shoal: smart allocation and replication of memory … · shoal: smart allocation and replication of...
TRANSCRIPT

Shoal: smart allocation and replication of memory for
parallel programs
Stefan Kaestle, Reto Achermann, Timothy Roscoe, Tim Harris$
ETH Zurich $Oracle Labs Cambridge, UK
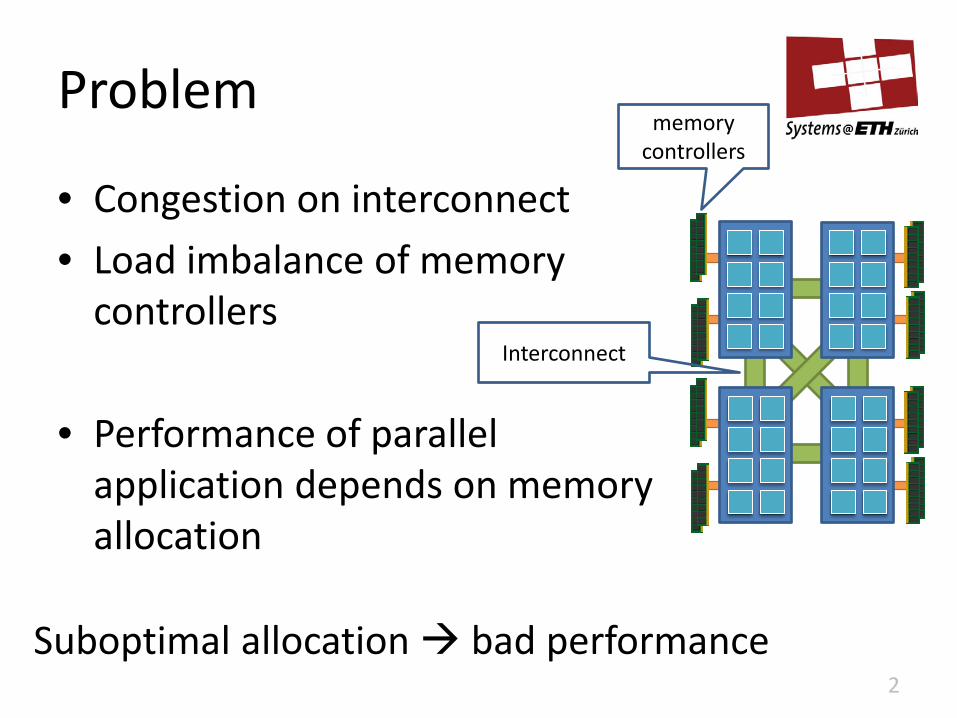
Problem
• Congestion on interconnect
• Load imbalance of memory controllers
• Performance of parallel application depends on memory allocation
2
Suboptimal allocation bad performance
memory controllers
Interconnect

Shoal
• Memory abstraction: Arrays
• Statically derive access patterns from code
• Choose array implementation at runtime
• Reduces runtime: – 4x over naïve memory allocation
3
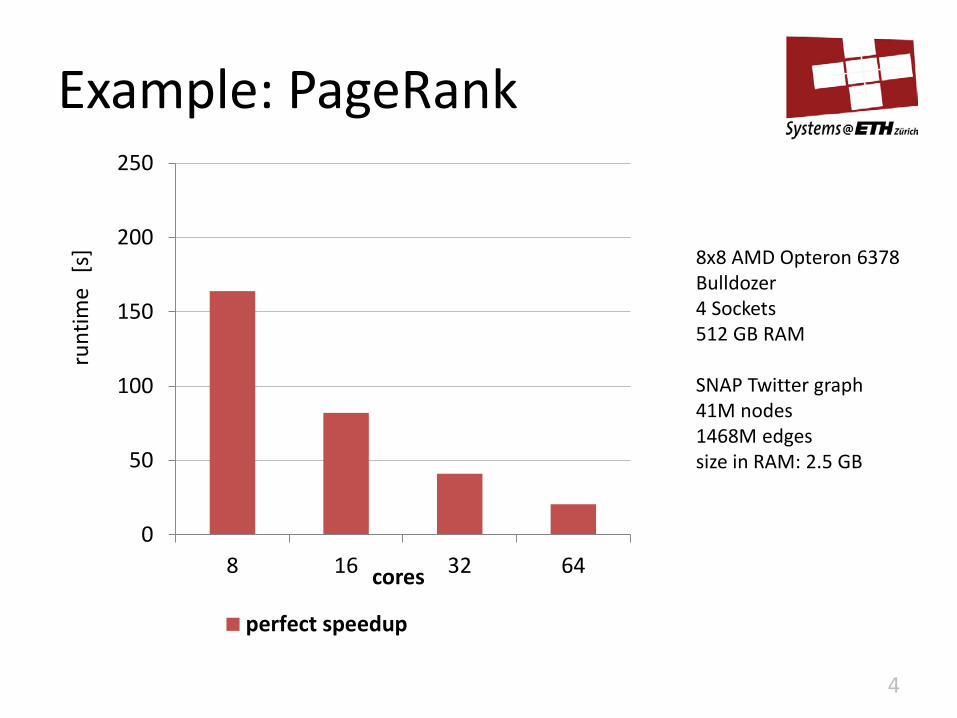
Example: PageRank
4
0
50
100
150
200
250
8 16 32 64
runt
ime
[s]
cores
perfect speedup
8x8 AMD Opteron 6378 Bulldozer 4 Sockets 512 GB RAM SNAP Twitter graph 41M nodes 1468M edges size in RAM: 2.5 GB
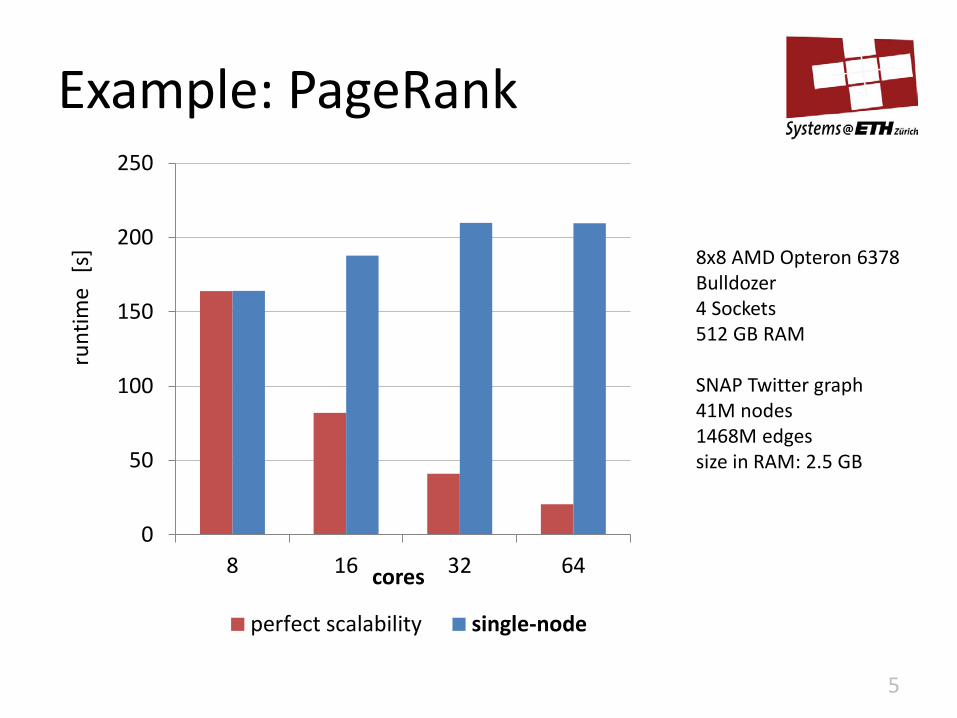
Example: PageRank
5
0
50
100
150
200
250
8 16 32 64
runt
ime
[s]
cores
perfect scalability single-node
8x8 AMD Opteron 6378 Bulldozer 4 Sockets 512 GB RAM SNAP Twitter graph 41M nodes 1468M edges size in RAM: 2.5 GB

