an efficient network-on-chip (noc) based multicore
TRANSCRIPT

1 1
An Efficient Network-on-Chip (NoC) based Multicore
Platform for Hierarchical Parallel Genetic Algorithms
Yuankun Xue1, Zhiliang Qian2, Guopeng Wei3,
Paul Bogdan1, Chi-Ying Tsui2 , Radu Marculescu3 1University of Southern California
2HKUST, 3Carnegie Mellon University
Symposium on Network-on-Chips, Sept., 2014

Outline
q Introduction q Genetic Algorithm (GA) overview q Hierarchical Parallel Genetic Algorithms (HPGA)
q NoC-based HPGA platform q Island-based HPGA-NoC q Performance bottleneck analysis q Proposed HPGA architecture
q Dynamic Injection Bandwidth Multiplexing (DIBM) q Time-division Island Multiplexing (TIDM) q Task-aware adaptive routing
q Experimental results q Conclusions
2

Genetic Algorithm
q Genetic algorithm (GA) overview
3
Fitness function-based individual
selection
Parent Population
Produced new individuals
(S ) (S )i iP Fit∝Si Sj
Crossover
Mutation Mutation
Genetic operations
mimic natural evolution
Master process (GA phase)
Slave process (DIS phase)
Fitness calculation
Produce new Generation
Individuals distribution

Example - Protein Folding Problem
q Protein final conformation corresponds to the minimal energy state
q Fitness function based on 3DHPSC model q 6 contacts from set {BB,BH,BP,HP,HH,PP}
are considered q Assume unity distance in cubic lattice q Penalty introduced for overlapped position
4
q Protein folding problem in the experiments
BH Contact
BB Contact
PP Contact
HH Contact
HP Contact
BP Contact
1, 1 1, 1 1, 1
1, 1 1, 1 1, 1
*
hh hb bbij ij ij
bp pp hpij ij ij
N N N
hh hb bbr r ri j i i j i i j i
N N N
bp pp hpr r ri j i i j i i j i
Fitness H N PenaltyValue
H e e e
e e e
δ δ δ
δ δ δ
= > + = > + = > +
= > + = = + = = +
= −
= + +
+ + +
∑ ∑ ∑
∑ ∑ ∑
lme : Contact weight, l,m=B,H,P
𝛿↓𝑟↓𝑖𝑗↑𝑙𝑚
= 1 : if (i,j) contact exists
0 : otherwise

Parallel Genetic Algorithm
q The computation time of GA grows dramatically with the problem size
q Parallel Genetic Algorithm (PGA) q Single-master multiple-slave based GA platform [E. Cantu 1998] q Multiple-master mutiple-slave based GA (HPGA) [E. Cantu 1998]
5
Master process
Slave process 1
Slave process 2
Slave process 3
Slave process n
Fitness return flowIndividual
distribution flow
a) b)
Island
Master process
Slave process
Migration flow among masters

Implementation of PGA
q Previous PGA implementations q Computer-cluster based PGA [C.Benitez, 2009]
q A single master process with multiple slave processes q Speedup tends to saturate as the process in the single master
cannot be parallel
q GPU-based architecture [P.Pospichal et.al, 2010]
q The migration among master processes need to be compatible with CUDA software model
q NoC-based MPSoC platform [R.Ferreira et.al, 2010]
q Migration only occur among neighboring islands
q Motivation of this work q Dedicated NoC architecture supporting dynamic migrations q Time-division multiplexing (TDM) schemes with higher
utilization of the processing elements 6

Outline
q Introduction q Genetic Algorithm (GA) overview q Hierarchical Parallel Genetic Algorithms (HPGA)
q NoC-based HPGA platform q Island-based HPGA-NoC q Performance bottleneck analysis q Proposed HPGA architecture
q Dynamic Injection Bandwidth Multiplexing (DIBM) q Time-division Island Multiplexing (TIDM) q Task-aware adaptive routing
q Experimental results q Conclusions
7

