voginip lezing 2015: classificeren zonder voorbeelden
TRANSCRIPT

Visual Classification without examplesClassificeren van beeld zonder voorbeelden
Thomas MensinkVOGIN-IP-LEZING 2015

• What is an axolotl?
• Some examples
Preview
VOGIN-IP 20152

VOGIN-IP 20153
We can classify based on labeled examples(supervised learning)

Preview
• What is an aye-aye?
• Textual description:
– Is nocturnal
– Lives in trees
– Has large eyes
– Has long middle fingers
VOGIN-IP 20154

VOGIN-IP 20155
We can classify based on a textual description(and some prior knowledge)

VOGIN-IP 20156
Can a computer do the same?(yes, that is what this talk is about)

Agenda
• Supervised Visual Classification
• Attribute-Based Classification
• Co-occurrence Based Classification
VOGIN-IP 20157
Computer Vision – in the news
VOGIN-IP 20158

Visual Recognition
9
Cityscap
eOutdoor
…
tree
Buildin
gLamp
People
John
Dam
Slide credit: Jan van Gemert
VOGIN-IP 2015

Supervised Classification
• Obtain annotated examples
• Find a representation
• Train a generic classifier
VOGIN-IP 201510
Remarks:- New class: retrain on new examples- How to obtain training examples?- How to represent images?
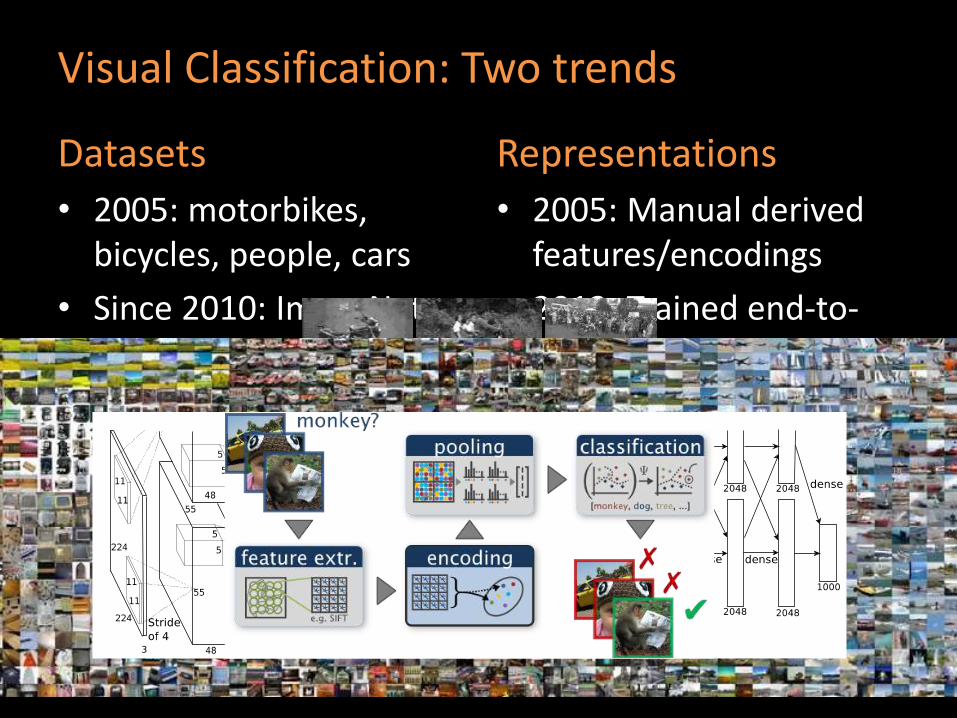
Visual Classification: Two trends
Datasets
• 2005: motorbikes, bicycles, people, cars
• Since 2010: ImageNet15K
Representations
• 2005: Manual derived features/encodings
• 2012: Trained end-to-end, Deep Neural Nets
VOGIN-IP 201511

VOGIN-IP 201512
1000 classes, 5 guesses per imageCurrent state-of-the-art: 6.7% error

Estimating human performance
VOGIN-IP 201513
Andrej Karpathy: “I realized that I needed to go through the painfully long training process myself” Test set 1500 images
GoogleNet: 6.8% errorKarpathy: 5.1% error

VOGIN-IP 201514
Visual Classification:near-human performance
when ample train data is available
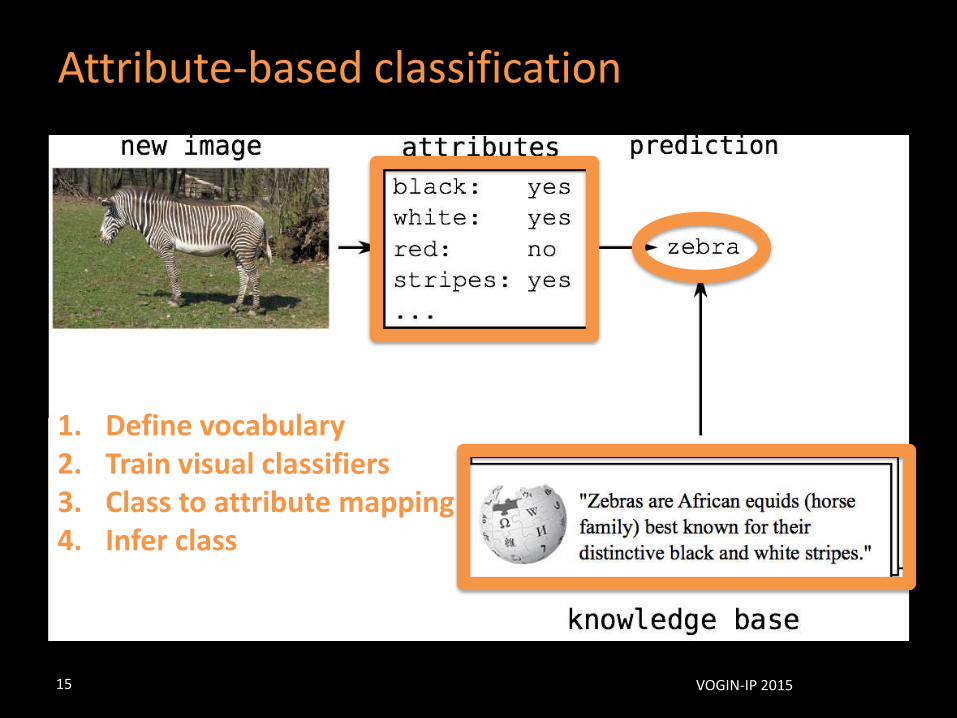
Attribute-based classification
VOGIN-IP 201515
1. Define vocabulary2. Train visual classifiers3. Class to attribute mapping4. Infer class

What are good attributes?
• Good attributes
– are task and category dependent;
– class discriminative, but not class specific;
– interpretable by humans; and
– detectable by computers
VOGIN-IP 201516

Quiz: What are good attributes?
• is grey?
• is made of atoms?
• lives in Amsterdam?
• is sunny?
• eat fish?
• has a SIFT descriptor with empty bin 3?
• has 4 wheels?
VOGIN-IP 201517