Problem: implicit allocation
void *data = malloc(SIZE); memset(data, 0, SIZE);
• Implicit Linux policy on where to allocate memory
• First touch all memory on same NUMA node
6

What we would like to do?
• Partitioning – Split working space, put on different nodes
• Replication – Copy array – Updates: consistency
Reduce load-imbalance Localizes access reduces interconnect traffic
• DMA • 2M/1G pages
7

What we have today:
• Explicit placement of memory – libnuma
• Advise Kernel about use of memory region – madvise
8

SHOAL
9

Exploiting DSLs
• High-level API
• Efficient parallelization
• widely used – Machine learning
– Signal processing
– Graph processing
10
Idea: derive access patterns
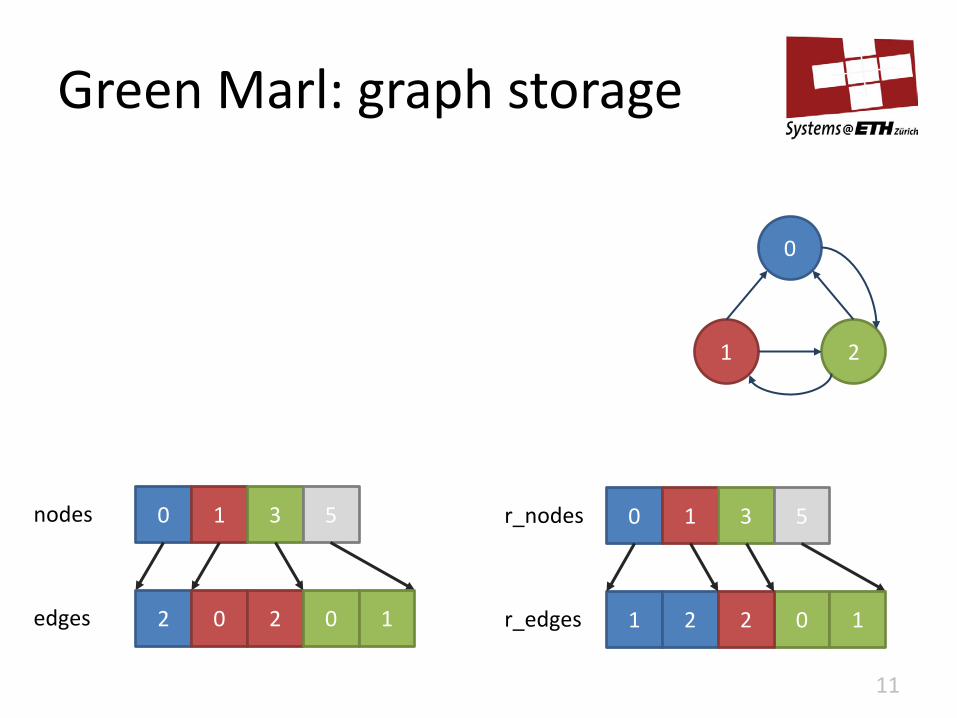
Green Marl: graph storage
11
0
1 2
