missing data and data imputation techniques
TRANSCRIPT

Missing Data <NA> Imputation techniques of data in R environment
Omar F. Althuwaynee, Ph.D.

1. Understand the meaning of <NA>.2. Effectively impute missing data <NA> Learn the common
methods of data imputation.3. Become familiar with data uncertainty source(s).4. Decide wisely and scientifically the best imputation
method for your data.
Omar F. Althuwaynee, PhD in Geomatics engineering
End of this video, you will be able to

Omar F. Althuwaynee, PhD in Geomatics engineering
When information is unavailable for a cell location, the location will be assigned as NoData <NA>.
Note:NoData and 0 are not the same—0 is a valid numerical value.
• an input location can have NoData instead of a numerical value has ramifications(consequences) for how tools handle them.
• NoData means that not enough information is known about a cell location to assign it a value.
Note: important to understand how NoData is handled in a particular tool before making a decision.
NoData and how it affects analysis

There are two ways that a location with NoData can be treated in the computation of an expression:
In Mapping1. Always return NoData for that specified cell location.2. Ignore the NoData and compute with the available values for that
specified cell location.
In attributed data (records, inventory, statistics, census…etc)3. basic imputations such as replacing with 0, replacing with mean, mode
etc. 4. not versatile methods and could result into a possible data discrepancy.
NoData and how it affects analysis
Omar F. Althuwaynee, PhD in Geomatics engineering

You may need to know • if a location with nodata in the output ever had a value or if it received a
value of nodata as a result of the tool's algorithm. • if the output value really is the actual minimum or maximum value or
if it is the minimum or maximum value of the existing known values.
Note:• When adding two raster datasets together, if a cell location in one of
the datasets contains nodata, there is no basis for assigning a new value to the corresponding location on the output raster dataset.
NoData and how it affects analysis
Omar F. Althuwaynee, PhD in Geomatics engineering

• When looking for the minimum value in a neighborhood that contains a nodata value, an assumption can be made (or a risk taken) that the cell location with the nodata value will not be the minimum value. The focal operation can thus be used to return the minimum value of the remaining valid values in the neighborhood.
NoData and how it affects analysis
Omar F. Althuwaynee, PhD in Geomatics engineering
Reference:• http://resources.arcgis.com/en/help/main/10.2/index.html#/
NoData_and_how_it_affects_analysis/018700000003000000/

Omar F. Althuwaynee, PhD in Geomatics engineering
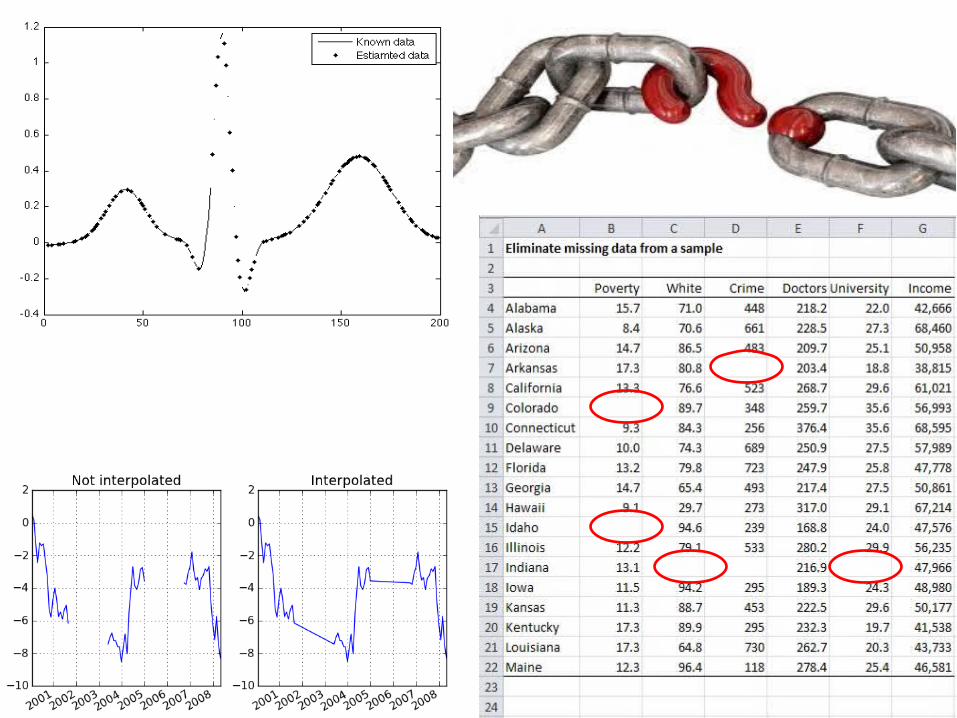
• a procedure for entering a value for a specific data item where the response is missing or unusable (https://goo.gl/BQ2ra7).
• Probability based methods, used to assign a reasonable values to an variable observations by using the rest of available samples in this specific variable (i.e Common types of interpolation methods).
1. Using information from related observations2. Indicator variables for missingness of categorical/ continous
predictors.
We will use 3 packages3. MICE4. missForest5. Hmisc
Data Imputation

Omar F. Althuwaynee, PhD in Geomatics engineering
• MICE (Multivariate Imputation via Chained Equations) Creating multiple imputations as compared to a single imputation (such as mean), takes care of uncertainty in missing values.
• MICE assumes that the missing data are Missing at Random (MAR), which means that the probability that a value is missing depends only on observed value and can be predicted using them.
• How does it work ? It imputes data on a variable by variable basis by specifying an imputation model per variable.
Data Imputation: MICE

Omar F. Althuwaynee, PhD in Geomatics engineering
• As the name suggests, missForest is an implementation of random forest algorithm. It’s a non parametric imputation method applicable to various variable types.
• Non-parametric method does not make explicit assumptions about functional form of f (any arbitary function).
• Instead, it tries to estimate f such that it can be as close to the data points without seeming impractical.
• How does it work ? it builds a random forest model for each variable. Then it uses the model to predict missing values in the variable with the help of observed values.
Data Imputation: missForest

Omar F. Althuwaynee, PhD in Geomatics engineering
• a multiple purpose package useful for data analysis, high – level graphics, imputing missing values, advanced table making, model fitting & diagnostics (linear regression, logistic regression & cox regression) etc.
• it offers 2 powerful functions for imputing missing values. 1. impute() function simply imputes missing value using user
defined statistical method (mean, max, mean). It’s default is median.
2. aregImpute() allows mean imputation using additive regression, bootstrapping, and predictive mean matching.
highlights of this package:3. It assumes linearity in the variables being predicted.4. Fisher’s optimum scoring method is used for predicting
categorical variables.
Data Imputation: Hmisc