How many attributes?
• In theory k binary attributes can represent
– 2k classes
• In practice for c classes we need
– Many attributes
VOGIN-IP 201518

Animals with Attributes
VOGIN-IP 201519

Animals with Attributes - Vocabular
VOGIN-IP 201520
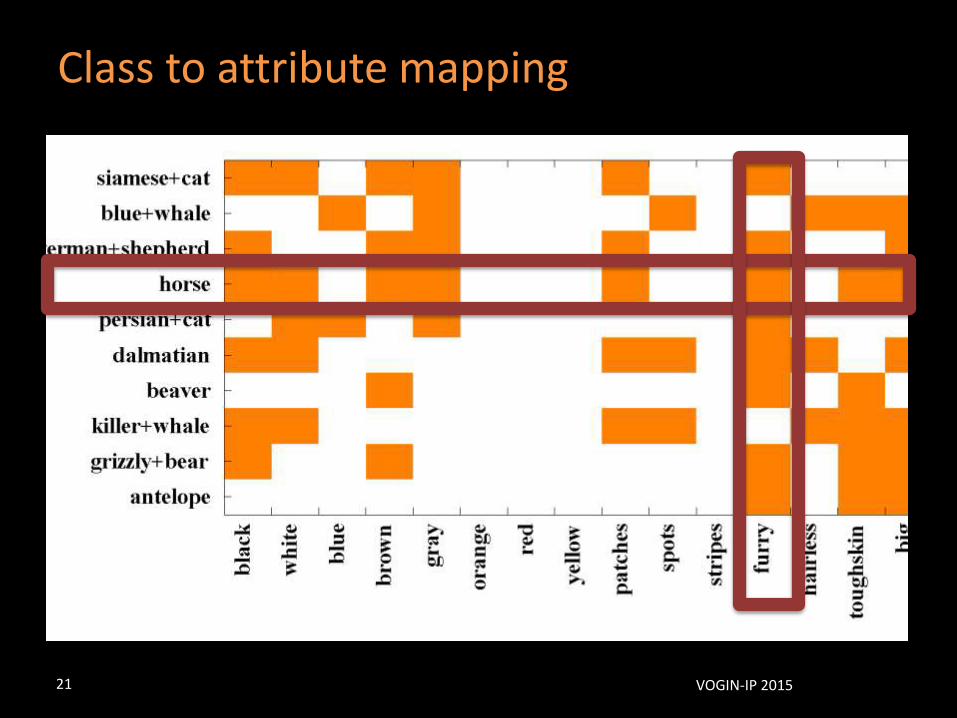
Class to attribute mapping
VOGIN-IP 201521

Attribute Based Prediction
1. Learn attribute classifiers from related classes
2. Train and Test set are disjoint
3. Infer attributes from new test image
4. Use attribute-to-class mapping to predict class
VOGIN-IP 201522

Animals with Attributes (results)
VOGIN-IP 201523

Disadvantages
• Unnatural distinction between
– Attributes to be detected
– Classes of interest
• Inherently multi-class zero-shot prediction
VOGIN-IP 201524

Classification based on co-occurrences
I’m looking for a label, which I have not seenbefore. However, this picture contains also:
1. Indoor
2. Living room
3. Table
4. Chair
VOGIN-IP 201525

VOGIN-IP 201526
We can classify based on context
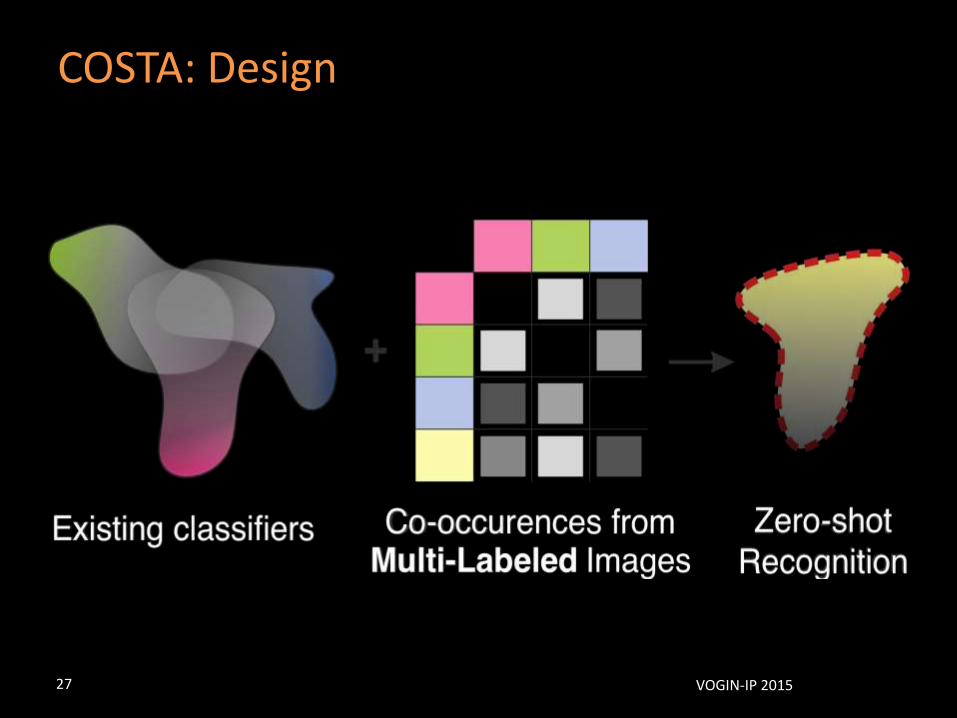
COSTA: Design
VOGIN-IP 201527

COSTA: Design
VOGIN-IP 201528
• Many visual concepts can be described as an open set of concept-to-concept relations
• Describe image semantics with co-occurrences
• Exploit natural bias in natural images