nodes 0 1 3 5
2 0 2 edges 0 1 0 1 2 2 r_edges
0 1 3 r_nodes 5
1
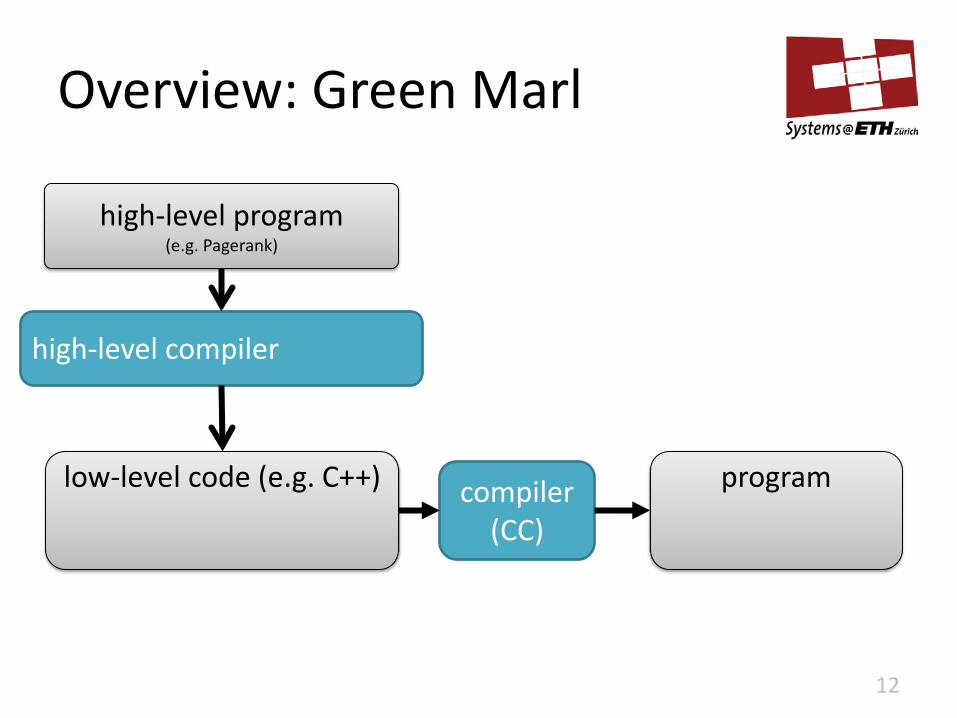
Overview: Green Marl
12
high-level program (e.g. Pagerank)
compiler (CC)
program
high-level compiler
low-level code (e.g. C++)
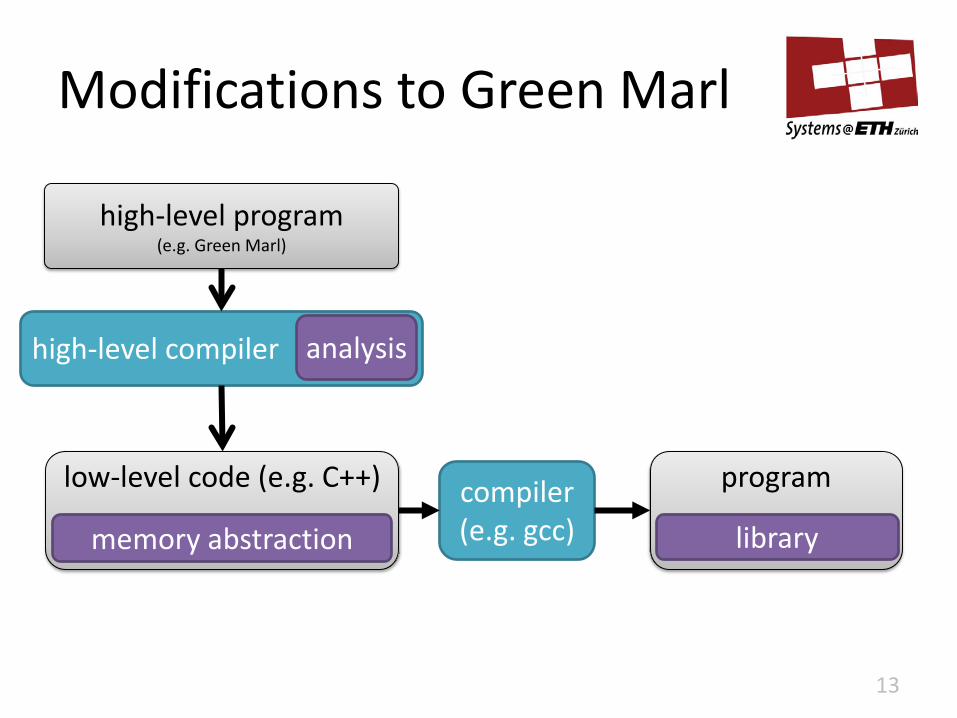
Modifications to Green Marl
13
low-level code (e.g. C++) compiler (e.g. gcc)
program
library
high-level program (e.g. Green Marl)
high-level compiler analysis
memory abstraction
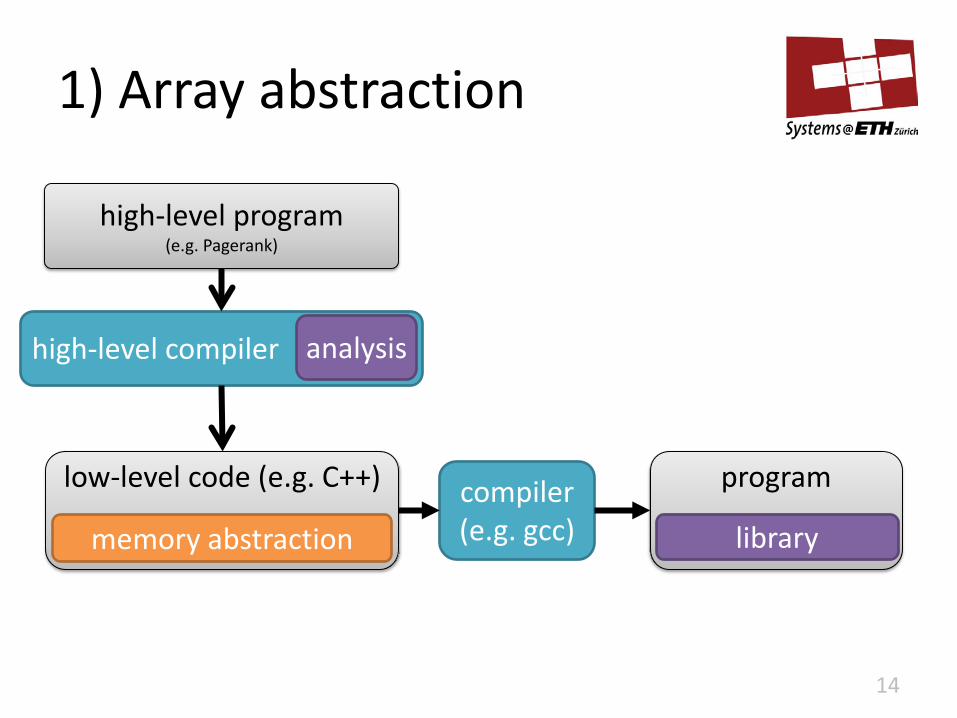
1) Array abstraction
14
low-level code (e.g. C++) compiler (e.g. gcc)
program
library
high-level program (e.g. Pagerank)
high-level compiler analysis
memory abstraction

Array abstraction
• get() and set()
• copy_from(arr) and init_with(const)
• array_malloc(size, access_patterns)
15

