Cabinet 176
Node 383
DRAMDIMMs
NVRAM
Node 0: 16.4 TF, 2 TB/s, 512+ GB
NoC
TOC1
TOC2
TOC3
TOC0
Lan
e1
5
Lan
e0
TPC0
L201MB
L211MB
L221MB
L231MB
TPC127
MC
NoC
LOC0
LOC7
MC MC
DRAMStacks
NWon-/off-ramp

29
Heterogenous Network Requirements
GPUs present unique requirements on network
104 – 105 threads initiating transactions
Can saturate 150GB/s NVLINK bandwidth
In addition to HPC requirements not met by commodity networks
Scalable BW up to 200GB/s per endpoint
<1us end-to-end latency at 16K endpoints
Scale to 128K endpoints
Load balanced routing
Congestion control
Operations: Load/Store, Atomics, Messages, Collectives
30
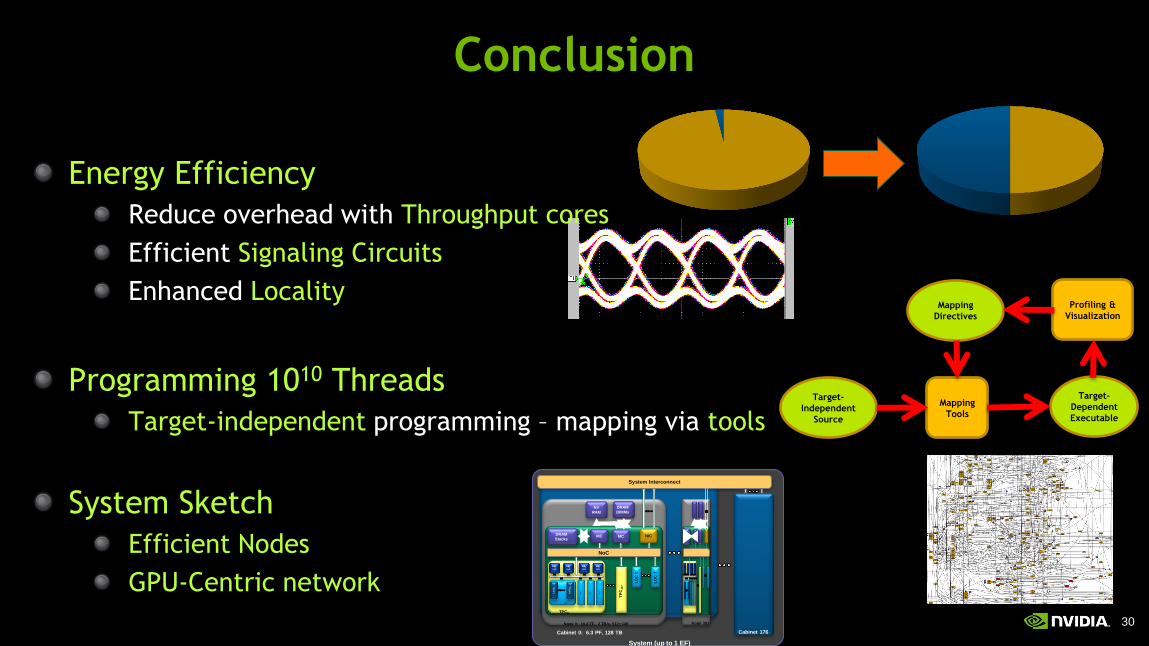
Conclusion
Energy Efficiency
Reduce overhead with Throughput cores
Efficient Signaling Circuits
Enhanced Locality
Programming 1010 Threads
Target-independent programming – mapping via tools
System Sketch
Efficient Nodes
GPU-Centric network
Target-
Independent
Source
Mapping
Tools
Target-
Dependent
Executable
Profiling &
Visualization Mapping
Directives
System Interconnect
Cabinet 0: 6.3 PF, 128 TB
System (up to 1 EF)
Cabinet 176
NoC
MC NIC
LO
C 0
LO
C 7
DRAM
Stacks
DRAM
DIMMs NV
RAM
Node 0: 16.4 TF, 2 TB/s, 512+ GB
TO
C1
TO
C2
TO
C3
TOC0
Lane
15
Lane
0
TPC0
L20
1MB
L21
1MB
L22
1MB
L23
1MB
TP
C127
MC
Node 383
31
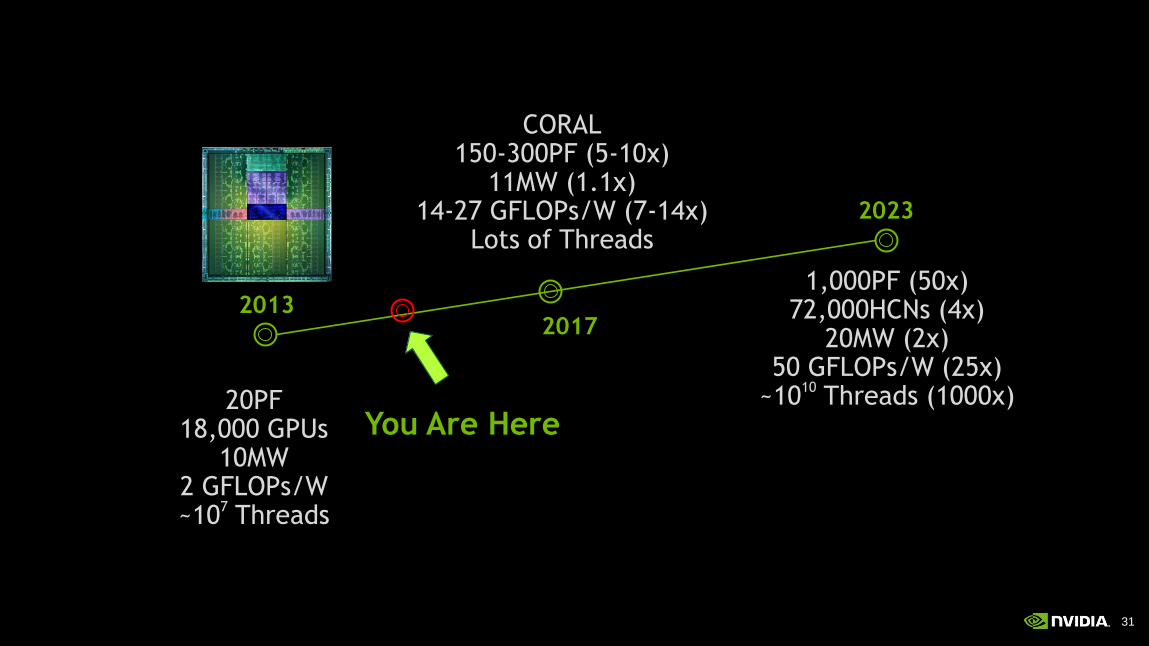
20PF 18,000 GPUs
10MW 2 GFLOPs/W ~10
7 Threads
You Are Here
1,000PF (50x) 72,000HCNs (4x)
20MW (2x) 50 GFLOPs/W (25x)
~1010 Threads (1000x)
2013
2023
2017
CORAL 150-300PF (5-10x)
11MW (1.1x) 14-27 GFLOPs/W (7-14x)
Lots of Threads

32