Island-based HPGA-NoC
q Straight forward implementation q Mapping multiple islands onto NoC
8
a)
M
S S S S
S S S S
S S S
S S S S
Master process
Slave process
b)
M Master processor
S Slave processor
Router
Fitness return flowIndividual
distribute flow
Operations for each island
Migrations among the islands
Master 3 Master 2
Master 0 Master 1
Hierarchical network for islands

Performance Bottleneck Analysis q Limited injection bandwidth of the master
processor – (limitation 1) q Every cycle, only one flit can be sent from the master to a
slave in each island q Low utilization of slave cores – (limitation 2)
9
Breakdown of distribution and fitness calculation times [Y.-k.Xue, DAC,2014]
Ratio of DIS phase (using slave processors for calculation) to GA (slave processors are idle) phase
Limitation 1 Limitation 2

Outline
q Introduction q Genetic Algorithm (GA) overview q Hierarchical Parallel Genetic Algorithms (HPGA)
q NoC-based HPGA platform q Island-based HPGA-NoC q Performance bottleneck analysis q Proposed HPGA architecture
q Dynamic Injection Bandwidth Multiplexing (DIBM) q Time-division Island Multiplexing (TIDM) q Task-aware adaptive routing
q Experimental results q Conclusions
10
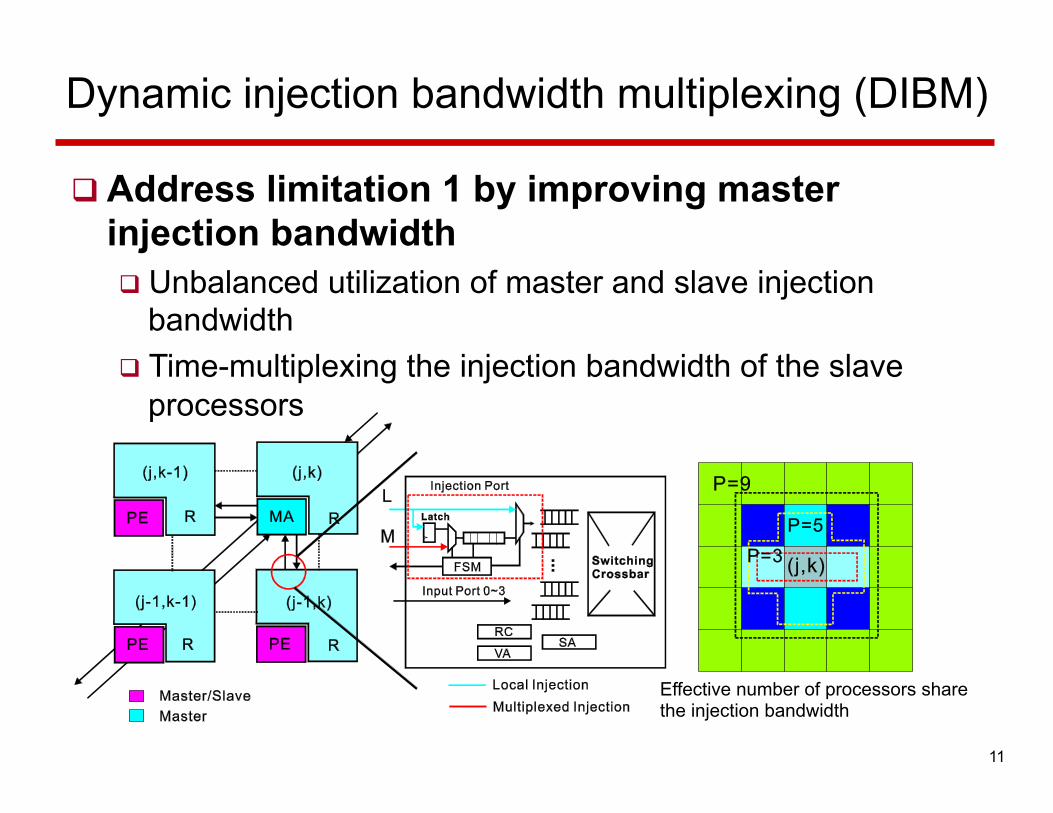
Dynamic injection bandwidth multiplexing (DIBM)
q Address limitation 1 by improving master injection bandwidth q Unbalanced utilization of master and slave injection
bandwidth q Time-multiplexing the injection bandwidth of the slave
processors
11
Effective number of processors share the injection bandwidth