Shoal’s access patterns
• Read-only
• Sequential
• Random
• Indexed
16
indexed: for (i=0; i<SIZE; i++) { foo(arr[i]); } sequential + local
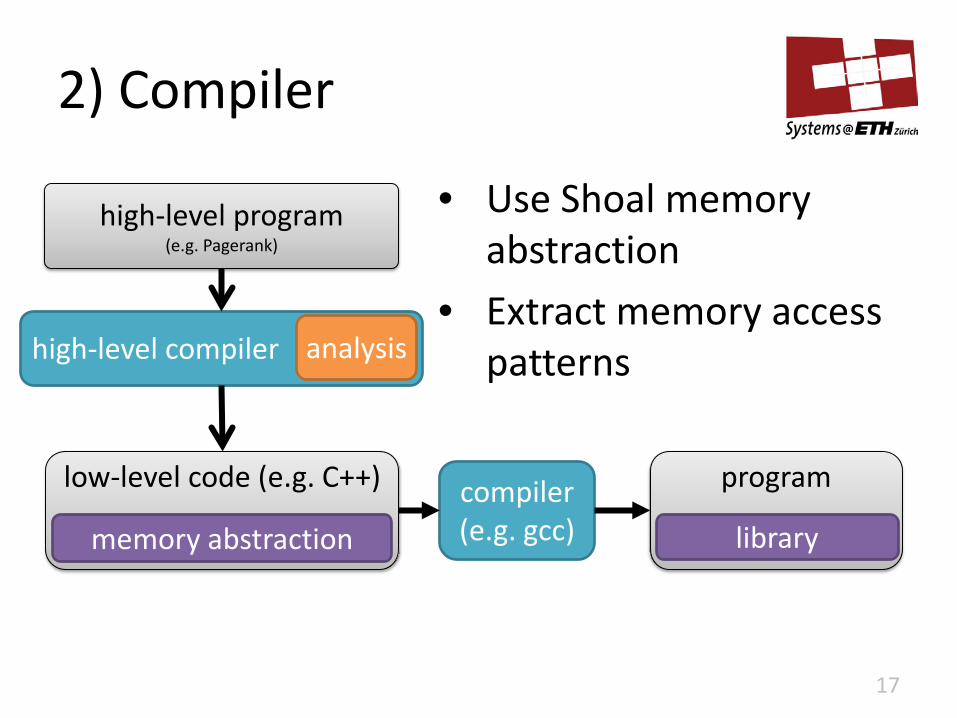
2) Compiler
17
low-level code (e.g. C++) compiler (e.g. gcc)
program
library
high-level program (e.g. Pagerank)
high-level compiler analysis
memory abstraction
• Use Shoal memory abstraction
• Extract memory access patterns

Derivation of access patterns
18
Foreach (t: G.Nodes) { Double val = k * Sum(nb: t.InNbrs){ nb.rank / nb.OutDegree()} ; diff += | val - t.pg_rank |; t.pg_rank <= val @ t; }

Derivation of access patterns
19
Foreach (t: G.Nodes) { Double val = k * Sum(nb: t.InNbrs){ nb.rank / nb.OutDegree()} ; diff += | val - t.pg_rank |; t.pg_rank <= val @ t; }
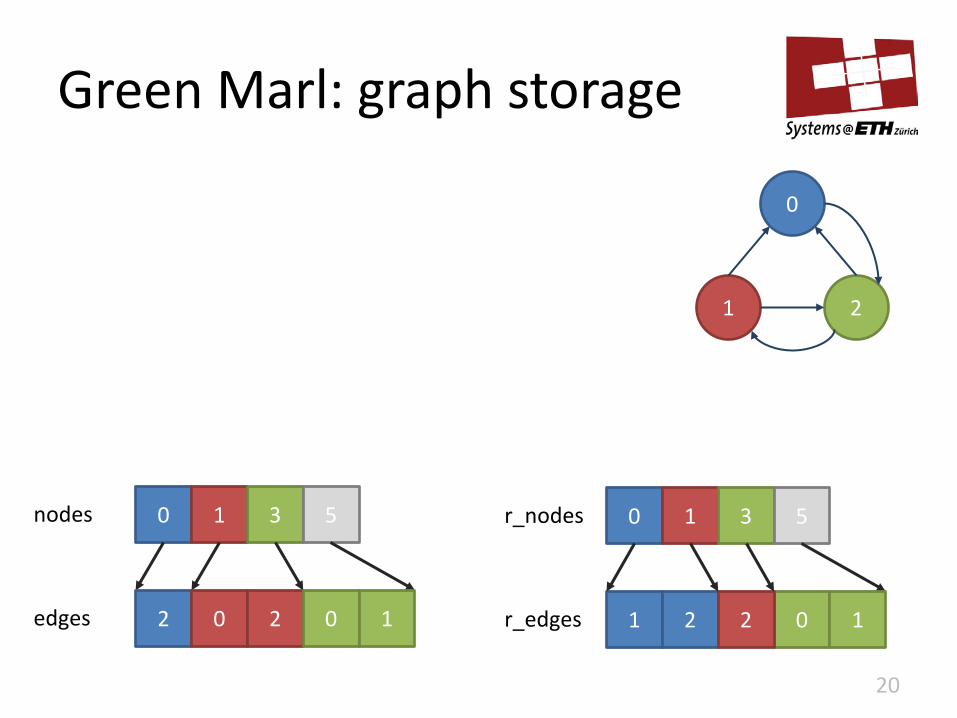
Green Marl: graph storage
20
nodes 0 1 3 5
2 0 2 edges 0 1 0 1 2 2 r_edges
0 1 3 r_nodes 5
1
0
1 2
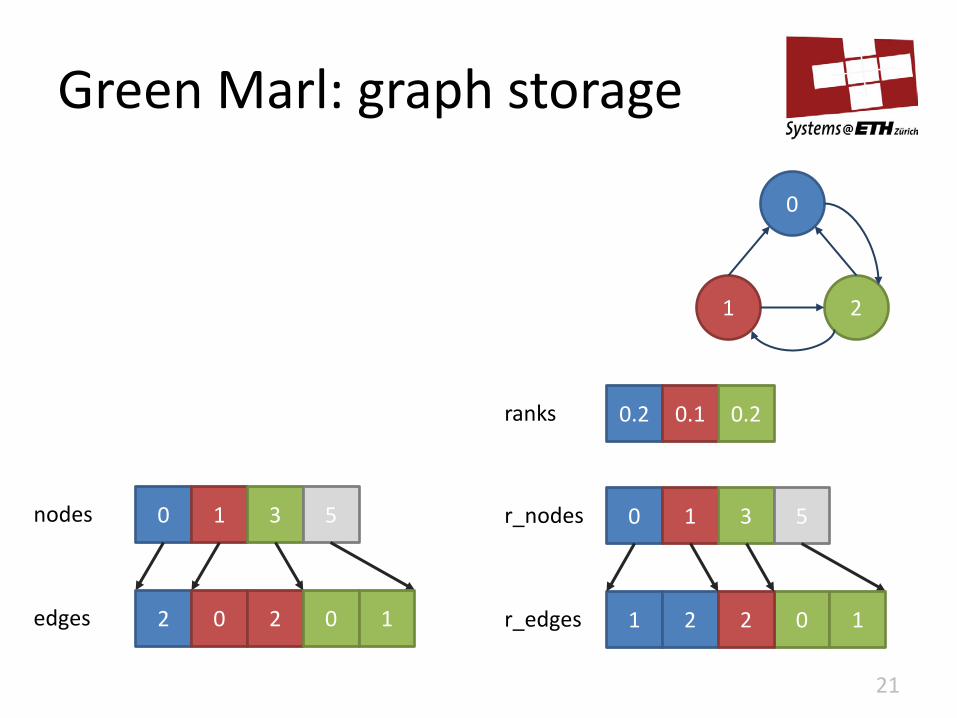
Green Marl: graph storage
21
0
1 2
0 1 2 2 r_edges
0 1 3 r_nodes 5
1
0.2 0.1 0.2 ranks
nodes 0 1 3 5
2 0 2 edges 0 1