Exploit natural bias in natural images
VOGIN-IP 201529
• k
•
• ŵl
slk ak"
•
:"concept)to)concept"inter)dependencies"reveal"a"
significant"part"of"the"latent"image"seman6cs"
Co)occurrences"from"Flickr"capture"well"the"concept)
to)concept"rela6ons
Regressing"classifiers"with"posi6ve"&"nega6ve"co)occurrences"lead"to"
surprisingly"good"results
Sink"is"usually"in"the"same"visual"space"as"a"cupboard,"a"stove,"and"a"dishwasher.
H-SUN
Sett ing SUB L1O ZS75 ZS50
Nr. Train labels 107 106 81 54
Baselines
Supervised SVM 21.5 – – –
Attributes – 12.8 13.0 12.3
COSTA
Co-oc Dice – 14.5 14.5 12.9
P&N Dice – 13.7 13.8 10.8
Reg P&N Dice – 17.0 16.4 15.0
COSTA: Internet co-occurrences
Web hit counts – 9.9 9.8 9.8
Imagehit counts – 12.7 9.1 9.3
Flickr hit counts – 15.1 13.4 10.1
1Zero 2 4 8 16 32 64 128 All
25
30
35
40
45
Number of images
mA
P
iCLEF10
Data
Data+ Prior
Data+ WebPrior
Zero 2 4 8 16 32 64 128 All
10
15
20
Few Many
Number of images
mA
P
H-SUN
Zero 2 4 8 16 32 64 128 All
11
12
13
14
15
16
Number of images
mA
P
CUB-Att
Figure3. Few-shot classificationusingregressionbasedzero-shot prior fromground-truthor webhit-counts(except CUB-Att). Including
theprior significantly benefitsperformance, especially inthepresenceof very fewpositiveimages. Notethelog-scaleonthex-axis.
References
[1] Z.Akata, F.Perronnin, Z.Harchaoui, andC.Schmid. Label-
embeddingforattribute-basedclassification. InCVPR,2013.
2, 5
[2] E.Bart andS.Ullman. Cross-generalization: Learningnovel
classes from a single example by feature replacement. In
CVPR, 2005. 2
[3] G. Chen, Y. Ding, J. Xiao, andT. Han. Detectionevolution
withmulti-order contextual co-occurrence. InCVPR, 2013.
3
[4] M. Choi, J. Lim, A. Torralba, and A. Willsky. Exploiting
hierarchical context onalargedatabaseof object categories.
InCVPR, 2010. 3, 5
[5] M. Everingham, L. Van Gool, C. Williams, J. Winn, and
A. Zisserman. ThePascal visual object classes(VOC) chal-
lenge. IJCV, 2010. 2, 5
[6] R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C.-
J. Lin. Liblinear: A library for large linear classification.
JMLR, 2008. 4
[7] H. Grabner, J. Gall, and L. V. Gool. What makesachair a
chair? InCVPR, 2011. 1
[8] B. Hariharan, S. Vishwanathan, and M. Varma. Efficient
max-margin multi-label classification with applications to
zero-shot learning. MLJ, 2012. 3
[9] H. Jegou and O. Chum. Negative evidences and co-
occurrences in image retrieval: the benefit of PCA and
whitening. InECCV, 2012. 3
[10] H. Jegou, M. Douze, and C. Schmid. On theburstinessof
visual elements. InCVPR, 2009. 3
[11] L. Ladicky, C. R. P. Kohli, and P. Torr. Graph cut based
inferencewithco-occurrencestatistics. InECCV, 2010. 3
[12] C. Lampert, H. Nickisch, and S. Harmeling. Attribute-
based classification for zero-shot learning of object cate-
gories. IEEETrans. PAMI, 2013. 1, 2, 3, 6, 7
[13] F.-F. Li, R. Fergus, andP. Perona. One-shot learningof ob-
ject categories. IEEETrans. PAMI, 2006. 2
[14] T. MalisiewiczandA. Efros. Beyondcategories: thevisual
memex model for reasoning about object relationships. In
NIPS, 2009. 1, 3
[15] T.Mensink, J.Verbeek, andG.Csurka. Tree-structuredCRF
models for interactive image labeling. IEEE Trans. PAMI,
2012. 3, 5
[16] T. Mensink, J. Verbeek, F. Perronnin, and G. Csurka.
Distance-based image classification: Generalizing to new
classesat near-zerocost. IEEETrans. PAMI, 2013. 1, 2
[17] S.NowakandM.Huiskes. Newstrategiesfor imageannota-
tion: Overview of thephotoannotation task at ImageCLEF
2010. InWorkingNotesof CLEF, 2010. 5
[18] F. Orabona, C. Castellini, B. Caputo, A. E. Fiorilla, and
G. Sandini. Model adaptation with least-squares svm for
adaptivehandprosthetics. InIEEEICRA, 2009. 4
[19] M. Rastegari, A. Farhadi, andD. Forsyth. Attributediscov-
ery viapredictablediscriminativebinary codes. In ECCV,
2012. 2
[20] M. Rohrbach, M. Stark, andB. Schiele. Evaluatingknowl-
edgetransfer andzero-shot learning inalarge-scalesetting.
InCVPR, 2011. 1, 2
[21] M. Rohrbach, M. Stark, G. Szarvas, I. Gurevych, and
B. Schiele. What helpswhere–and why? semantic relat-
ednessfor knowledgetransfer. InCVPR, 2010. 2, 4, 6
[22] M. Sadeghi and A. Farhadi. Recognition using visual
phrases. InCVPR, 2011. 3
[23] R. Salakhutdinov, A. Torralba, andJ. Tenenbaum. Learning
tosharevisual appearancefor multiclassobject detection. In
CVPR, 2011. 2
[24] J. Sanchez, F. Perronnin, T. Mensink, and J. Verbeek. Im-
ageclassificationwiththefishervector: Theoryandpractice.
IJCV, 2013. 3, 4
[25] V.Sharmanska, N.Quadrianto, andC.Lampert. Augmented
attributerepresentations. InECCV, 2012. 2
[26] T. Tommasi and B. Caputo. Themoreyou know, the less
you learn: fromknowledgetransfer toone-shot learning of
object categories. InBMVC, 2009. 2
[27] T. Tommasi, F. Orabona, andB. Caputo. Safety innumbers:
Learning categories from few examples with multi model
knowledgetransfer. InCVPR, 2010. 4
[28] C.Wah, S.Branson, P.Welinder,P.Perona, andS.Belongie.
Thecaltech-ucsd birds-200-2011 dataset. Technical report,
Computation& Neural Systems, 2011. 1, 2, 3, 5
[29] J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba.
SUNdatabase: Large-scalescenerecognitionfromabbey to
zoo. InCVPR, 2010. 2, 5
8
Exis6ng"classifiers" Co)occurrences" Zero)shot"predic6on"
Co-occurrencestatistics. Co-occurrenceshavebeen re-
peatedlyconsideredforcapturinghigherorder relationships
betweenclasses, conceptsandlabels. They havebeenused
to improve image segmentation [11], object detection [3,
22], to reasonabout what toexpect inascene[4, 14], and
for image and attribute classification [8, 15]. In general,
wenoticethat co-occurrencesof objects, labelsandtextures
havebeenrecognizedasastrongcluefor label andattribute
prediction. However, wearenot awareof any works that
uselabel co-occurrencestoenablezero-shot classification.
3. Zero-shot multi-label classification
In thissectionwedefineour zero-shot framework using
label co-occurrences. Wefirst introduceour co-occurrence
basedclassificationmethod. Second, inSection3.2wede-
scribearegressioninterpretationtoobtainzero-shot classi-
fier. Third, inSection3.3weillustratetheuseof thezero-
shot model asprior for few-shot classification.
3.1. Co-occurrencebasedclassification
Our goal is to estimate aclassification function for an
unseenlabel l,usingaset of existingclassifiers.Weassume
thatwehaveasetof linearclassifiers, trainedonacollection
of annotated imageswithk labels. Theseclassifierscould
beobtained frombinary SVMsor logistic regression, and
arerepresented by their weight vectorswk 2 Rd⇥1. We
assume, without lossof generality, that theweight vectors
areaugmentedsuchthat thebiasesareincluded.
Weproposetoestimatetheweight vector wl toclassify
theunseenlabel l, as
wl =X
k
wk slk, (1)
where slk represents a measure of similarity between the
known label k and the unseen label l. In this paper, we
base these similarities on the co-occurrence statistics be-
tweenthenewlabel andexistinglabels.
Co-occurrence similarities. We explore different simi-
larity measuresbased on theco-occurrenceof two labels.
Let ci j denotethetotal number of imagesfor whichlabel i
and label j arerelevant according toanauxiliary resource,
for exampletheground-truthlabelling,awebsearchengine
or auser providedinput inthecaseof activelearning. Also,
ci denotesthetotal number of imagesdepictinglabel i, and
m denotesthetotal number of labels. Thesimilaritieswe
exploreare:
• Normalizedco-occurrences,
sni j =
ci j
ci
, (2)
where the similarity is directly proportional to the
number of co-occurrences.
• Binarized co-occurrences, motivated by thebinarized
class-to-attributes mappings used in attribute-based
zeroshot classification[12, 28]:
sbi j = [[ci j ≥ t]], (3)
wheret isaglobal thresholdset ast = 1m2
Pi ,j ci j .
• Burstinesscorrectedco-occurrences. Burstinessisthe
phenomenathat thefrequencyof anobservationissig-
nificantly larger thanastatistically independent model
wouldpredict. Thesquare-root functionisusedinim-
ageretrieval andclassificationtocorrect for burstiness
of visual features[10,24]. Similarly,weaimtoreduce
theburstinessinlabellings, anduse:
ssi j =
pci j , (4)
• TheDice’scoefficient,
sdi j =
ci j
ci + cj
, (5)
isameasureusedinmany Natural LanguageProcess-
ingsystems. It aimstoestimatethesemantic related-
nessbetweentwoterms, basedonhit countsfromweb
searchengines.
Definingaconcept bywhat it isnot. Thesimilaritiesde-
finedabove,arebasedonlyonpositiveco-occurrences, i.e.,
how often two labelsarerelevant for an image. However,
knowingwhat isnot relatedtotheconcept might beavery
informativeclueabout thevisual scopeof aconcept, which
isalsoshowninanimageretrieval setting[9].
In addition to the positive co-occurrences, denoted by
c++i j , wealsousetheother possibleco-occurrencerelations:
thepresenceof label i with theabsenceof label j , theab-
senceof label i withthepresenceof label j ,andtheabsence
of bothlabels, denotedbyc+–i j ,c–+i j , andc––i j respectively. For
eachof thesedefinitionsof co-occurrenceweusethesimi-
laritymeasuresdefinedabove.
Using the positive and negative co-occurrences, the
weight vector wl of anunknownlabel canbeestimatedas:
wl =X
k
wk s++lk − wk s+–
lk − wk s–+lk + wk s––lk , (6)
Estimateco-occurrencefromwebdata. Sofar,wehave
not discussedhowtoobtaintheco-occurrencestatisticsre-
quired for our zero-shot recognition framework. To show
the potential of our framework, in most of the experi-
mentsweestimate label co-occurrences fromtheground-
truth labellingof our imagedatasets. Alternatively, theco-
occurrencestatisticscouldbeestimatedfromlargetext cor-
pora,e.g.,WordnetorWikipedia,or internetsearchengines,
suchasYahoo, GoogleandBing.
3
Following [21], we use the hit counts estimations of
theYahoowebsearch, Yahoo imagesearchandFlickr-tag
searchenginestoestimatetoco-occurrences. Weestimate
the similaritiesdefined above, using cHCi j denoting the hit
count for aquery consistingof label i and j . Thepositive
andnegativeco-occurrencesareestimatedby using thehit
countscHCi of theindividual labelsi, andanestimateof the
total number of imagescHCtotal =
Pi ci .
3.2. Regression toestimateclassifiers
Toimprovetheclassifier for theunseenlabel l, wepro-
posetolearnaweightedversionof Eq. (1), givenby:
wl =X
k
ak wk slk, (7)
whereak isaweight for classifier k, which isindependent
fromtheunseenlabel l.
Ideally,weset theclassifierweightsa 2 Rk⇥1 suchthat,
theestimatedweight vector wl equalstheideal weight vec-
tor wl , whichwouldhavebeenbeobtainedby learningon
thevisual datawith annotations available. This could be
seen asaregression problem, wherea isset to regress w
towardsw. However, sinceweaimfor zero-shot classifica-
tion, wedonot haveaccessto theunseen labels l, nor the
ideal weight vectorswl at traintime. Thereforeweusethe
knownlabelsk inaleave-one-out settingfor learning.