Time-division island multiplexing (TDIM) scheme
q Address limitation 2 by improving the slave processor’s utilization q Time-sharing the GA phase
q The slave idle time in one island can be used to calculate the individual fitness of other islands
12
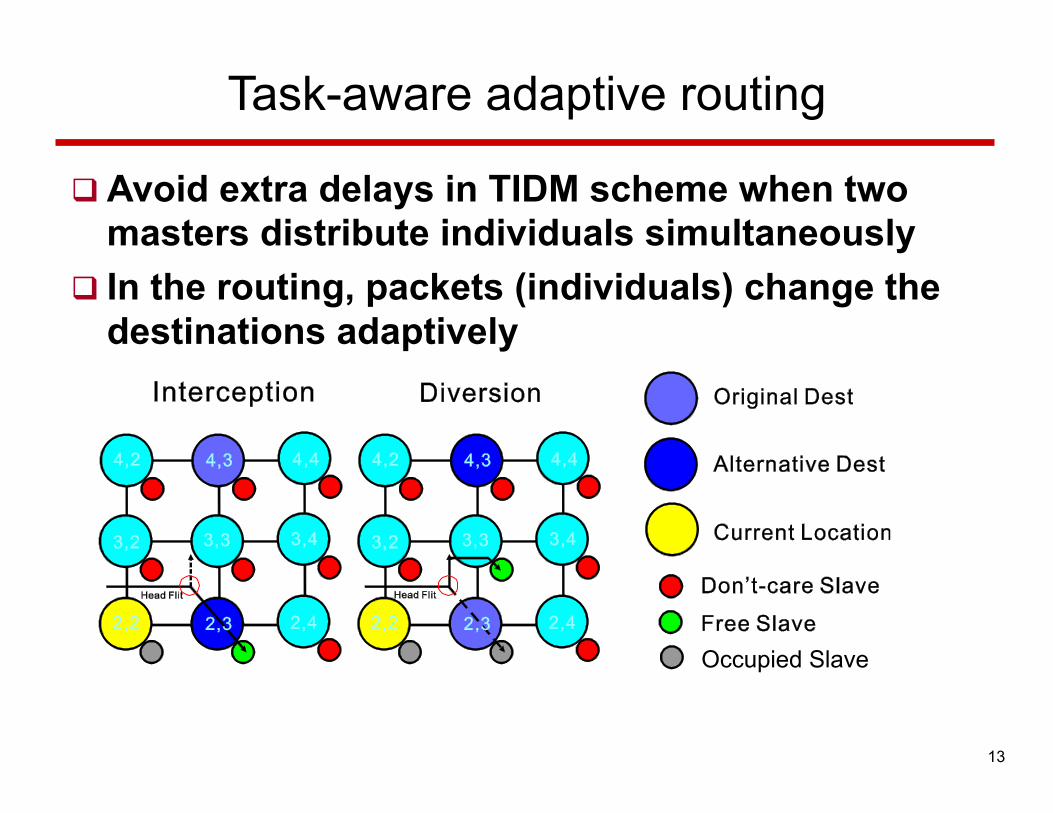
Task-aware adaptive routing
q Avoid extra delays in TIDM scheme when two masters distribute individuals simultaneously
q In the routing, packets (individuals) change the destinations adaptively
13
Occupied Slave

Task-aware adaptive routing (Cont.)
q Adaptive routing flow:
14
Initial destination Set for chromosome packet in the master processor
chromosome packet sent through XY routing
In intermediate router
Check the availability of slave processor
Delivery chromosome to current PE
Free slave && Granted usage Not free slave PE
Proceed to next hop
Reach the destination Original
destination
Check availability of the destination slave processor