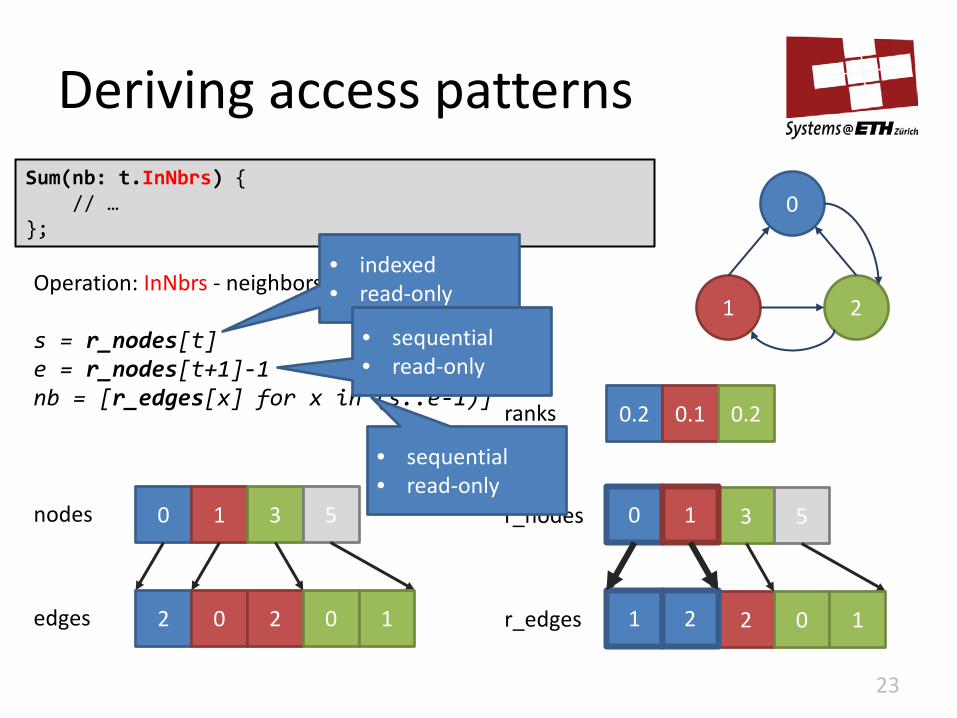
Deriving access patterns
22
Sum(nb: t.InNbrs) { // … };
1 2 2 0 r_edges
0 1 3 r_nodes 5
1
Operation: InNbrs - neighbors of node t: s = r_nodes[t] e = r_nodes[t+1]-1 nb = [r_edges[x] for x in (s..e-1)]
1 2
0 1 nodes 0 1 3 5
0.2 0.1 0.2 ranks
0
1 2
2 0 2 edges 0 1
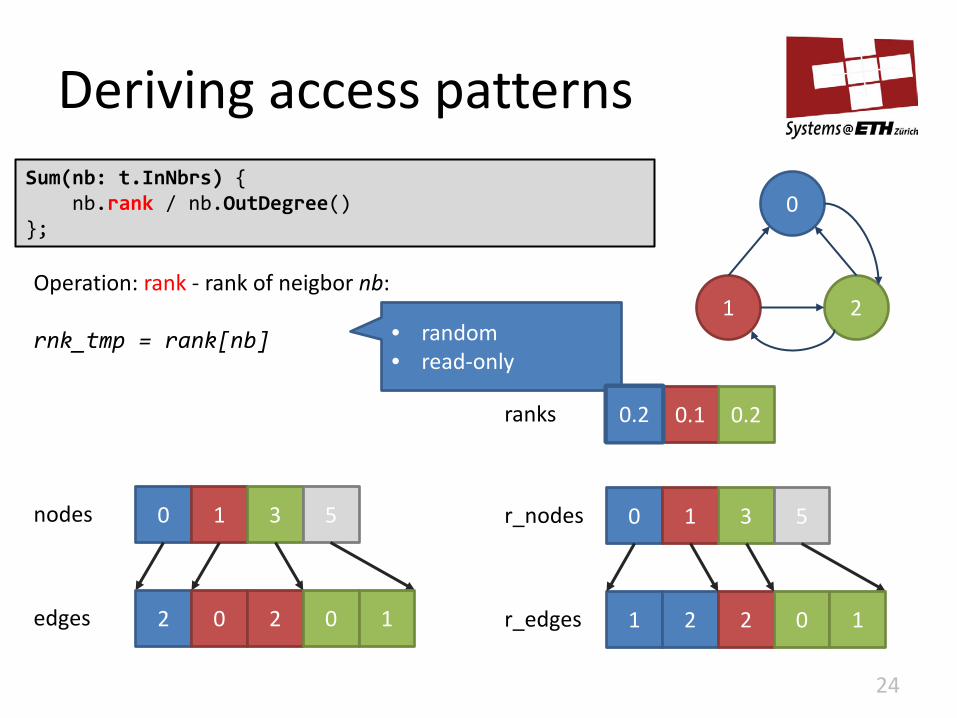
Deriving access patterns
23
Sum(nb: t.InNbrs) { // … };
1 2 2 0 r_edges
0 1 3 r_nodes 5
1
Operation: InNbrs - neighbors of node t: s = r_nodes[t] e = r_nodes[t+1]-1 nb = [r_edges[x] for x in (s..e-1)]
• indexed • read-only
• sequential • read-only
1 2
0 1 nodes 0 1 3 5
0.2 0.1 0.2 ranks
0
1 2 • sequential • read-only
2 0 2 edges 0 1
Deriving access patterns
24
Sum(nb: t.InNbrs) { nb.rank / nb.OutDegree() };
1 2 2 0 r_edges
0 1 3 r_nodes 5
1
Operation: rank - rank of neigbor nb: rnk_tmp = rank[nb] • random
• read-only
nodes 0 1 3 5
0.2 0.1 0.2 ranks 0.2
0
1 2
0.2
2 0 2 edges 0 1