Weminimizethefollowingregressionsquared-loss:
Lreg =X
i
kwi −X
k
akwk si kk22, (8)
=X
i
X
d
wi d − a> vi d2, (9)
where index i and k both run over theknown labels, and
si i = 0. The vector vi d contains the k co-occurrence
weightedweight vectorsvi dk = si k wkd.
Notethat thelossisformulatedover trainclassesandnot
over train images. Moreover, Eq. (9) showsthat a can be
obtainedinclosed-formusingridge-regression. Inpractice
weobservethat regularization isnot needed for goodper-
formance, thedimensionality of a ismuchsmaller thanthe
number of traininginstances(k vs. dk).
3.3. Zero-shot prior for few-shot prediction
In a few-shot classification setting afew, e.g., up to 8,
positiveimagesareprovidedper label to learnaclassifier.
In such a setting a strong prior could benefit the perfor-
manceby guiding theSVM classifier. In this section we
consider asimplemodel adaptationmethodwherethezero-
shot model actsasaprior for thefew-shot classifier.
In thecasethat weemploy linear SVM classifierswith
squaredhinge-loss, theobjectivetominimizebecomes:
Lfew =C
2
X
i
⇥1− yi l w>
l x i
⇤2+
+1
2kwl − βwzk
22, (10)
wherewz is theprior obtained fromthezero-shot model,
andβ 2 (0,1) isascalingparameter tocontrol thedegree
to which thelabel classifier should besimilar to thezero-
shot model. It can beshown that theoptimal solution for
wl , for aspecificvalueof C, isgivenby [18, 27]:
wl = wg + βwz, (11)
wherewg istheweight vectorobtainedfromoptimizingthe
standardSVMformulation, i.e., usingEq. (10) withβ = 0.
Wewill usewg alsoasabaselinefew-shot classifier. Note
that theoptimal parameter C could differ when including
theprior. Inourexperiments,wefirstdeterminetheoptimal
valueof C forwg usingcross-validation, thenweobtainwl
byusingβ = 1.
4. Experiments
Inthissectionweexperimentallyvalidateourmodelsfor
zero-shot andfew-shot imagelabellingusingco-occurrence
statistics. Sinceweareinterested inazero-shot classifica-
tionsetting, for most experimentswesplit thelabelsof the
datasetsintotwodisjoint sets: theknownclassesandtheun-
seenclasses. Thetruezero-shot classifiersuselabelsfrom
theknownclassesonly. Sincewearenotawareof anymeth-
ods that do zero-shot recognition on multi-label datasets
nor usingmulti-label co-occurrencestatistics, wecompare
with thebinarized versionof co-occurences, theclosest to
what attributescouldbefor multi-labeleddatasets. Further-
more, for all datasetswereport resultsobtained in afully
supervisedsetting, wheretheSVMclassifiersusethetrain-
inglabelsfromall classes, beit knownor unseen.
4.1. Experimental set-upanddatasets
Imagefeatures. Forall ourexperimentsweusetheFisher
Vector (FV) image representation [24]. Per image a sin-
gleFV x isextracted, and wefollow acommon pipeline
and use: (i) SIFT descriptors, projected with PCA to 96-
dimensions; (ii) Mixture-of-Gaussian codebook with 16
components; (iii) power-normalization and `2 normaliza-
tion. Thefinal FV isonly3K dimensional, despitethecom-
pactnessitsperformanceisstill competitive.
Implementation. For all experimentswhereSVMclassi-
fiersareused, wetrain linear SVMs[6] and employ two-
fold cross-validation on the train data to set the value of
C. Performance is measured by mean AveragePrecision
(mAP). For the few-shot and zero-shot experiments, the
mAP is averaged only over test labels. For the few-shot
experiments, wefixβ = 1, seeEq. (11).
Wealso report thesupervised upper bound (SUB) per-
formance, obtained by training SVMson thefull ground-
truth annotations. The SUB serves as the ideal classifier
whichcouldbeobtainedfromthisdata.
4
Following [21], we use the hit counts estimations of
theYahoo websearch, Yahoo imagesearch andFlickr-tag
searchenginestoestimatetoco-occurrences. Weestimate
the similaritiesdefined above, using cHCi j denoting the hit
count for aquery consisting of label i and j . Thepositive
andnegativeco-occurrencesareestimatedby using thehit
countscHCi of theindividual labelsi, andanestimateof the
total number of imagescHCtotal =
Pi ci .
3.2. Regression toestimateclassifiers
Toimprovetheclassifier for theunseen label l, wepro-
posetolearnaweightedversionof Eq. (1), givenby:
wl =X
k
ak wk slk, (7)
whereak isaweight for classifier k, which isindependent
fromtheunseenlabel l.
Ideally,weset theclassifierweightsa 2 Rk⇥1 suchthat,
theestimatedweight vector wl equalstheideal weight vec-
tor wl , whichwouldhavebeenbeobtainedby learningon
the visual data with annotations available. This could be
seen asaregression problem, wherea isset to regress w
towardsw. However, sinceweaimfor zero-shot classifica-
tion, wedo not haveaccessto theunseen labels l, nor the
ideal weight vectorswl at traintime. Thereforeweusethe
knownlabelsk inaleave-one-out settingfor learning.
Weminimizethefollowingregressionsquared-loss:
Lreg =X
i
kwi −X
k
akwk si kk22, (8)
=X
i
X
d
wi d − a> vi d2, (9)
where index i and k both run over theknown labels, and
si i = 0. The vector vi d contains the k co-occurrence
weightedweight vectorsvi dk = si k wkd.
Notethat thelossisformulatedover trainclassesandnot
over train images. Moreover, Eq. (9) showsthat a can be
obtainedinclosed-formusingridge-regression. Inpractice
weobservethat regularization isnot needed for good per-
formance, thedimensionality of a ismuchsmaller thanthe
number of traininginstances(k vs. dk).
3.3. Zero-shot prior for few-shot prediction
In a few-shot classification setting a few, e.g., up to 8,
positiveimagesareprovided per label to learnaclassifier.
In such a setting a strong prior could benefit the perfor-
mance by guiding theSVM classifier. In this section we
consider asimplemodel adaptationmethodwherethezero-
shot model actsasaprior for thefew-shot classifier.
In thecasethat weemploy linear SVM classifierswith
squaredhinge-loss, theobjectivetominimizebecomes:
Lfew =C
2
X
i
⇥1− yi l w>
l x i
⇤2+
+1
2kwl − βwzk
22, (10)
wherewz is theprior obtained fromthezero-shot model,
andβ 2 (0,1) isascalingparameter tocontrol thedegree
to which thelabel classifier should besimilar to thezero-
shot model. It can beshown that theoptimal solution for
wl , for aspecificvalueof C, isgivenby [18, 27]:
wl = wg + βwz, (11)
wherewg istheweight vectorobtainedfromoptimizingthe
standardSVM formulation, i.e., usingEq. (10) withβ = 0.
Wewill usewg alsoasabaselinefew-shot classifier. Note
that theoptimal parameter C could differ when including
theprior. Inour experiments,wefirstdeterminetheoptimal
valueof C forwg usingcross-validation, thenweobtainwl
byusingβ = 1.
4. Experiments
Inthissectionweexperimentallyvalidateourmodelsfor
zero-shot andfew-shot imagelabellingusingco-occurrence
statistics. Sinceweareinterested inazero-shot classifica-
tionsetting, for most experimentswesplit thelabelsof the
datasetsintotwodisjoint sets: theknownclassesandtheun-
seenclasses. Thetruezero-shot classifiersuselabelsfrom
theknownclassesonly. Sincewearenotawareof anymeth-
ods that do zero-shot recognition on multi-label datasets
nor usingmulti-label co-occurrencestatistics, wecompare
with thebinarized version of co-occurences, theclosest to
what attributescouldbefor multi-labeleddatasets. Further-
more, for all datasetswereport resultsobtained in afully
supervisedsetting, wheretheSVMclassifiersusethetrain-
inglabelsfromall classes, beit knownor unseen.
4.1. Experimental set-upanddatasets
Imagefeatures. Forall ourexperimentsweusetheFisher
Vector (FV) image representation [24]. Per image a sin-
gleFV x isextracted, and wefollow acommon pipeline
and use: (i) SIFT descriptors, projected with PCA to 96-
dimensions; (ii) Mixture-of-Gaussian codebook with 16
components; (iii) power-normalization and `2 normaliza-
tion. Thefinal FV isonly3K dimensional, despitethecom-
pactnessitsperformanceisstill competitive.
Implementation. For all experimentswhereSVMclassi-
fiersareused, wetrain linear SVMs[6] and employ two-
fold cross-validation on the train data to set the value of
C. Performance is measured by mean Average Precision
(mAP). For the few-shot and zero-shot experiments, the
mAP is averaged only over test labels. For the few-shot
experiments, wefixβ = 1, seeEq. (11).
Wealso report thesupervised upper bound (SUB) per-
formance, obtained by training SVMson thefull ground-
truth annotations. The SUB serves as the ideal classifier
whichcouldbeobtainedfromthisdata.
4
Co-occurrencestatistics. Co-occurrences havebeen re-
peatedlyconsideredforcapturinghigherorder relationships
betweenclasses, conceptsandlabels. They havebeenused
to improve image segmentation [11], object detection [3,
22], to reasonabout what toexpect inascene[4, 14], and
for image and attribute classification [8, 15]. In general,
wenoticethat co-occurrencesof objects, labelsandtextures
havebeenrecognizedasastrongcluefor label andattribute
prediction. However, wearenot awareof any works that
uselabel co-occurrencestoenablezero-shot classification.
3. Zero-shot multi-label classification
Inthissectionwedefineour zero-shot framework using
label co-occurrences. Wefirst introduceour co-occurrence
basedclassificationmethod. Second, inSection3.2wede-
scribearegressioninterpretationtoobtainzero-shot classi-
fier. Third, inSection3.3weillustratetheuseof thezero-
shot model asprior for few-shot classification.
3.1. Co-occurrencebasedclassification
Our goal is to estimate aclassification function for an
unseenlabel l,usingaset of existingclassifiers.Weassume
thatwehaveasetof linearclassifiers, trainedonacollection
of annotated imageswithk labels. Theseclassifierscould
beobtained frombinary SVMsor logistic regression, and
are represented by their weight vectorswk 2 Rd⇥1. We
assume, without lossof generality, that theweight vectors
areaugmentedsuchthat thebiasesareincluded.
Weproposetoestimatetheweight vector wl toclassify
theunseenlabel l, as
wl =X
k
wk slk, (1)
where slk represents a measure of similarity between the
known label k and the unseen label l. In this paper, we
base these similarities on the co-occurrence statistics be-
tweenthenewlabel andexistinglabels.
Co-occurrence similarities. We explore different simi-
larity measuresbased on theco-occurrenceof two labels.
Let ci j denotethetotal number of imagesfor whichlabel i
and label j arerelevant according toanauxiliary resource,
for exampletheground-truthlabelling,awebsearchengine
or auser providedinput inthecaseof activelearning. Also,
ci denotesthetotal number of imagesdepictinglabel i, and
m denotesthetotal number of labels. Thesimilaritieswe
exploreare:
• Normalizedco-occurrences,
sni j =
ci j
ci
, (2)
where the similarity is directly proportional to the
number of co-occurrences.
• Binarized co-occurrences, motivated by thebinarized
class-to-attributes mappings used in attribute-based
zeroshot classification[12, 28]:
sbi j = [[ci j ≥ t]], (3)