Outline
q Introduction q Genetic Algorithm (GA) overview q Hierarchical Parallel Genetic Algorithms (HPGA)
q NoC-based HPGA platform q Island-based HPGA-NoC q Performance bottleneck analysis q Proposed HPGA architecture
q Dynamic Injection Bandwidth Multiplexing (DIBM) q Time-division Island Multiplexing (TIDM) q Task-aware adaptive routing
q Experimental results q Conclusions
15

Experimental results
q Simulation setup q The HPGA-NoC platform is implemented in C++ q The protein folding problem with 3D HPSC model is
considered for the GA problem q Parameters for the GA simulations:
q 2000 generations with a population size 2400 q Crossover rate 80% and mutation rate 20% q Migration happens among masters every 40 generations
q NoC network size ranges from 2×2 to 16×16 q Buffer depth of 4 flits and 4 virtual channels q Master processor sends the multi-flit chromosome packets
and slave processor returns a single flit fitness packet
16

Comparisons of speedup performance
q We compare the speedup gain of the baseline design and the proposed architecture with DIBM
q Various degree of injection bandwidth multiplexing is considered (P=3 to P=9)
17
q Upperbound is obtained by theoretical derivation considering level of multiplexing
q For baseline design (naïve mesh), the speedup tends to saturate early as two types of limitations exist
q For NoC with DIBM, a 75X-206X speedup can be obtained

Evaluation of TDIM schemes
q Comparisons of slave process utilization by TDIM schemes
18
q Core utilization in baseline (naïve mesh) drops significantly
q TDIM schemes efficiently improves the slave cores’ utilization as the number of slave processor increases

Evaluation of TDIM schemes (Cont.)
q Maximum number of islands that can be multiplexed on a physical island
q Impact of island multiplexing number on the overall speedup performance
19

Evaluation of adaptive routing
q Compare the proposed routing algorithm against XY and minimal adaptive routing
q The proposed task-aware routing effectively reduce the sojourn time of a chromosome packet
20
q Overlap ratio is the percentage of time DIS phase of two logic islands overlap
q The proposed routing algorithm achieves 10-15% reduction in the fitness calculation time

Hardware comparisons
q The hardware overhead is normalized to that of the baseline design in terms of number of processors needed
21
q The overhead grows lineally for the baseline design
q The proposed TDIM scheme greatly reduced the number of PEs and routers required by sharing the same resources in the island
q Combining DIBM, the proposed routing with TDIM further reduces the hardware requirement

Case study: Protein folding analysis
q 7 real-world protein benchmarks are used for the analysis
q We compare the proposed architecture with a single-master-single-slave design
q 24 islands are mapped onto 𝟏𝟓×𝟏𝟓 mesh NoC q The solution is represented by the H-H side-chain
contacts (HH)
22

Outline
q Introduction q Genetic Algorithm (GA) overview q Hierarchical Parallel Genetic Algorithms (HPGA)
q NoC-based HPGA platform q Island-based HPGA-NoC q Performance bottleneck analysis q Proposed HPGA architecture
q Dynamic Injection Bandwidth Multiplexing (DIBM) q Time-division Island Multiplexing (TIDM) q Task-aware adaptive routing
q Experimental results q Conclusions
23

Conclusions
q An efficient NoC-based multicore platform for HPGA is presented with: q DBIM to overcome the master processor injection
bandwidth limitations q TDIM to improve the utilization of the slave processors and
reduce the physical network size q Adaptive routing to reduce the chromosome packet
delivery latency q We demonstrate the effectiveness of the overall
architecture and each scheme using the protein folding problem as the case study
q Future work includes detailed hardware implementation and optimization
24

q Thanks!
q Q&A
25

Evaluating DIBM on FPGA
q A DIBM-based platform is implemented in verilog with multiplexing level P=3
q The speedup is simulated based on synthesized results on Xilinx Virtex-6 LX760 FPGA
26
Performance degradation is due to the complicated control logic in the hardware prototype