Deriving access patterns
25
Sum(nb: t.InNbrs) { nb.rank / nb.OutDegree() };
1 2 2 0 r_edges
0 1 3 r_nodes 5
1
Operation: OutDegree() - of neighbor w: nodes[nb+1] – nodes[nb] • random
• read-only
nodes 0 1 3 5 0 1
0
1 2
0.2 0.1 0.2 ranks
2 0 2 edges 0 1
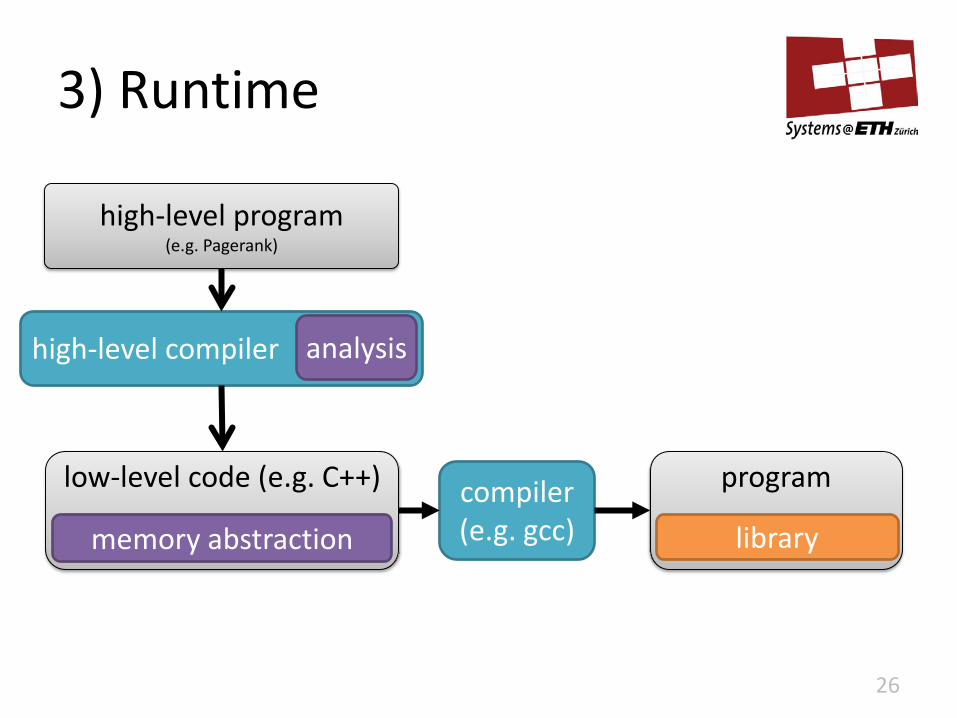
3) Runtime
26
low-level code (e.g. C++) compiler (e.g. gcc)
program
library
high-level program (e.g. Pagerank)
high-level compiler analysis
memory abstraction

Runtime: Choice of arrays
start
27
indexed?
partitioned
y
n
n
fits all nodes?
replicated
y
read-only?
distributed
y
n
H/W characteristics
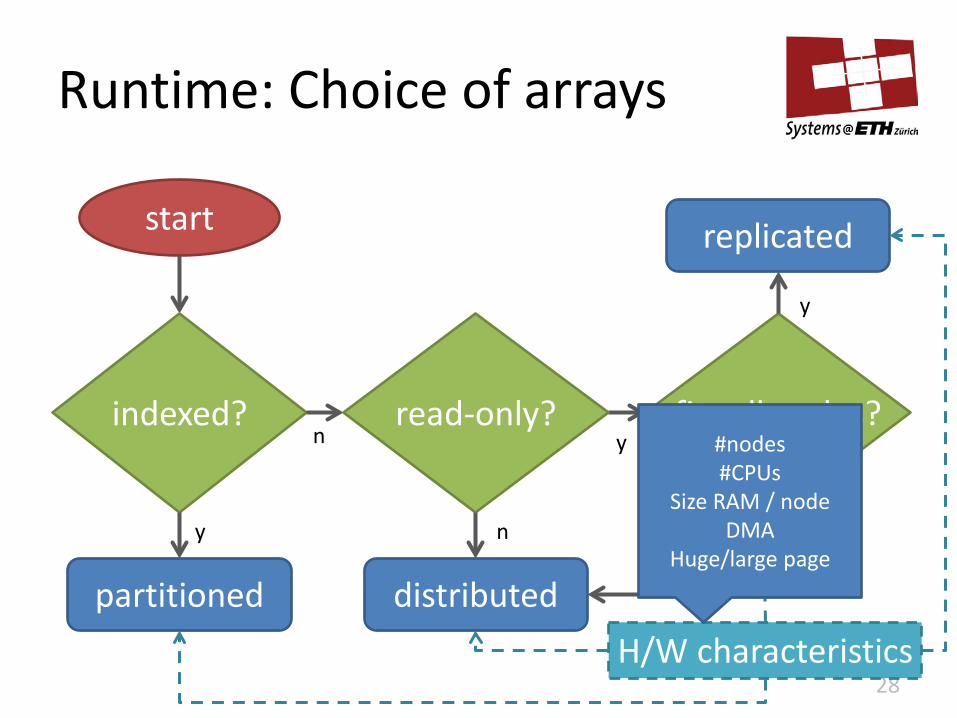
Runtime: Choice of arrays
start
28
indexed?
partitioned
y
n
n
fits all nodes?
replicated
y
read-only?
distributed
y
n
H/W characteristics
#nodes #CPUs
Size RAM / node DMA
Huge/large page

Shoal workflow
hardware characteristics
access patterns
29
low-level code (e.g. C++) compiler (e.g. gcc)
program
library
high-level program (e.g. Pagerank)
high-level compiler analysis
memory abstraction