wheret isaglobal thresholdset ast = 1m2
Pi ,j ci j .
• Burstinesscorrectedco-occurrences. Burstinessisthe
phenomenathat thefrequencyof anobservationissig-
nificantly larger thanastatistically independent model
wouldpredict. Thesquare-root functionisusedinim-
ageretrieval andclassificationtocorrect for burstiness
of visual features[10,24]. Similarly,weaimtoreduce
theburstinessinlabellings, anduse:
ssi j =
pci j , (4)
• TheDice’scoefficient,
sdi j =
ci j
ci + cj
, (5)
isameasureusedinmany Natural LanguageProcess-
ingsystems. It aimstoestimatethesemantic related-
nessbetweentwoterms, basedonhit countsfromweb
searchengines.
Definingaconcept bywhat it isnot. Thesimilaritiesde-
finedabove, arebasedonlyonpositiveco-occurrences, i.e.,
how often two labelsarerelevant for an image. However,
knowingwhat isnot relatedtotheconcept might beavery
informativeclueabout thevisual scopeof aconcept, which
isalsoshowninanimageretrieval setting[9].
In addition to the positive co-occurrences, denoted by
c++i j , wealsousetheother possibleco-occurrencerelations:
thepresenceof label i with theabsenceof label j , theab-
senceof label i withthepresenceof label j ,andtheabsence
of bothlabels, denotedbyc+–i j ,c–+
i j , andc––i j respectively. For
eachof thesedefinitionsof co-occurrenceweusethesimi-
larity measuresdefinedabove.
Using the positive and negative co-occurrences, the
weight vector wl of anunknownlabel canbeestimatedas:
wl =X
k
wk s++lk − wk s+–
lk − wk s–+lk + wk s––lk , (6)
Estimateco-occurrencefromwebdata. Sofar,wehave
not discussedhowtoobtaintheco-occurrencestatisticsre-
quired for our zero-shot recognition framework. To show
the potential of our framework, in most of the experi-
mentsweestimate label co-occurrences fromtheground-
truth labellingof our imagedatasets. Alternatively, theco-
occurrencestatisticscouldbeestimatedfromlargetext cor-
pora,e.g.,WordnetorWikipedia,or internet searchengines,
suchasYahoo, GoogleandBing.
3
Co-occurrencestatistics. Co-occurrences havebeen re-
peatedlyconsideredforcapturinghigherorder relationships
betweenclasses, conceptsandlabels. They havebeenused
to improve image segmentation [11], object detection [3,
22], to reasonabout what toexpect inascene[4, 14], and
for image and attribute classification [8, 15]. In general,
wenoticethat co-occurrencesof objects, labelsandtextures
havebeenrecognizedasastrongcluefor label andattribute
prediction. However, wearenot awareof any works that
uselabel co-occurrencestoenablezero-shot classification.
3. Zero-shot multi-label classification
In thissectionwedefineour zero-shot framework using
label co-occurrences. Wefirst introduceour co-occurrence
basedclassificationmethod. Second, inSection3.2wede-
scribearegressioninterpretationtoobtainzero-shot classi-
fier. Third, inSection3.3weillustratetheuseof thezero-
shot model asprior for few-shot classification.
3.1. Co-occurrencebasedclassification
Our goal is to estimate aclassification function for an
unseenlabel l,usingaset of existingclassifiers.Weassume
thatwehaveasetof linearclassifiers, trainedonacollection
of annotated imageswith k labels. Theseclassifierscould
beobtained frombinary SVMsor logistic regression, and
are represented by their weight vectorswk 2 Rd⇥1. We
assume, without lossof generality, that theweight vectors
areaugmentedsuchthat thebiasesareincluded.
Weproposetoestimatetheweight vector wl toclassify
theunseenlabel l, as
wl =X
k
wk slk, (1)
where slk represents a measure of similarity between the
known label k and the unseen label l. In this paper, we
base these similarities on the co-occurrence statistics be-
tweenthenewlabel andexistinglabels.
Co-occurrence similarities. We explore different simi-
larity measuresbased on theco-occurrenceof two labels.
Let ci j denotethetotal number of imagesfor whichlabel i
andlabel j arerelevant according toanauxiliary resource,
for exampletheground-truthlabelling,awebsearchengine
or auser providedinput inthecaseof activelearning. Also,
ci denotesthetotal number of imagesdepictinglabel i, and
m denotesthetotal number of labels. Thesimilaritieswe
exploreare:
• Normalizedco-occurrences,
sni j =
ci j
ci
, (2)
where the similarity is directly proportional to the
number of co-occurrences.
• Binarized co-occurrences, motivated by thebinarized
class-to-attributes mappings used in attribute-based
zeroshot classification[12, 28]:
sbi j = [[ci j ≥ t]], (3)
wheret isaglobal thresholdset ast = 1m2
Pi ,j ci j .
• Burstinesscorrectedco-occurrences. Burstinessisthe
phenomenathat thefrequencyof anobservationissig-
nificantly larger thanastatistically independent model
wouldpredict. Thesquare-root functionisusedinim-
ageretrieval andclassification tocorrect for burstiness
of visual features[10,24]. Similarly,weaimtoreduce
theburstinessinlabellings, anduse:
ssi j =
pci j , (4)
• TheDice’scoefficient,
sdi j =
ci j
ci + cj
, (5)
isameasureusedinmany Natural LanguageProcess-
ingsystems. It aimstoestimatethesemantic related-
nessbetweentwoterms, basedonhit countsfromweb
searchengines.
Definingaconcept bywhat it isnot. Thesimilaritiesde-
finedabove, arebasedonlyonpositiveco-occurrences, i.e.,
how often two labelsarerelevant for an image. However,
knowingwhat isnot relatedtotheconcept might beavery
informativeclueabout thevisual scopeof aconcept, which
isalsoshowninanimageretrieval setting[9].
In addition to the positive co-occurrences, denoted by
c++i j , wealsousetheother possibleco-occurrencerelations:
thepresenceof label i with theabsenceof label j , theab-
senceof label i withthepresenceof label j ,andtheabsence
of bothlabels, denotedbyc+–i j ,c–+
i j , andc––i j respectively. For
eachof thesedefinitionsof co-occurrenceweusethesimi-
larity measuresdefinedabove.
Using the positive and negative co-occurrences, the
weight vector wl of anunknownlabel canbeestimatedas:
wl =X
k
wk s++lk − wk s+–
lk − wk s–+lk + wk s––lk , (6)
Estimateco-occurrencefromwebdata. Sofar,wehave
not discussedhowtoobtaintheco-occurrencestatisticsre-
quired for our zero-shot recognition framework. To show
the potential of our framework, in most of the experi-
mentsweestimate label co-occurrences fromtheground-
truth labellingof our imagedatasets. Alternatively, theco-
occurrencestatisticscouldbeestimatedfromlargetext cor-
pora,e.g.,WordnetorWikipedia,or internet searchengines,
suchasYahoo, GoogleandBing.
3
Zero 2 4 8 16 32 64 128 All
25
30
35
40
45
Number of images
mA
P
iCLEF10
Data
Data+ Prior
Data+ WebPrior
Zero 2 4 8 16 32 64 128 All
10
15
20
Few Many
Number of images
mA
P
H-SUN
Zero 2 4 8 16 32 64 128 All
11
12
13
14
15
16
Number of images
mA
P
CUB-Att
Figure3. Few-shot classificationusingregressionbasedzero-shot prior fromground-truthor webhit-counts(except CUB-Att). Including
theprior significantly benefitsperformance, especially inthepresenceof very fewpositiveimages. Notethelog-scaleonthex-axis.
References
[1] Z.Akata,F.Perronnin, Z.Harchaoui, andC.Schmid. Label-
embeddingforattribute-basedclassification. InCVPR,2013.
2, 5
[2] E.Bart andS.Ullman. Cross-generalization: Learningnovel
classes from a single example by feature replacement. In
CVPR, 2005. 2
[3] G. Chen, Y. Ding, J. Xiao, andT. Han. Detectionevolution
withmulti-order contextual co-occurrence. InCVPR, 2013.
3
[4] M. Choi, J. Lim, A. Torralba, and A. Willsky. Exploiting
hierarchical context onalargedatabaseof object categories.
InCVPR, 2010. 3, 5
[5] M. Everingham, L. Van Gool, C. Williams, J. Winn, and
A. Zisserman. ThePascal visual object classes(VOC) chal-
lenge. IJCV, 2010. 2, 5
[6] R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C.-
J. Lin. Liblinear: A library for large linear classification.
JMLR, 2008. 4
[7] H. Grabner, J. Gall, andL. V. Gool. What makesachair a
chair? InCVPR, 2011. 1
[8] B. Hariharan, S. Vishwanathan, and M. Varma. Efficient
max-margin multi-label classification with applications to
zero-shot learning. MLJ, 2012. 3
[9] H. Jegou and O. Chum. Negative evidences and co-
occurrences in image retrieval: the benefit of PCA and
whitening. InECCV, 2012. 3
[10] H. Jegou, M. Douze, and C. Schmid. On theburstinessof
visual elements. InCVPR, 2009. 3
[11] L. Ladicky, C. R. P. Kohli, and P. Torr. Graph cut based
inferencewithco-occurrencestatistics. InECCV, 2010. 3
[12] C. Lampert, H. Nickisch, and S. Harmeling. Attribute-
based classification for zero-shot learning of object cate-
gories. IEEETrans. PAMI, 2013. 1, 2, 3, 6, 7
[13] F.-F. Li, R. Fergus, andP. Perona. One-shot learningof ob-
ject categories. IEEETrans. PAMI, 2006. 2
[14] T. MalisiewiczandA. Efros. Beyondcategories: thevisual
memex model for reasoning about object relationships. In
NIPS, 2009. 1, 3
[15] T.Mensink, J.Verbeek,andG.Csurka. Tree-structuredCRF
models for interactive image labeling. IEEE Trans. PAMI,
2012. 3, 5
[16] T. Mensink, J. Verbeek, F. Perronnin, and G. Csurka.
Distance-based image classification: Generalizing to new
classesat near-zerocost. IEEETrans. PAMI, 2013. 1, 2
[17] S.NowakandM.Huiskes. Newstrategiesfor imageannota-
tion: Overview of thephotoannotation task at ImageCLEF
2010. InWorkingNotesof CLEF, 2010. 5
[18] F. Orabona, C. Castellini, B. Caputo, A. E. Fiorilla, and
G. Sandini. Model adaptation with least-squares svm for
adaptivehandprosthetics. InIEEEICRA, 2009. 4
[19] M. Rastegari, A. Farhadi, andD. Forsyth. Attributediscov-
ery viapredictablediscriminativebinary codes. In ECCV,
2012. 2
[20] M. Rohrbach, M. Stark, andB. Schiele. Evaluatingknowl-
edgetransfer andzero-shot learning inalarge-scalesetting.
InCVPR, 2011. 1, 2
[21] M. Rohrbach, M. Stark, G. Szarvas, I. Gurevych, and
B. Schiele. What helpswhere–and why? semantic relat-
ednessfor knowledgetransfer. InCVPR, 2010. 2, 4, 6
[22] M. Sadeghi and A. Farhadi. Recognition using visual
phrases. InCVPR, 2011. 3
[23] R. Salakhutdinov, A. Torralba, andJ. Tenenbaum. Learning
tosharevisual appearancefor multiclassobject detection. In
CVPR, 2011. 2
[24] J. Sanchez, F. Perronnin, T. Mensink, and J. Verbeek. Im-
ageclassificationwiththefishervector: Theoryandpractice.
IJCV, 2013. 3, 4
[25] V.Sharmanska, N.Quadrianto, andC.Lampert. Augmented
attributerepresentations. InECCV, 2012. 2
[26] T. Tommasi and B. Caputo. Themoreyou know, the less
you learn: fromknowledgetransfer toone-shot learning of
object categories. InBMVC, 2009. 2
[27] T. Tommasi, F. Orabona, andB. Caputo. Safety innumbers:
Learning categories from few examples with multi model
knowledgetransfer. InCVPR, 2010. 4
[28] C.Wah, S.Branson, P.Welinder,P.Perona, andS.Belongie.
Thecaltech-ucsd birds-200-2011 dataset. Technical report,
Computation& Neural Systems, 2011. 1, 2, 3, 5
[29] J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba.
SUNdatabase: Large-scalescenerecognitionfromabbey to
zoo. InCVPR, 2010. 2, 5
8