Alternative approaches
• Search-based auto-tuning
• HW page migration
• Carrefour: Online analysis of access patterns – Simon Fraser University, ASPLOS 2013
– Performance counters to monitor accesses
– Dynamically migrate and replicate pages
30

EVALUATION
31
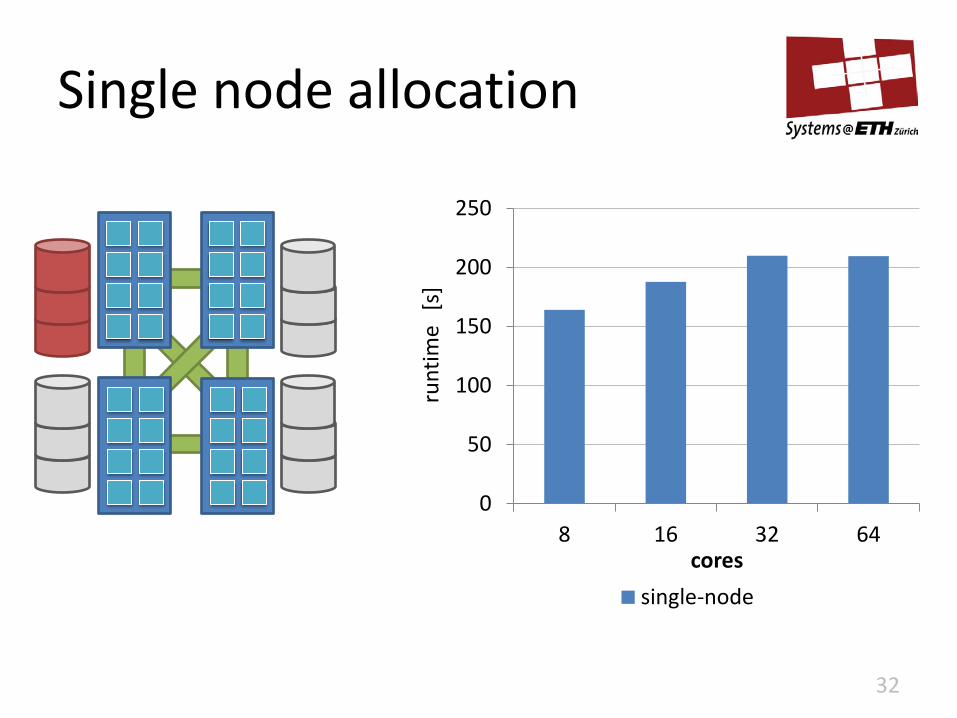
Single node allocation
32
0
50
100
150
200
250
8 16 32 64
runt
ime
[s]
cores
single-node
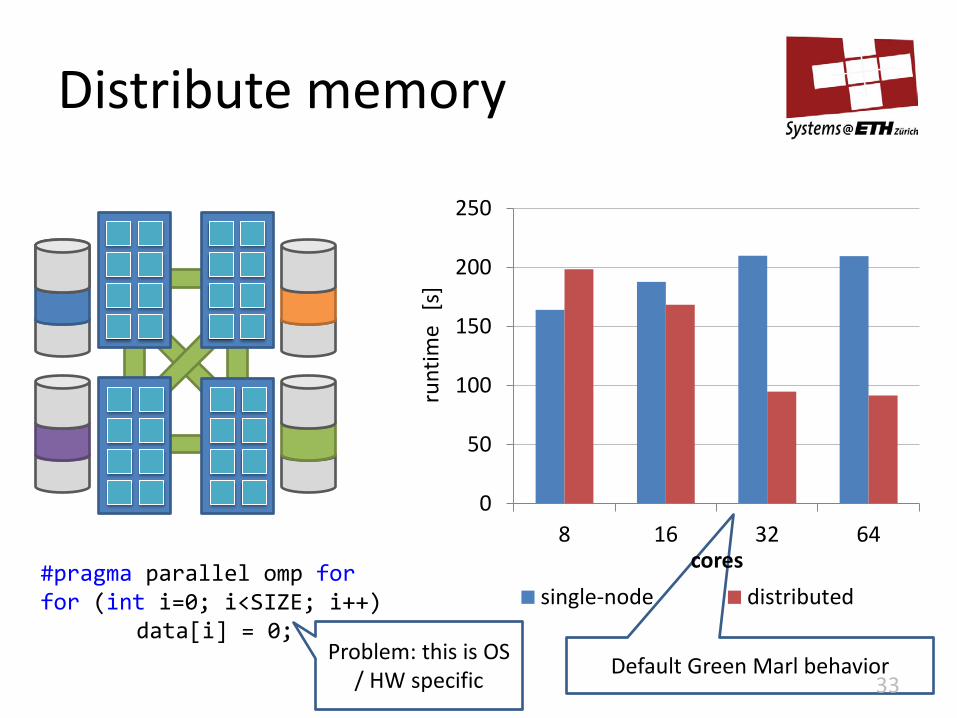
Distribute memory
#pragma parallel omp for for (int i=0; i<SIZE; i++) data[i] = 0;
Default Green Marl behavior 33
0
50
100
150
200
250
8 16 32 64
runt
ime
[s]
cores
single-node distributed
Problem: this is OS / HW specific
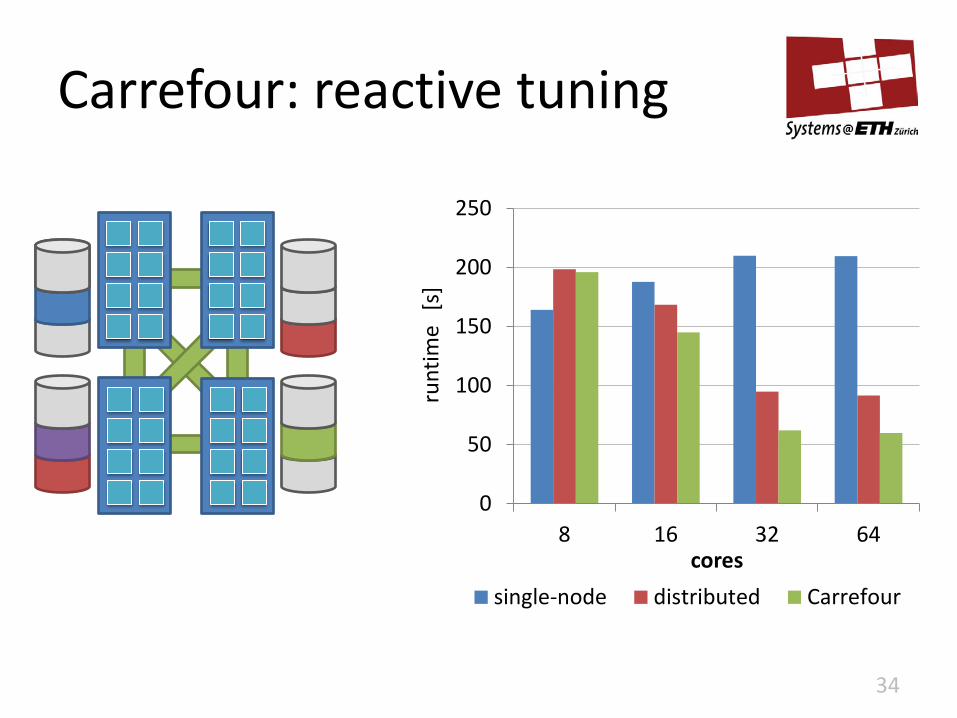
Carrefour: reactive tuning
34
0
50
100
150
200
250
8 16 32 64
runt
ime
[s]
cores
single-node distributed Carrefour
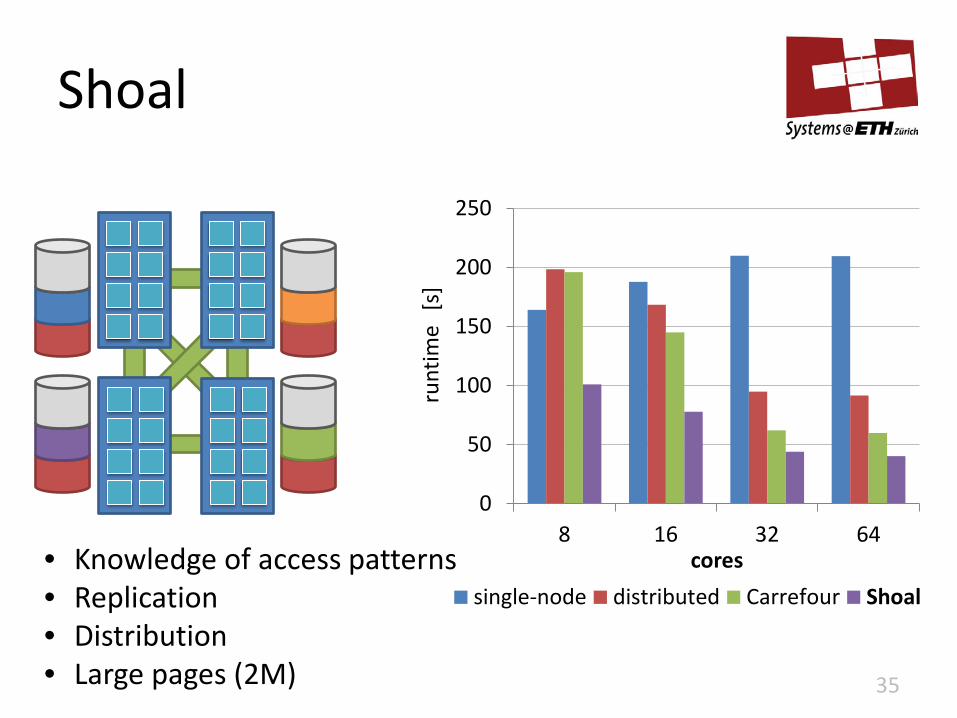
Shoal
• Knowledge of access patterns • Replication • Distribution • Large pages (2M)
0
50
100
150
200
250
8 16 32 64
runt
ime
[s]
cores
single-node distributed Carrefour Shoal
35
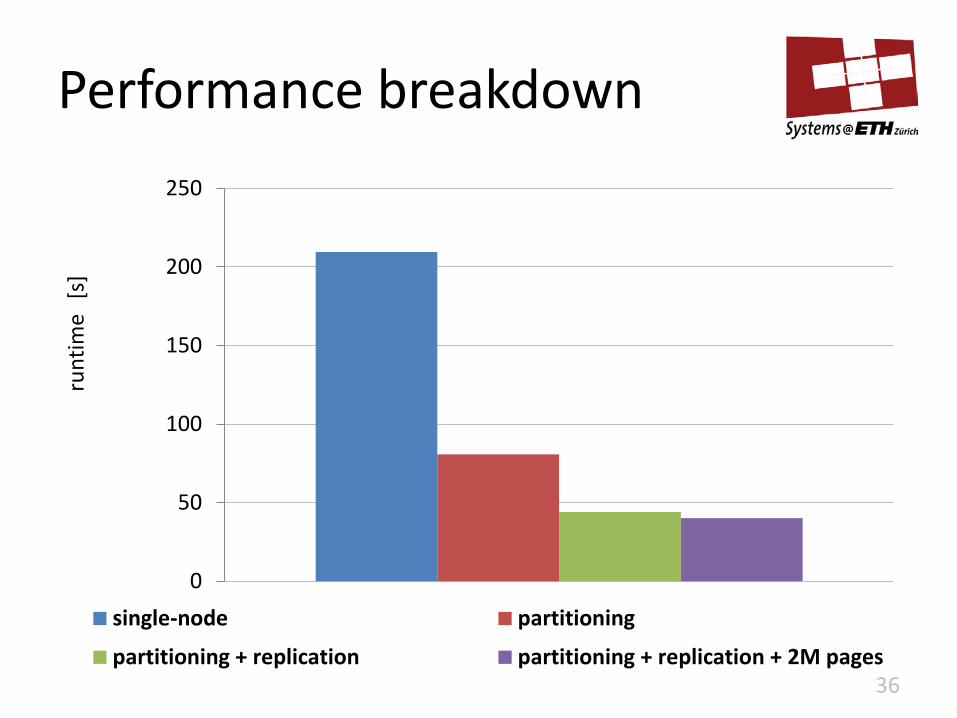
Performance breakdown
36
0
50
100
150
200
250
runt
ime
[s]
single-node partitioning
partitioning + replication partitioning + replication + 2M pages

Conclusion
• Memory abstraction, arrays • Compiler analysis derive access patterns • Runtime library selects implementation • Works well with domain specific languages • Also: support for manual annotation
– Too complex, too dynamic Online
• Public release next week
37