COSTA: Classifier
• Goal: Estimate classifier for unseen label
• Knowledge base:
– k trained classifiers
– Co-occurrences
• Zero-shot classifier:
VOGIN-IP 201530

Co-Occurrence Statistics
• Ground-truth data (proof-of-concept)
• Web search engines
• Flickr Tags
• Language resources
• Visual annotated data (eg Microsoft COCO)
VOGIN-IP 201531
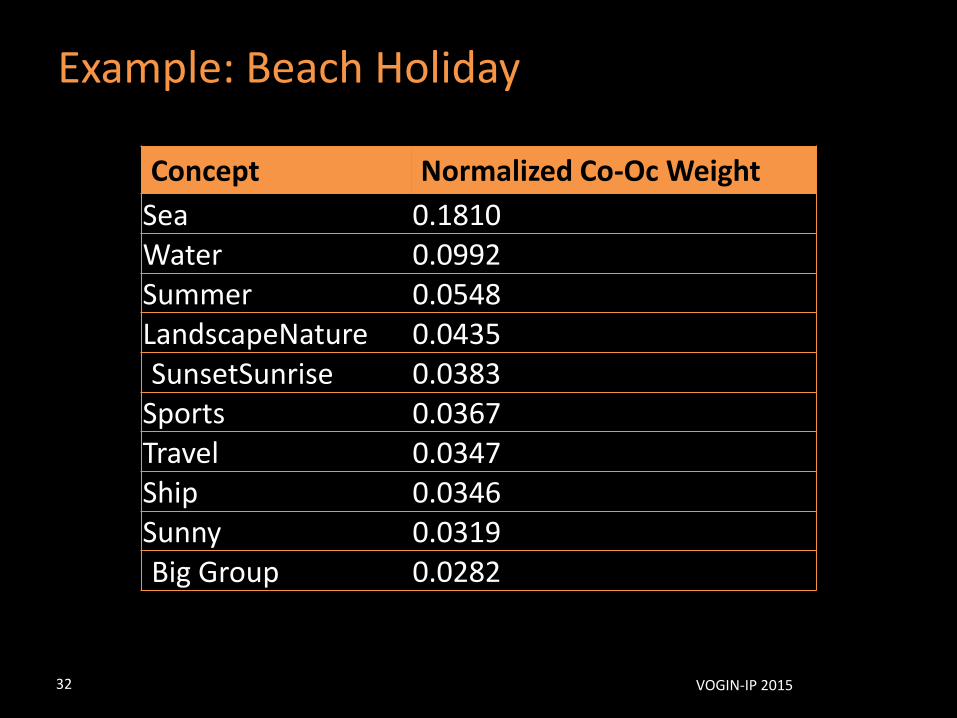
Example: Beach Holiday
VOGIN-IP 201532
Concept Normalized Co-Oc Weight
Sea 0.1810Water 0.0992Summer 0.0548LandscapeNature 0.0435SunsetSunrise 0.0383
Sports 0.0367Travel 0.0347Ship 0.0346Sunny 0.0319Big Group 0.0282

Example: Beach Holidays
VOGIN-IP 201533
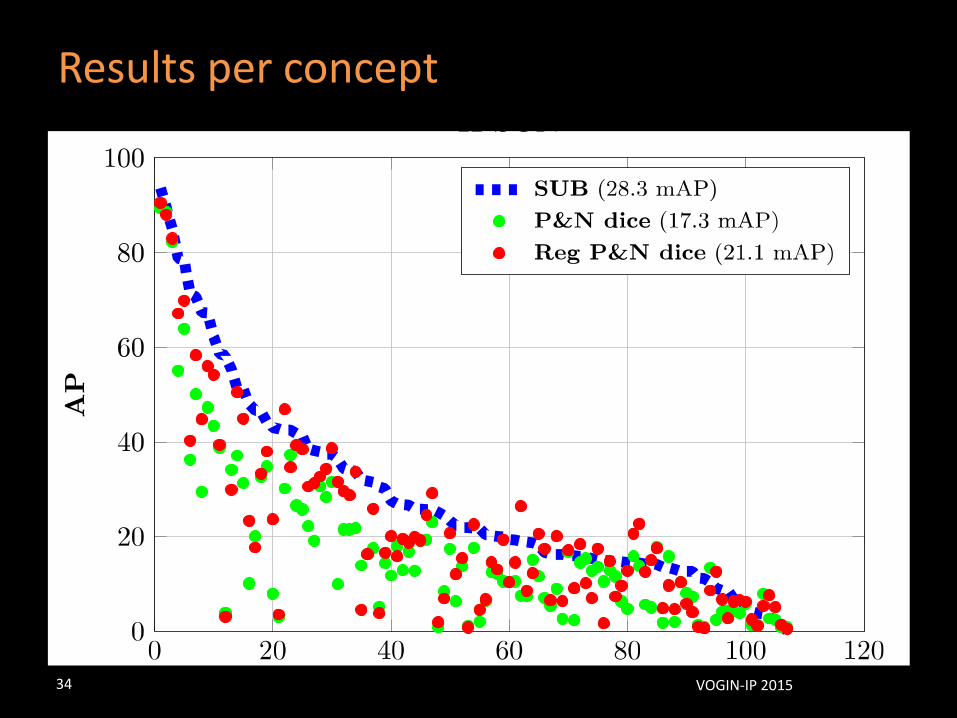
Results per concept
VOGIN-IP 201534

Co-occurrences from the Web
VOGIN-IP 201535

Conclusions
• Supervised visual classification performs well when ample train data is available
• Classification without examples:
– Define some set of base classifiers
– Transfer new class to space of these classifiers
– Two examples: attributes and co-occurrences
VOGIN-IP 201536

Thanks to:
• The organizers
• Christoph Lampert for slides and inspiration
• Authors of the cited papers
• Colleagues and supervisors (UvA: Amir, Cees, Jan, Spencer & Stratis, PhD: Cordelia, Florent, Gabriela, Jakob)
VOGIN-IP 201537

Literature
• Frome, Corrado, Shlens, Bengio, Dean, Ranzato,and Mikolov, “DeViSE: A Deep Visual-Semantic Embedding Model”, NIPS 2013
• Habibian, Mensink, and Snoek, “VideoStory: A New Multimedia Embedding for Few-Example Recognition and Translation of Events”, ACM MM 2014
• Lampert, Nickish, and Harmeling, “Attribute-Based Classification for Zero-Shot Learning of Object Categories”, TPAMI 2013
• Li, Gavves, Mensink, and Snoek, “Attributes Make Sense on Segmented Objects”, ECCV 2014
• Mensink, Gavves, and Snoek, “COSTA: Co-Occurrence Statistics for Zero-Shot Classification”, CVPR 2014
• Norouzi, Mikolov, Bengio, Singer, Shlens, Frome, Corrado, and Dean, “Zero-Shot Learning by Convex Combination of Semantic Embeddings”, ICLR 2014
VOGIN-IP 201538